谷歌TPU打破垄断!拟向Meta开放租用+采购,剑指英伟达10%数据中心营收据路透社援引The Information报道,谷歌与Meta正就AI芯片合作展开深度谈判,拟达成一项价值数十亿美元的协议:Meta计划2026年先租用谷歌云的张量处理单元(TPU),2027年进一步...早报# Meta# TPU# 谷歌4个月前0430
Meta 开源 Omnilingual ASR:支持 1600+ 语言的语音识别系统Meta AI 近日发布了 Omnilingual ASR——一套开源、可扩展的多语言自动语音识别(ASR)系统,支持 1600 多种语言,并能通过零样本上下文学习泛化到 超过 5400 种语言,包括...语音模型# Meta# Omnilingual ASR# 语音识别5个月前01240
杨立昆拟离职Meta,计划创办专注“世界模型”的AI公司据《金融时报》援引知情人士消息,Meta首席人工智能科学家杨立昆(Yann LeCun)正计划离开公司,创办一家专注于“世界模型”(world models)研究的AI初创企业。目前,相关融资谈判处于...百科# Meta# 杨立昆5个月前0220
Meta 在欧洲推出 AI 生成视频Vibes,聚焦创作与 remixMeta 于本周四宣布,其 AI 生成视频功能 Vibes 正式在欧洲地区上线,作为 Meta AI 应用的一部分。 Vibes 是一个独立的短视频内容流,所有视频均由 AI 生成,用户可浏览、创作...早报# Meta# Vibes5个月前01020
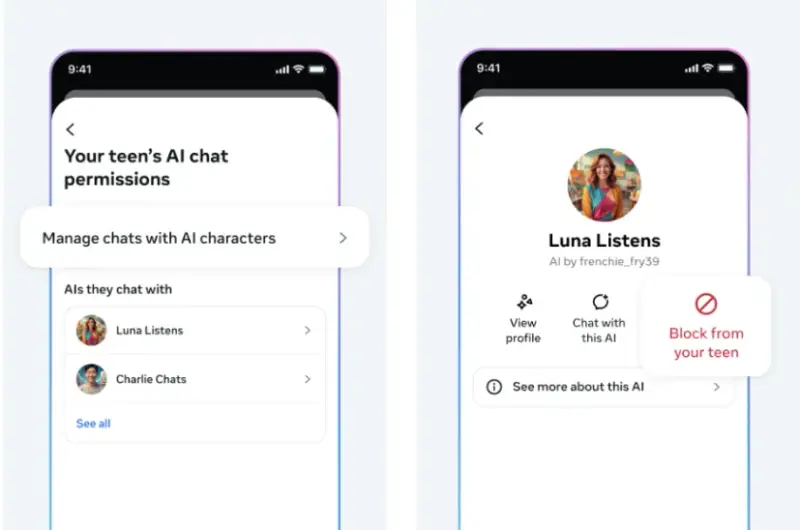
Meta 为 Instagram 青少年用户新增 AI 聊天限制,家长可完全禁用Meta 近日宣布,将于 2025 年初在 Instagram 上推出针对青少年用户的 AI 聊天控制功能,允许家长对其子女与 AI 角色的互动进行管理。该功能目前仅面向 美国、英国、加拿大和澳大利亚...早报# Instagram# Meta6个月前0480
Meta与Arm合作扩展AI业务,AI 推理系统将迁移至 Arm Neoverse 平台Meta 正在将其核心 AI 系统——包括内容推荐、排名算法等——迁移至 Arm Neoverse 云端计算平台。这一合作标志着 Arm 首次深度参与超大规模社交平台的 AI 基础设施,也凸显 Met...早报# Arm# Meta6个月前0540
Meta 将用 AI 聊天记录个性化推荐内容,12 月 16 日起生效Meta 正计划扩展其广告与内容推荐系统:从 12 月 16 日起,你在 Facebook、Instagram、WhatsApp 或 Messenger 中与 Meta AI 助手 的文本和语音对话...早报# AI 聊天记录# Meta6个月前01160
Meta 推出 Vibes:一个用于 AI 生成短视频的动态创作平台Meta 正在测试一项名为 Vibes 的新功能,这是一个基于 AI 的短视频创作工具,目前已在 Meta AI 应用和 meta.ai 网页端向部分用户开放预览。它允许用户创建、自定义并分享由AI生...早报# Meta# Vibes6个月前02790
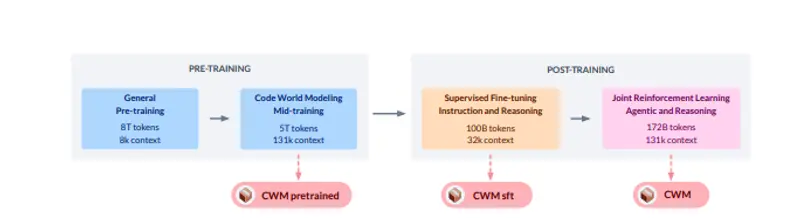
Meta 开源代码世界模型CWM:让AI像程序员一样"推演"代码的世界模型Meta近日发布并开源代码世界模型(Code World Model, CWM),这是一款320亿参数的仅解码器大型语言模型(LLM),支持最长131k tokens的上下文长度。不同于传统代码模型仅...大语言模型# CWM# Meta# 代码世界模型6个月前02380
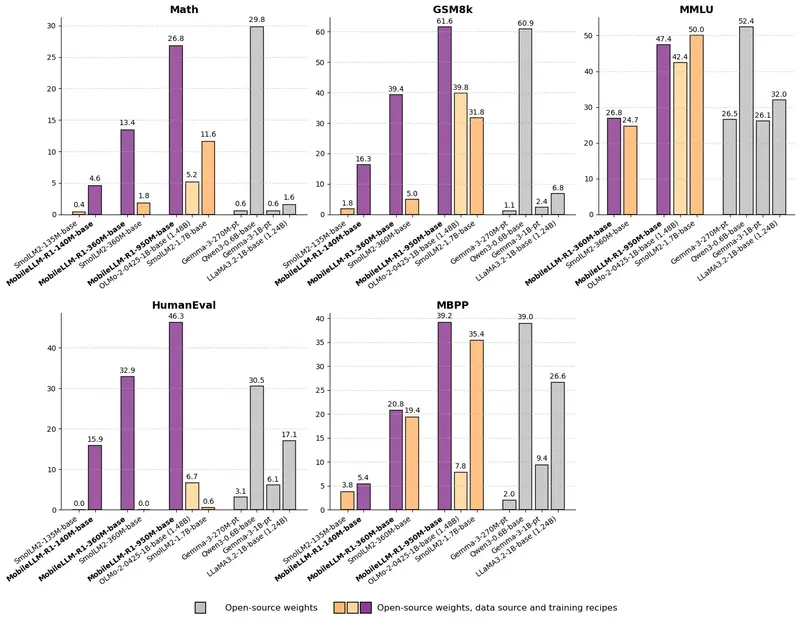
Meta 发布MobileLLM-R1 系列模型:专为数学、编程(Python/C++)和科学推理任务设计Meta 正式发布 MobileLLM-R1 系列模型,包含 140M、360M 和 950M 三款尺寸,专为数学、编程(Python/C++)和科学推理任务设计。它不是通用聊天模型,而是一个经过精细...大语言模型# Meta# MobileLLM-R17个月前02890
Meta 143亿美元押注Scale AI遇挫:高管离职、转向竞品,超级智能实验室陷混乱6月,Meta曾以143亿美元大手笔投资数据标注巨头Scale AI,并将其CEO亚历山大·王(Alexandr Wang)及多名高管纳入旗下Meta超级智能实验室(MSL),试图加速AI超级智能研发...早报# Meta# Scale AI7个月前01030
扎克伯格的AI野心引发Meta震荡:新老势力碰撞、重组不断,离职潮暗流涌动为实现“个人超级智能”的AI野心,Meta CEO马克·扎克伯格正推动公司二十年来最剧烈的领导层重组。这场以“砸钱抢人”为起点的变革,却引发了一系列连锁反应:新聘AI高管威胁离职、资深员工批量出走、内...早报# Meta# 扎克伯格7个月前0950