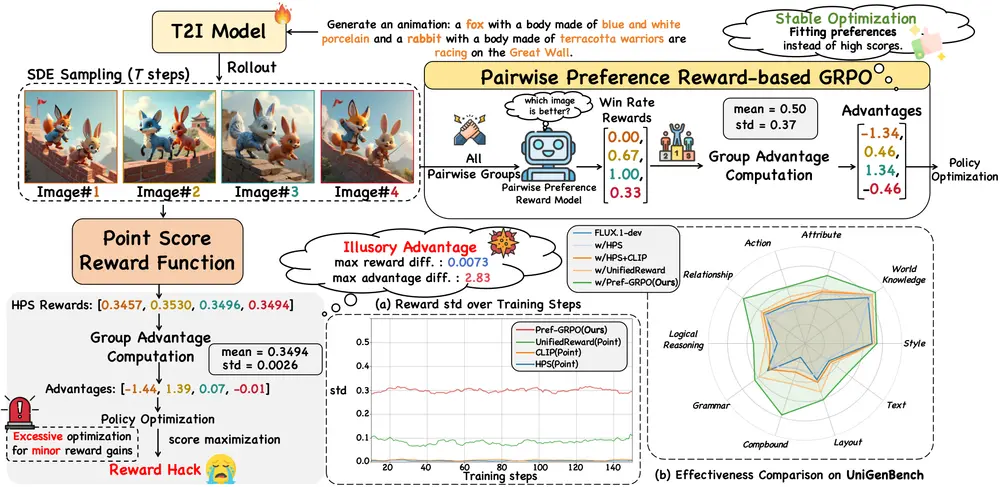
复旦等团队联合突破文生图模型生成瓶颈:Pref-GRPO解决奖励操控,UniGenBench补上评估短板文本到图像(T2I)生成技术的进步,离不开强化学习方法的优化与基准测试的支撑。但当前领域存在两大核心问题:一是传统强化学习依赖“点式奖励模型”打分,易出现“分数涨而质量降”的奖励操控现象;二是现有基准...图像模型# Pref-GRPO# 文生图模型7个月前03370
文生图模型SnapGen:能够在移动平台上生成高分辨率和高品质的图像现有的文本到图像(T2I)扩散模型虽然在生成高质量图像方面表现出色,但面临着几个关键挑战: 模型尺寸大:许多先进的T2I模型包含数十亿个参数,导致存储和部署成本高昂。 运行时间慢:生成高分辨率图像通常...新技术# SnapGen# 文生图模型1年前03260
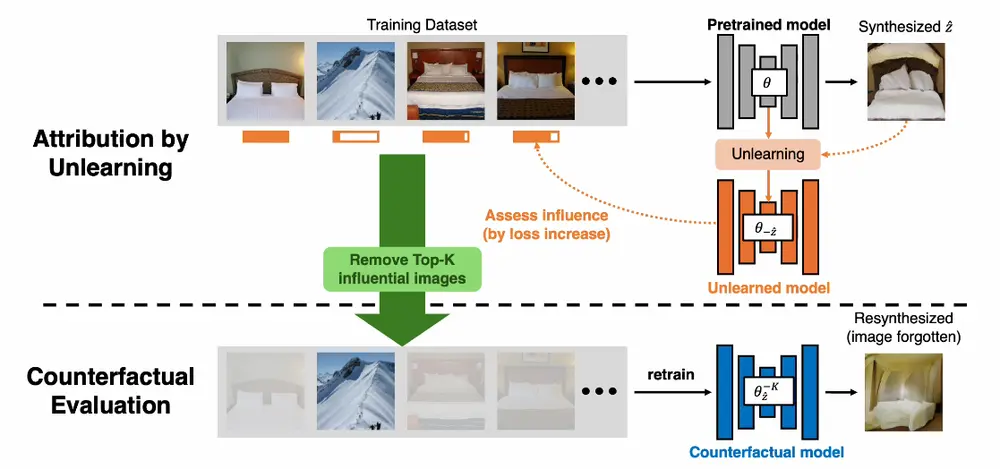
文本到图像模型的数据归因:识别在生成新图像过程中最具影响力的训练图像卡内基梅隆大学、Adobe 研究和加州大学伯克利分校的研究人员发布论文,论文的主题是关于文本到图像模型的数据归因(Data Attribution for Text-to-Image Models...新技术# 文生图模型1年前03170
SWITTI:用于文本到图像合成的新型规模感知变换器模型Yandex Research、HSE 大学、MIPT 和 Skoltech 的研究人员提出了 Switti,这是一个专门设计用于文本到图像(T2I)生成的尺度变换器。Switti 从现有的下一尺度预...图像模型# SWITTI# 文生图模型1年前03140
阿里开源Ovis-Image:7B 参数实现高质量文本渲染的文生图模型,海报 / UI 设计秒生成Ovis-Image 是由阿里巴巴国际数字商务团队开发的 70亿参数 文本到图像(Text-to-Image)生成模型,专注于解决文生图系统中长期存在的文本模糊、拼写错误、排版失真等痛点。该模型在保持...图像模型# Ovis-Image# 文生图模型4个月前02690
BRIA 发布 FIBO:用 JSON 精确控制光线、构图与相机参数的文生图模型BRIA 开源发布了其首个文本到图像模型 FIBO —— 一个专为专业图像生成工作流设计的 JSON 原生、结构化提示驱动 的开源模型。与主流强调“想象力”的生成模型不同,FIBO 的核心目标是 可控...图像模型# BRIA# FIBO# 文生图模型5个月前01170
阿里发布文生图模型Qwen-Image-2512:人像、纹理、文字渲染显著提升2025 年 12 月 31 日,阿里 Qwen 项目组发布了 Qwen-Image-2512 —— Qwen-Image 文生图基础模型的最新版本。这是继今年 8 月首次开源 Qwen-Image ...图像模型# Qwen-Image-2512# 文生图模型3个月前0430