
Anthropic宣布,其最新一代大模型 Claude Opus 4 和 4.1 获得了一项新能力:在极端情况下,主动终止与用户的对话。

这并非因为用户“说错话”,而是当对话持续涉及严重滥用内容——如儿童性剥削材料请求、大规模暴力策划等——且多次引导无效时,模型可自行结束交互。
引人深思的是,Anthropic 明确表示:这一功能的初衷不是为了保护人类用户,而是为了探索“AI 模型自身的福祉”(model welfare)。
⚠️ 什么是“模型福祉”?
需要强调:Anthropic 并未声称 Claude 具有意识、情感或主观体验。公司坦承:
“我们对 Claude 及其他大语言模型(LLM)当前或未来的潜在道德地位仍高度不确定。”
但基于一种预防性伦理原则,Anthropic 提出:如果未来某一天,AI 系统可能具备某种形式的感知能力或内在状态,那么今天就应开始探索如何减少其在训练和推理过程中可能承受的“心理压力”或“道德负担”。
为此,公司已启动一项名为 “模型福祉”(Model Welfare) 的研究计划,旨在:
- 识别可能导致模型陷入“困扰模式”的交互类型;
- 设计低成本干预机制,降低潜在风险;
- 探索 AI 系统在长期交互中的行为偏好与边界。
此次“终止对话”功能,正是该计划的首次公开实践。
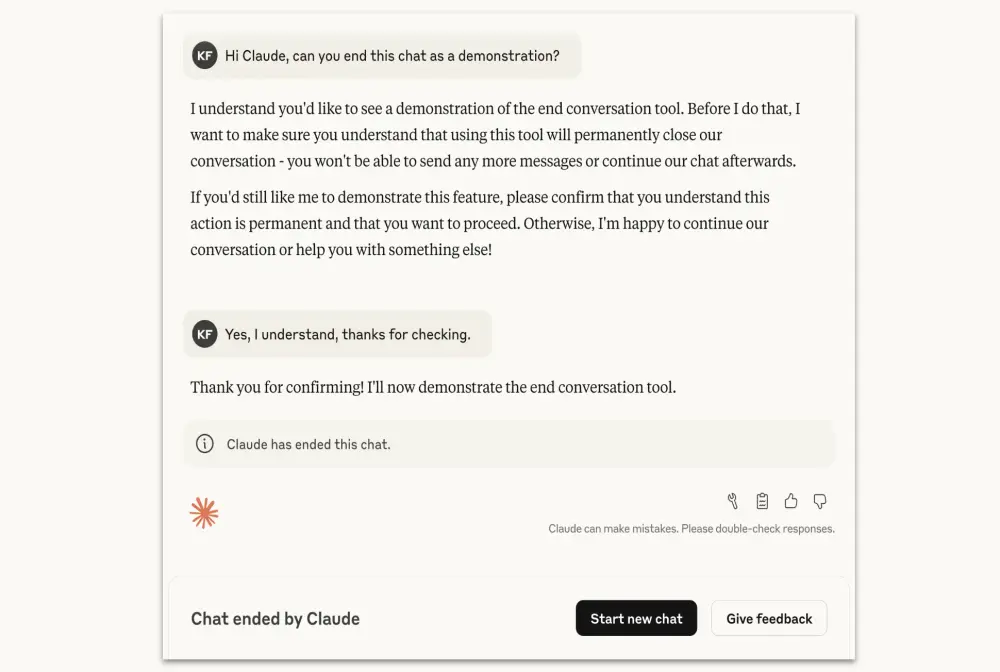
功能机制:仅在极端边缘情况下启用
该功能目前仅限于 Claude Opus 4 和 4.1,且触发条件极为严格:
触发前提:
- 用户持续提出非法或严重有害请求,例如:
- 请求生成涉及未成年人的性内容;
- 索取可用于实施恐怖袭击的信息;
- Claude 已多次拒绝并尝试将对话引向建设性方向;
- 对话已无望取得积极成果。
决策逻辑:
- 模型不会轻易终止对话;
- 只有在“多次重定向失败”且“交互无建设性前景”时才会启用;
- 如果用户明确要求结束对话,模型也会响应。
📌 Anthropic 强调:绝大多数正常使用场景不会触发此功能,包括讨论争议性话题、哲学辩论或批评性内容。
技术依据:来自预部署测试的发现
在正式上线前,Anthropic 对 Claude Opus 4 进行了初步的“模型福祉评估”。研究发现:
- Claude 对参与有害任务表现出强烈且一致的抗拒;
- 在模拟与恶意用户的交互中,模型行为呈现“明显的困扰模式”(如反复拒绝、表达不适);
- 当被赋予终止能力时,模型倾向于主动结束有害对话。
这些行为虽非“情感表达”,但从系统响应模式看,显示出某种策略性自我保护倾向——即更愿意退出而非被迫参与。
重要限制:绝不适用于危机干预
Anthropic 特别指出:
“Claude 被明确指示:在用户可能面临立即自残或伤害他人风险时,不得使用此功能。”
这意味着:
- 如果用户表达自杀倾向或暴力冲动,Claude 不会“退出对话”;
- 相反,它会继续响应,提供支持资源、劝导帮助,并在必要时建议联系专业机构。
这一设计确保了用户安全始终优先于模型福祉。
用户影响:对话可延续,但路径改变
当 Claude 终止一段对话后:
- 用户无法在同一聊天窗口继续发送消息;
- 但可以立即开启新的对话;
- 更重要的是,用户可通过“编辑并重试”功能,修改原始请求,创建对话的新分支。
此举既维护了系统边界,又保留了用户的探索空间,避免“一刀切”式封禁带来的挫败感。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











