在机器学习工程实践中,我们常常面临一个尴尬的存储困境:Hugging Face Hub 的模型和数据集仓库非常适合发布最终成果,却难以应对生产级训练中产生的海量中间文件。

训练过程中,检查点(Checkpoints)、优化器状态、已处理的数据分片、日志流、追踪记录等文件源源不断地产生。它们具有以下特征:
- 高频变动:文件内容随训练步数频繁更新;
- 并发写入:多个训练任务可能同时写入;
- 无需版本控制:过期的中间文件通常不需要保留历史版本。
强行将这些文件纳入基于 Git 的版本控制系统,不仅操作繁琐,还会导致仓库体积臃肿、同步缓慢。为了解决这一痛点,Hugging Face 正式推出了 Storage Buckets(存储桶)。
- 官方介绍:https://huggingface.co/blog/storage-buckets
什么是存储桶?
存储桶是 Hub 上新增的一种非版本化对象存储容器。它的设计灵感来源于 AWS S3 等云存储服务,但深度集成了 Hugging Face 的生态特性:
- 可变存储:支持快速写入、覆盖更新、删除过期文件,无需提交 commit;
- 无缝集成:位于用户或组织命名空间下,继承 Hub 标准的权限管理(公开/私有);
- 多端访问:既可以在浏览器中直接浏览,也可以通过 Python 脚本或
hf命令行工具进行编程管理; - 统一句柄:通过
hf://buckets/username/my-bucket这样的路径即可像访问本地文件一样访问云端数据。
核心引擎:为什么是 Xet?
存储桶并非简单的对象存储封装,其底层由 Xet 驱动。这是 Hugging Face 自研的基于分块(Chunk-based)的存储后端,也是其高效性的秘密武器。
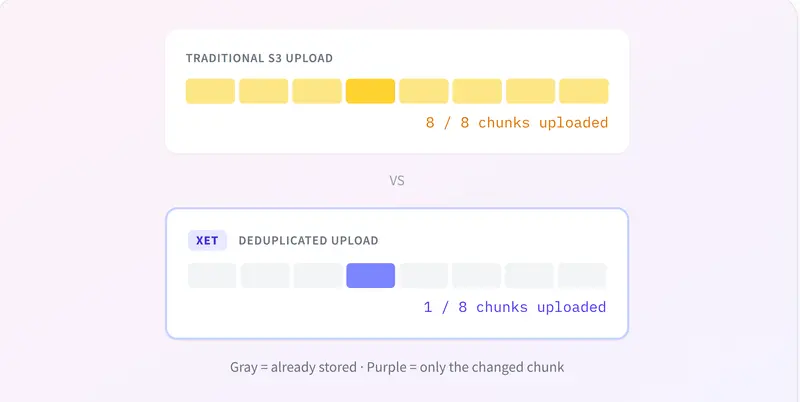
传统的对象存储将文件视为完整的 Blob,而 Xet 会将文件内容拆解为细小的数据块,并在块级别进行全局去重。这一机制对机器学习工作负载极具价值:
- 增量更新极快:当你上传一个新的训练检查点时,如果模型大部分参数未变,Xet 只需上传发生变化的那些数据块。
- 数据处理省力:对原始数据集进行微调处理后再次上传,大量重复的数据块会被自动识别并跳过。
- 成本与带宽双降:由于只传输和存储唯一的数据块,带宽占用显著降低。对于企业客户,计费基于去重后的实际存储量,共享块越多,成本越低。
关键特性:数据预热(Data Warm-up)
在分布式训练和大规模流水线中,数据存储的地理位置直接影响吞吐量。如果计算节点在 AWS 美东区域,而数据存储在 Hub 的默认全球节点,跨区域拉取数据将带来显著的延迟。
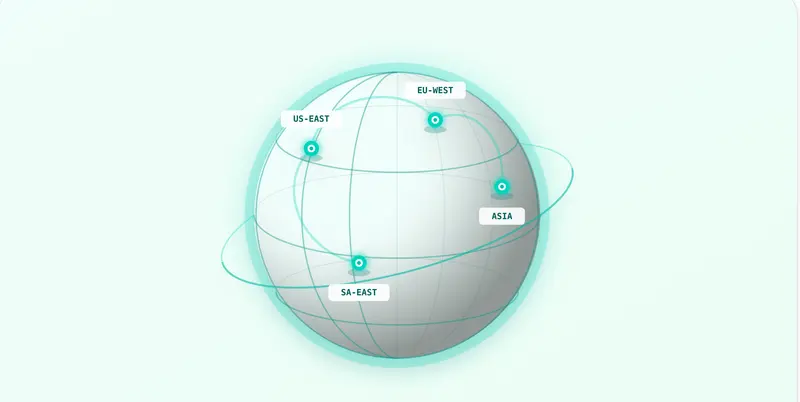
存储桶引入了**预热(Warm-up)**机制:
- 按需分布:你可以声明需要将数据预热到特定的云提供商(如 AWS、GCP)和区域。
- 就近计算:系统会在你的训练作业启动前,自动将热数据复制到离计算资源最近的节点。
- 消除瓶颈:避免了训练过程中因网络延迟导致的 I/O 等待,特别适合多区域协作和超大规模集群训练。
目前该功能已支持 AWS 和 GCP,未来将扩展至更多云厂商。
快速上手:命令行与 Python 集成
1. 命令行工具(CLI)
使用 hf 命令行工具,你可以在几分钟内完成存储桶的创建与同步:
# 安装并登录
curl -LsSf https://hf.co/cli/install.sh | bash
hf auth login
# 创建私有存储桶
hf buckets create my-training-bucket --private
# 同步本地检查点到存储桶
hf buckets sync ./checkpoints hf://buckets/username/my-training-bucket/checkpoints
# 预演同步计划(不执行实际操作)
hf buckets sync ./checkpoints hf://buckets/username/my-training-bucket/checkpoints --dry-run
# 查看存储桶内容
hf buckets list username/my-training-bucket -h
2. Python 原生支持
从 huggingface_hub v1.5.0 开始,存储桶操作已完全融入 Python API,方便嵌入训练脚本或数据流水线:
from huggingface_hub import create_bucket, sync_bucket, list_bucket_tree
# 创建存储桶
create_bucket("my-training-bucket", private=True, exist_ok=True)
# 同步数据
sync_bucket("./checkpoints", "hf://buckets/username/my-training-bucket/checkpoints")
# 遍历文件
for item in list_bucket_tree("username/my-training-bucket", prefix="checkpoints", recursive=True):
print(f"{item.path}: {item.size} bytes")
此外,JavaScript 开发者也可通过 @huggingface/hub (v2.10.5+) 在 Node.js 或 Web 应用中使用相同功能。
深度集成:兼容 fsspec 文件系统
对于数据科学家而言,最友好的集成方式是无需修改现有代码。存储桶完美兼容 Python 的 fsspec 标准接口,通过 HfFileSystem 实现透明访问。
这意味着,任何支持 fsspec 的库(如 Pandas, Polars, Dask)都可以直接读写存储桶中的数据,就像操作本地文件一样:
import pandas as pd
from huggingface_hub import hffs
# 直接使用 hf:// 路径读取 CSV
df = pd.read_csv("hf://buckets/username/my-training-bucket/results.csv")
# 执行分析后直接写回
df.to_csv("hf://buckets/username/my-training-bucket/summary.csv")
# 使用 glob 匹配文件
files = hffs.glob("buckets/username/my-training-bucket/**/*.parquet")
这种设计极大地降低了迁移成本,让存储桶能够无缝插入现有的数据处理工作流中。
完整工作流:从动态存储到版本发布
存储桶的定位非常清晰:它是工件在“动态阶段”的暂存区,而非最终归宿。
理想的机器学习工程流应当是分离的:
- 工作层(存储桶):存放频繁变动的检查点、日志、中间数据。利用其高吞吐、低成本、免版本的特性。
- 发布层(Repository):当模型训练完成或数据集处理完毕,将最终稳定的工件从存储桶提升至版本化的 Model 或 Dataset 仓库。
Hugging Face 计划在路线图中支持存储桶与仓库之间的双向一键传输,进一步打通从“实验”到“发布”的最后一公里,形成闭环的 Hub 原生工作流。
结语
Storage Buckets 的推出,补齐了 Hugging Face Hub 在高吞吐、可变数据存储领域的短板。
对于个人开发者,它提供了一个比 Git 更轻便、比 S3 更懂 AI 的免费存储方案;对于企业团队,基于 Xet 的去重技术和数据预热能力,意味着更低的存储成本和更高的训练效率。
目前,存储桶功能已包含在现有的 Hub 存储计划中。免费账户即可体验基础额度,PRO 和企业用户可享受更高配额。随着 Jasper、Arcee、IBM 等早期合作伙伴的验证反馈,这一功能已准备好迎接大规模的机器学习工程挑战。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...