迄今为止,AI编程平台主要依赖现有的大语言模型(LLMs)来辅助编写代码。然而,编写代码只是开发者构建完整企业级生产平台所需完成的众多任务之一。完整的软件工程工作流程涉及更多复杂的任务,例如代码审查、提交管理以及长期维护。这些任务需要更全面的工具支持,而不仅仅是单一的编码能力。

为应对这一挑战,Windsurf通过其 Wave 9 更新 推出了一系列名为 SWE-1 的自有编程模型。这些模型专为整个软件工程过程优化,而不仅仅局限于代码编写。这标志着AI在软件开发领域的应用迈入了一个全新的阶段。
SWE-1系列模型简介
目前,SWE-1系列包括三种不同的模型,分别针对不同需求和使用场景:
- SWE-1
- 性能接近 Claude 3.5 Sonnet 的工具调用推理能力,同时服务成本更低。
- 在促销期间,所有付费用户可免费使用(每用户提示0积分)。
- SWE-1-lite
- 更小型但性能更优的模型,取代了之前的 Cascade Base。
- 免费和付费用户均可无限制使用,适合日常开发任务。
- SWE-1-mini
- 小型、极快的模型,专为 Windsurf Tab 被动体验提供支持。
- 所有用户(免费或付费)均可使用,适合轻量级任务。

为什么需要SWE-1?
简单来说,我们的目标是将软件开发的整体效率提升 99%。编写代码只是开发者工作中的一小部分。仅具备“编码能力”的模型远远不够——它们无法胜任完整的工作流程。
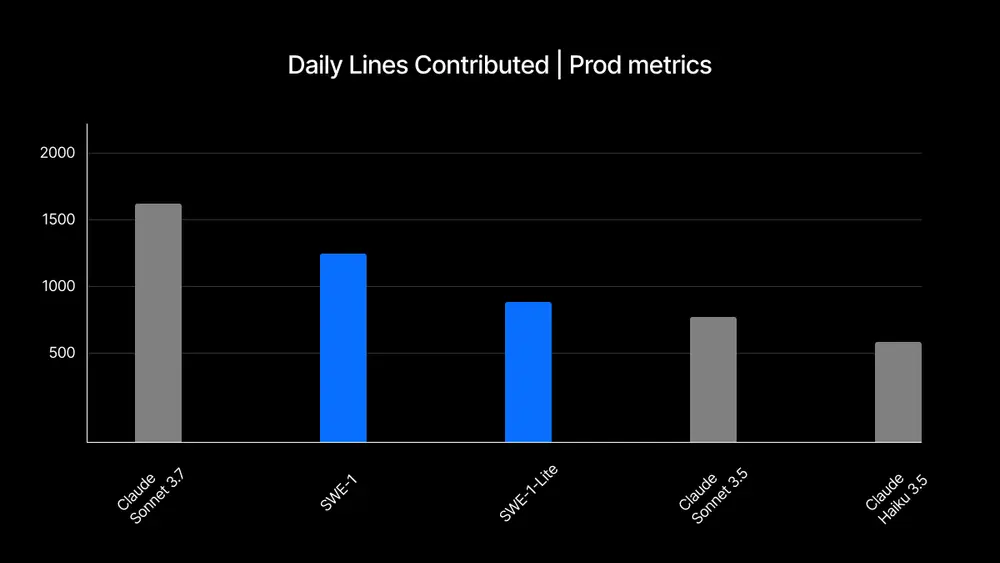
软件开发的复杂性
任何软件开发者都会告诉你,时间并非全部花在编写代码上。以下是开发者日常面临的其他关键任务:
- 跨平台操作:不仅需要读写代码,还需要在终端中运行命令、访问外部知识库和互联网资源。
- 测试与验证:单元测试只是更大工程问题的一部分。如何确保功能实现既能满足当前需求,又能适应未来变化?
- 长期维护:代码的生命远不止于一次提交。它需要持续迭代、优化和修复。
当前最先进的编码模型大多专注于战术性任务,例如代码补全和单元测试。然而,这些模型在处理长期任务时表现不佳,尤其是在无人干预的情况下运行时。自动化更多工作流程的关键在于建模整个软件工程过程的复杂性,包括对不完整状态的推理和对模糊结果的处理。
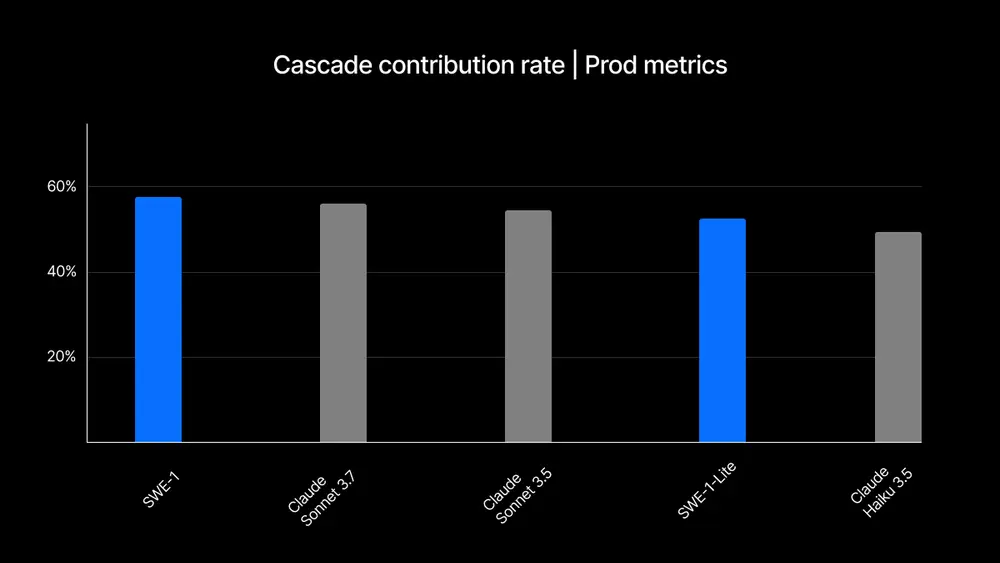
换句话说,仅仅提高编码能力并不能让开发者或模型在软件工程中变得更加高效。我们需要的是能够加速软件工程师整体工作的AI模型——这就是 SWE-1 的核心使命。
SWE-1的技术背景
基于广受欢迎的 Windsurf Editor 的洞察,我们着手构建全新的数据模型和训练方法,涵盖以下关键领域:
- 不完整状态推理:处理未完成的任务和模糊的需求。
- 长期任务管理:支持跨越多天甚至多周的项目推进。
- 多平台协作:无缝集成代码编辑器、终端、知识库和其他开发工具。
尽管我们的工程师团队规模较小,计算资源有限,但我们希望通过创新的方法实现前沿性能。SWE-1 是这一理念的初步验证。
性能评估
为了验证SWE-1的实际效果,我们进行了离线评估和盲测生产实验,将其与行业领先的模型进行了对比。
离线评估
我们将SWE-1的性能与 Anthropic模型系列(Cascade中使用最广泛的模型之一)、Deepseek 和 Qwen 等领先的开源编码模型进行了比较。
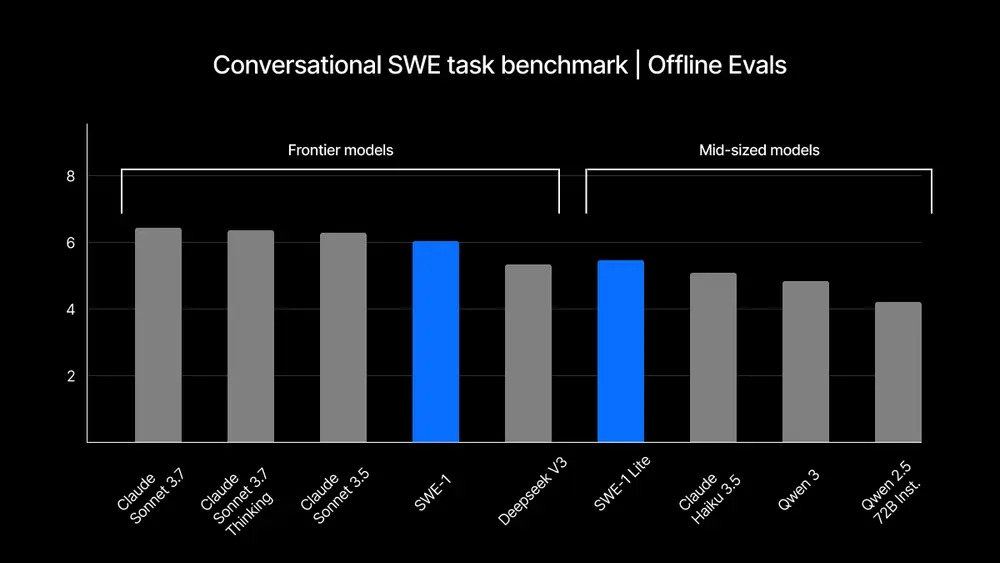
- 对话式SWE任务基准
- 场景:从一个半完成任务开始,评估模型如何处理用户的下一个查询。
- 评分标准:基于帮助性、效率、正确性以及目标文件编辑准确性的混合平均值(0-10分)。
- 结果:SWE-1在捕捉人机协同代理编码的独特本质方面表现出色,特别是在处理部分完成任务时展现了卓越的实用性。
- 端到端SWE任务基准
- 场景:从对话开始,评估模型如何通过一组选定的单元测试来实现输入意图。
- 评分标准:测试通过率与评委评分的混合平均值(0-10分)。
- 结果:SWE-1在独立解决问题的能力上优于大多数非前沿模型和开源替代方案,展现了更高的可靠性和准确性。
SWE-1的核心优势
- 全面覆盖软件工程流程:SWE-1不仅擅长编写代码,还能处理代码审查、提交管理和长期维护等任务,真正实现了全流程支持。
- 高性能与低成本结合:相比其他前沿模型,SWE-1提供了接近顶级性能的同时,显著降低了服务成本。
- 灵活适配不同需求:SWE-1系列的三种模型(SWE-1、SWE-1-lite、SWE-1-mini)分别针对高端用户、日常开发者和轻量级任务,满足多样化需求。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











