Qwen-Image-2512-Turbo-LoRA Qwen-Image-2512-Turbo-LoRA 是由呜里团队训练的一个 4 步快速 LoRA,基于 Qwen-Image-2512 模型。该 LoRA 在保持原模型输出质量的同时,推理速度提升了 20 倍以上
Qwen_Image_4_Grid_Display_Lora Qwen_Image_4_Grid_Display_LoRA 是一款基于 Qwen-Image 模型微调的 LoRA 适配器,专为生成四格统一视觉风格图像而设计。它能够将一个抽象创意或设计概念,一次性输出为四个在色彩、构图、视角和主题上高度一致的图像,形成一个完整的视觉网格,极大提升设计探索与原型迭代的效率。
Instagirl Instagirl是一款适用于WAN 2.2/WAN 2.1的Lora,WAN系列模式虽然是视频生成模型,但它同样适用于文生图,这款Lora即是,训练者00quebec用3000多张图片和130多个不同的Instagram模特对WAN 2.2进行微调的一款文生图Lora
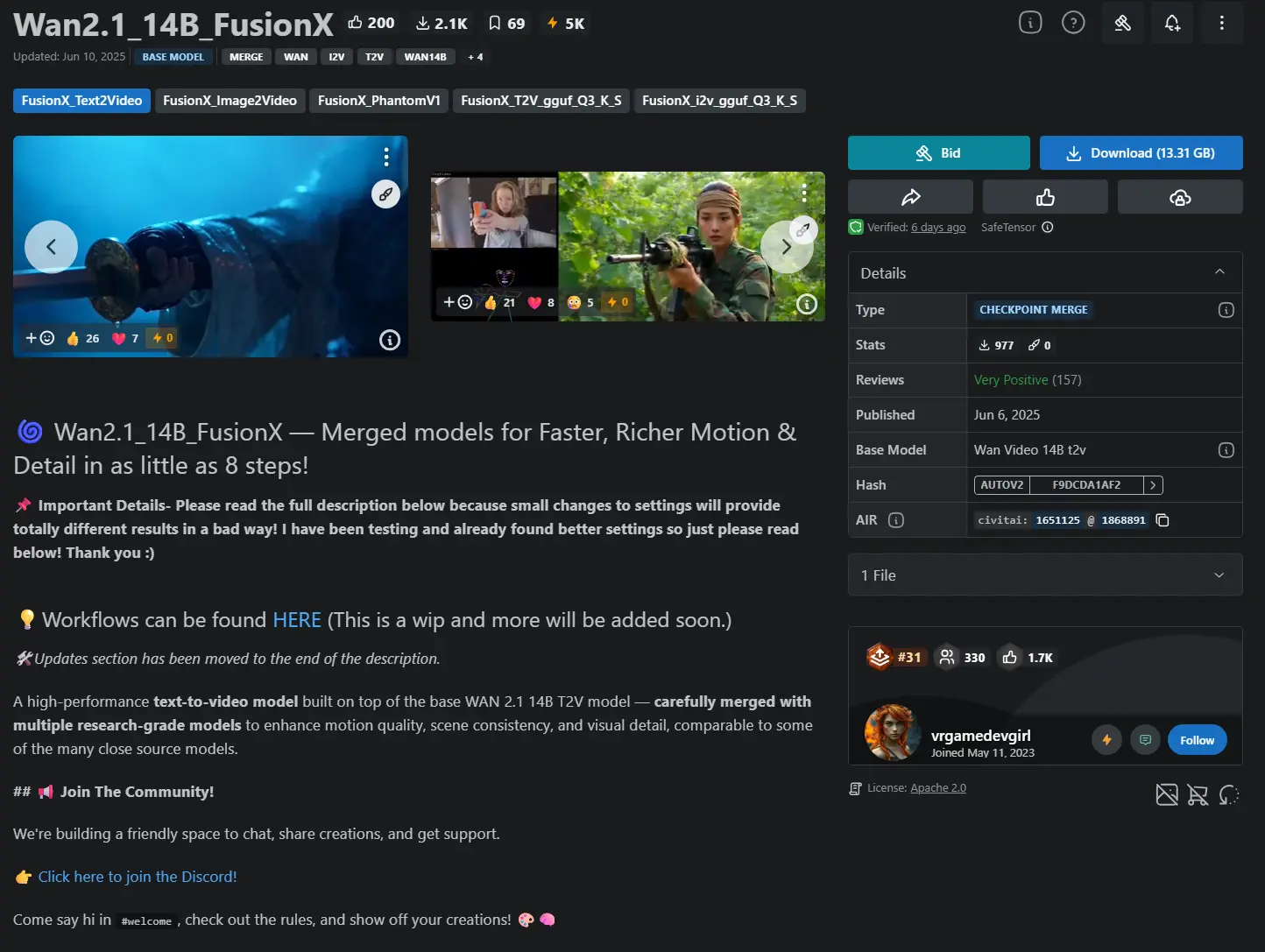
Wan2.1_14B_FusionX Wan2.1_14B_FusionX 是一款基于Wan2.1的融合模型,实现更快、更丰富的运动与细节,最少仅需8个步骤!它不仅提升了生成效率,还在细节表现、运动质量和风格多样性方面做了深度优化,是目前最接近“电影级 AI 视频”的开源模型之一。
Live Wallpaper Style Live Wallpaper Style 是一款专为生成动态壁纸风格视频而设计的LoRA,提供了多种版本以满足不同需求,包括 Wan I2V 14B 720P、Wan I2V 14B 480P 和 Hunyuan T2V 版本。
Clothes Try On (Clothing Transfer) Clothes Try On (Clothing Transfer) 是目前基于 Qwen-Image-Edit 实现虚拟试衣的实用化尝试之一。虽然在复杂图案和配件处理上仍有提升空间,但其在人体贴合度和体型泛化能力方面的表现令人印象深刻。
Normal Map Kontext Normal 是一个专注于将常规图像(如AI生成的角色图或纹理图)转换为高质量法线贴图(Normal Map) 的轻量级LoRA,基于 FLUX.1-Kontext-dev 模型训练而成。
SDXL Anime VAE Decoder 开发者 Anzhc 推出 SDXL Anime VAE Decoder —— 一个仅对 SDXL 原生 VAE 解码器进行微调 的轻量模型,专为提升动漫图像生成质量而设计。
Amateur Snapshot Photo Amateur Snapshot Photo 是一个专注于还原早期手机拍照风格的 LoRA 模型,它成功地减少了 AI 生成图像的“完美感”,增加了生活气息与真实质感。对于希望生成更具“人味”的图像、或者构建具有怀旧氛围的内容创作者来说,这是一个非常值得尝试的模型。
Aether Crash Zoom Aether Crash Zoom 是一个专为 Wan 2.2 5B (i2v) 模型设计的轻量适配 LoRA,旨在实现一种极具张力的视觉效果——从远距离构图中突然高速推进,聚焦于远处主体。
Paint & Print Paint & Print是一款墨水、纸张与表达的融合的Flux LoRA,其灵感来源于一种独特的艺术技法,该技法使用印刷媒体(如旧书、乐谱、报纸、地图)作为画布。这种艺术作品尊重并融合了底层的印刷内容,而不是完全覆盖它,使部分印刷材料隐约可见,将其融入作品中,而不仅仅是作为背景。
Hyperdetailed Colored Pencil Hyperdetailed Colored Pencil 是一款专为追求高质量、细节丰富的艺术作品而设计的生成模型。无论是用于创作逼真的肖像画还是探索其他艺术形式,这款模型都能提供令人惊叹的效果。
Tabletop Miniatures Tabletop Miniatures是一款桌面微缩模型Flux Lora,自然就是适合出桌面微缩模型图片,再搭配混元或Wan2.1模型来生成视频,效果会非常好。
Kontext_OmniConsistency_lora Kontext_OmniConsistency_lora是一款专为图像生成模型 FLUX.1 Kontext [dev] 打造的 艺术风格 LoRA 模型。该模型艺术风格来自之前介绍的通用一致性模型 OmniConsistency ,专注于将图像转换为 22 种不同艺术风格,同时保持画面内容的一致性。
Wan14BT2V_FastMasterModel Wan14BT2V_FastMasterModel是一款强大的混合文本到视频模型,基于原始的WAN 2.1 T2V模型,通过融合多个开源组件和LoRA增强了动作真实感、时间一致性和表现细节。集成了多个开源模型和LoRA,以提升时间质量、表现力和动作真实感。
Technically-Color-Z-Image-Turbo Technically-Color-Z-Image-Turbo 是基于 Z-Image-Turbo 基础模型微调的 LoRA,专为复现 20 世纪经典电影 的标志性视觉风格而设计。
flux-krea-extracted-lora flux-krea-extracted-lora 展示了从闭源或专用模型中提取风格化 LoRA 的可能性,技术路径值得肯定。它确实携带了 Krea 的部分美学先验,尤其在面部优化方面有一定价值。