Qwen-Image-2512-Turbo-LoRA-2-Steps 由 Wuli 团队训练的 两步加速版 LoRA,适用于 Qwen Image 2512,相比Wuli 之前的 四步加速版 LoRA 有所改进。
Nunchaku-Qwen-Image-EDIT-2511/Nunchaku-Qwen-Image-2512 官方 Nunchaku 推理引擎 本以高效量化著称,能显著降低显存占用,但近期对阿里新发布的 Qwen-Image-2512 和 Qwen-Image-EDIT-2511 尚未提供官方支持。 好消息是:社区开发者 QuantFunc 已率先完成量化适配,并发布了两个系列的 4-bit 模型,现已可在 ComfyUI 中直接使用。
Qwen-Image-2512-Turbo-LoRA Qwen-Image-2512-Turbo-LoRA 是由呜里团队训练的一个 4 步快速 LoRA,基于 Qwen-Image-2512 模型。该 LoRA 在保持原模型输出质量的同时,推理速度提升了 20 倍以上
VestalWater's Illustrious Styles for Qwen Image VestalWater's Illustrious Styles for Qwen Image 是一次对 AI 图像美学方向的主动选择——它不迎合大众审美趋势,而是服务于特定创作者群体的需求:那些希望摆脱“AI塑料感”、追求更具手绘质感与专业实用性的用户。
Raena-Qwen-Image Raena-Qwen-Image 是一个为 Qwen-Image 微调的 LoRA,专为动漫风格生成设计。该模型的目标是增强 Qwen-Image 在生成高质量动漫输出的能力,具有更清晰的细节、更丰富的色彩和更好的美学效果。
Qwen-Image-Edit-InStyle Qwen-Image-Edit-InStyle 是对 Qwen-Image-Edit 模型在风格迁移能力上的一次重要增强。 它让原本“泛化有余、精准不足”的风格迁移,变得可预测、可控制、可复用,特别适用于: 艺术创作中的风格探索、品牌视觉统一性生成、游戏与动画概念设计、个性化内容生成。
PJ0 QwenImage Realistic FP8 PJ0 QwenImage Realistic FP8 是一次针对性明确的优化迭代,重点提升真实感与细节表现力。结合合理的参数设置,尤其在低 CFG 与优质采样器配合下,能够稳定输出接近专业摄影水准的图像结果,适合写实风格创作者纳入工作流程。
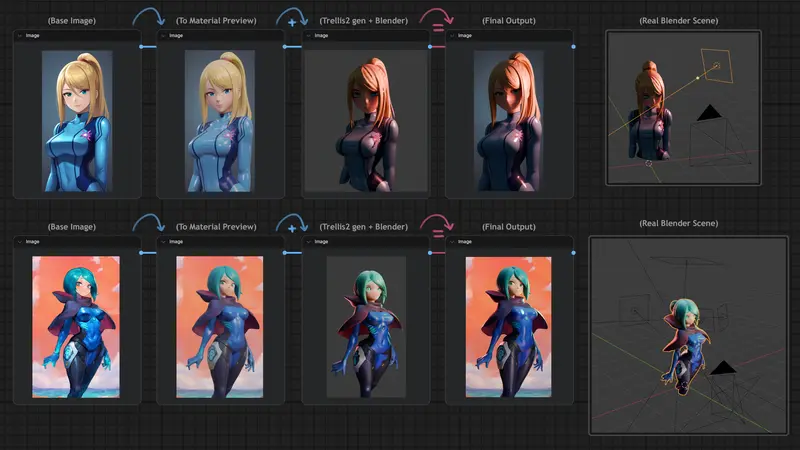
Qwen_Image_4_Grid_Display_Lora Qwen_Image_4_Grid_Display_LoRA 是一款基于 Qwen-Image 模型微调的 LoRA 适配器,专为生成四格统一视觉风格图像而设计。它能够将一个抽象创意或设计概念,一次性输出为四个在色彩、构图、视角和主题上高度一致的图像,形成一个完整的视觉网格,极大提升设计探索与原型迭代的效率。
AWPortrait-QW AWPortrait QW 是基于QwenImage架构下的模型,使用更符合中国人长相特征及审美的训练集进行训练,包含室内室外人像、时尚、棚拍写真等众多类型,泛化性强。相较于原始版Qwen,AWPortrait QW对于肤质表现更加细腻且真实,LoRA建议权重1。
Qwen-Image Realism Qwen-Image Realism LoRA v1.1 是一次聚焦“真实感”的精准升级。它不追求参数膨胀或复杂架构,而是通过高质量数据与精细微调,在面部、色彩、光影和多样性四个关键维度实现可感知的提升。
Qwen-Image-EliGen Qwen-Image-EliGen是基于 Qwen-Image 训练的精确分区控制模型,模型结构为 LoRA,可以通过输入每个实体的文本和区域条件(蒙版图)来控制每个实体的位置和形状。
QIE-2509-Object-Remover-Bbox QIE-2509-Object-Remover-Bbox 是为 Qwen-Image-Edit-2509 开发的一个 LoRA,使用边界框引导精确地从图像中移除不需要的物体。
Qwen-Edit-2511_LightingRemap_Alpha0.2 基于 Qwen-Edit-2511 模型训练的 Alpha 版本 LORA,专为实现 “色块引导式图像重打光” 而设计。该 LORA 能够根据图像中特定颜色的色块位置与颜色,智能地对人物或场景进行光影重构与氛围渲染,同时自动移除色块本身,生成自然、高质感的光照效果。
QIE-2511-MP-AnyLight 开发者lilylilith打造了 QIE-2511-MP-AnyLight这款LoRA ,旨在提供一种半实时、基于 3D 参考的光线迁移能力,让创作者能更可靠地实现预期照明效果。
Qwen-Image-Edit-2511-Unblur-Upscale Qwen-Image-Edit-2511-Unblur-Upscale是一个为 Qwen-Image-Edit-2511 图像到图像模型开发的实验性 LoRA,专门用于从部分模糊的图像中恢复面部特征模式,并将其提升至高分辨率。
Qwen-Image-Edit-2511-Multiple-Angles-LoRA Qwen-Image-Edit-2511-Multiple-Angles-LoRA是首个专为 Qwen-Image-Edit-2511 设计的多角度相机控制 LoRA,通过精细的 3D 视角参数,实现对生成图像视角的精确控制。无论你需要低角度仰拍、标准平视,还是高空俯瞰,只需一条提示词即可指定。
Anything2Real Anything2Real LoRA,基于阿里最新 Qwen Edit 2511(mmdit 编辑模型) 构建,专为非写实图像到写实照片的风格迁移而设计。无论是二次元角色、儿童绘本、概念草图,还是抽象绘画,它都能在不破坏内容结构的前提下,生成具有摄影质感的输出。
AnyPose AnyPose专为 Qwen Image Edit 2511 Lightning LoRA 设计,无需 ControlNet,无需骨骼图,仅凭一张参考图 + 简单提示词,即可让目标角色精准复刻任意姿势。
Pose Transfer Pose Transfer 是一个专为图像编辑任务设计的 LoRA 微调模型,基于 Qwen Image Edit 架构训练而成,旨在实现高质量的人物姿势迁移——即将源图像中的人物姿态,迁移到目标图像中的人物身上。