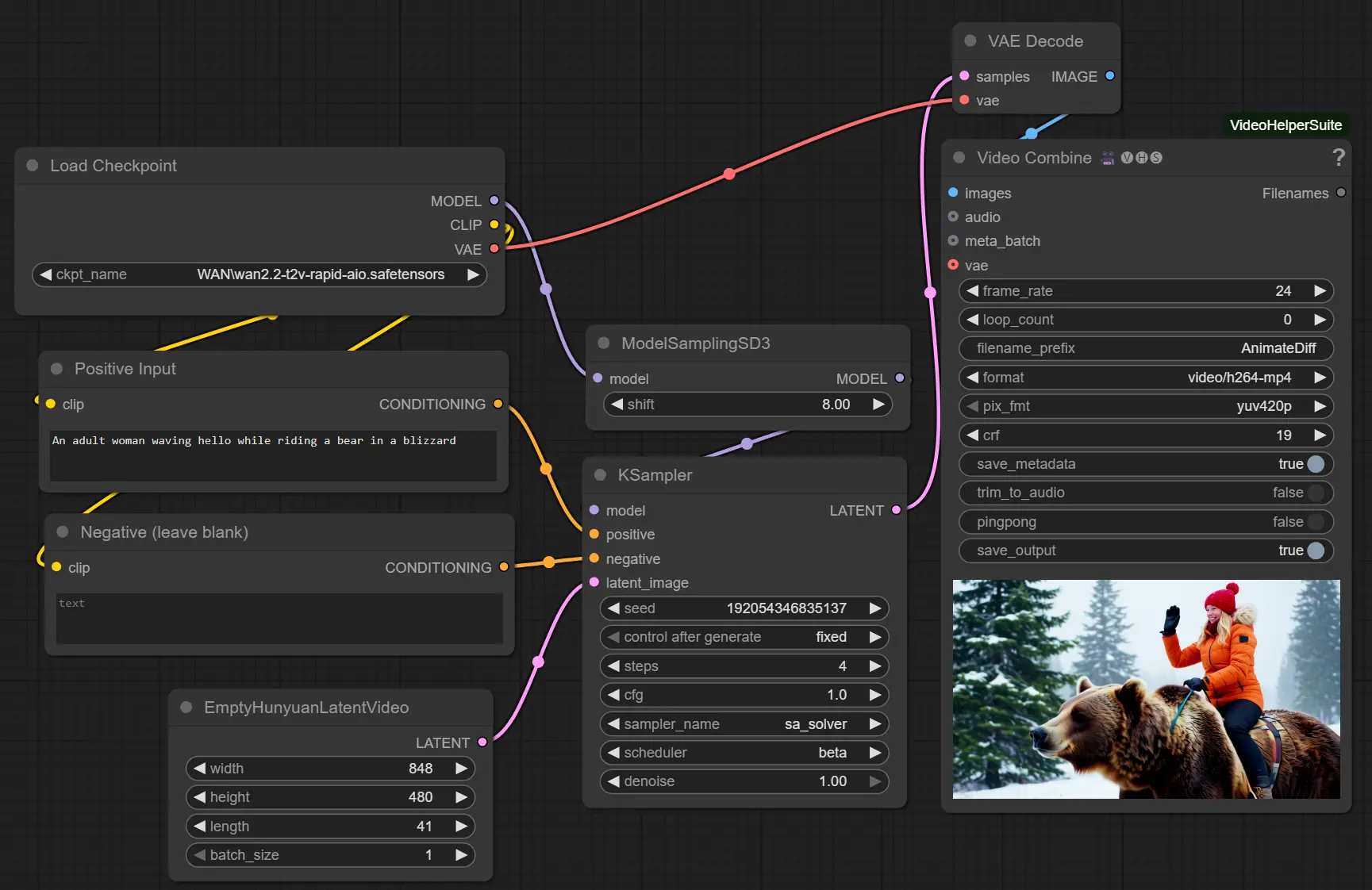
WAN2.2-14B-Rapid-AllInOne 这个“一体化”WAN2.2 模型,更贴近日常使用——更简单、更快、更兼容。如果你正在使用 WAN 系列模型,不妨试试这个整合版本,或许能为你的工作流带来意想不到的提升。
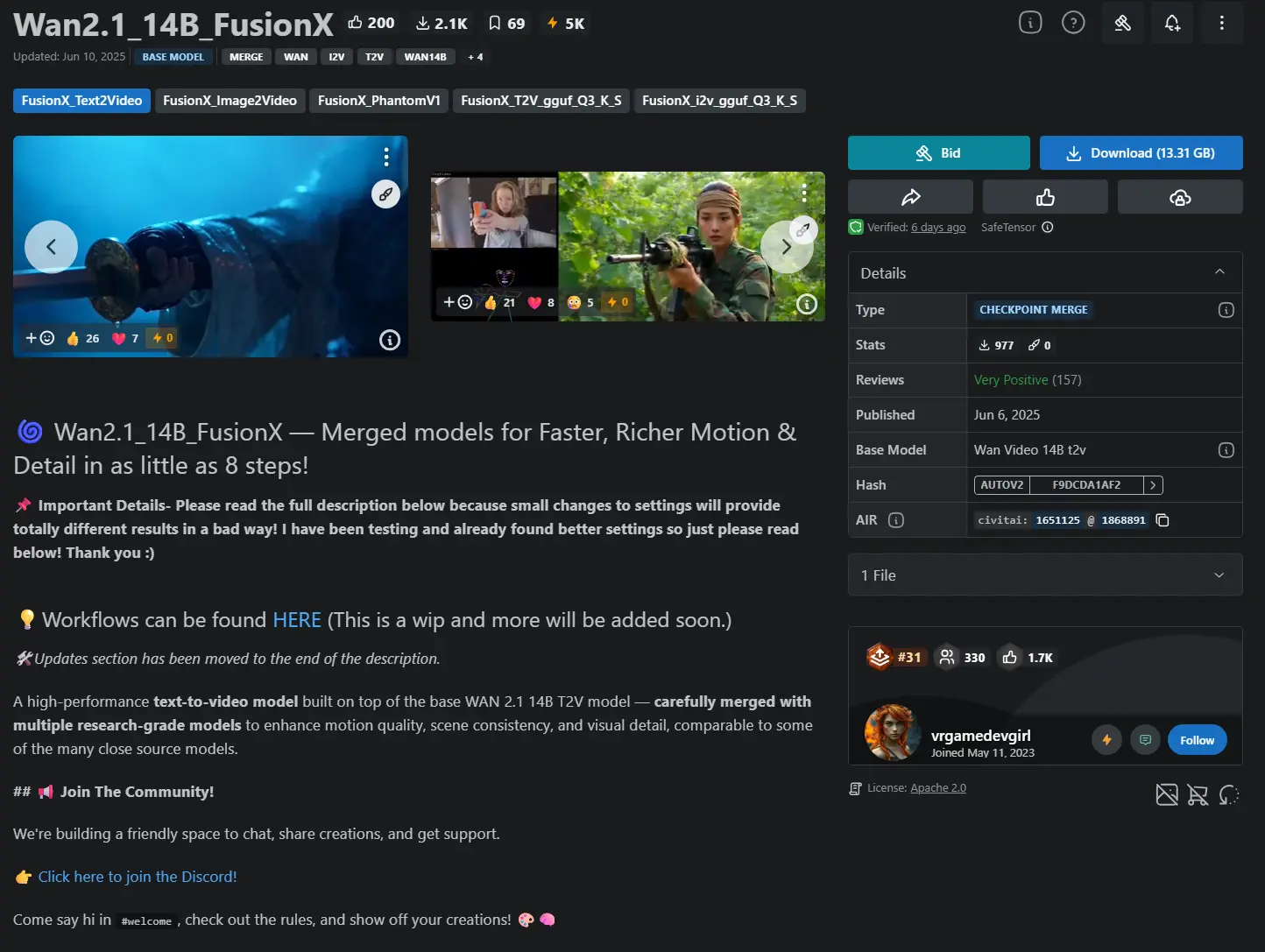
Wan2.1_14B_FusionX Wan2.1_14B_FusionX 是一款基于Wan2.1的融合模型,实现更快、更丰富的运动与细节,最少仅需8个步骤!它不仅提升了生成效率,还在细节表现、运动质量和风格多样性方面做了深度优化,是目前最接近“电影级 AI 视频”的开源模型之一。
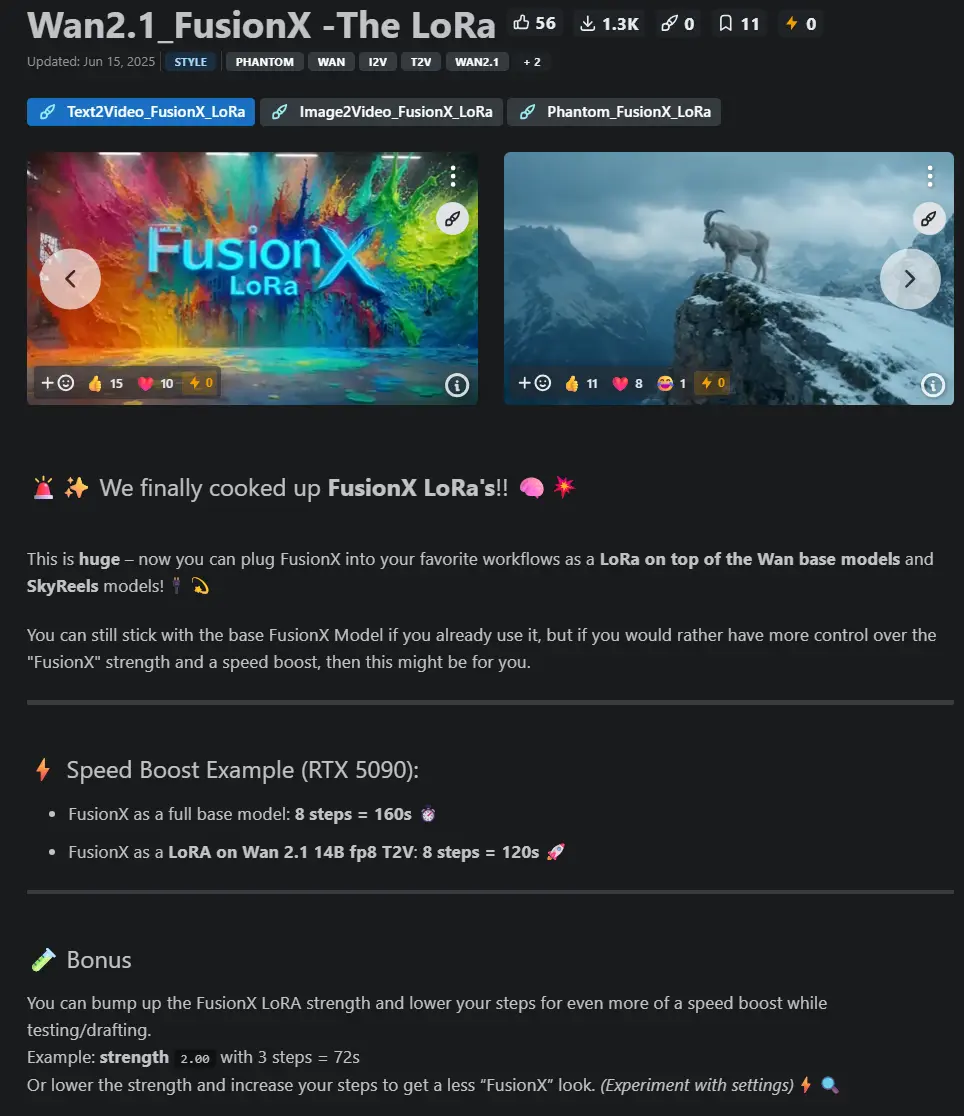
Wan2.1_FusionX -The LoRa Wan2.1_FusionX - LoRA意味着你可以直接将 FusionX 风格注入到 Wan2.1 基础模型 或 SkyReels 模型 中,而无需下载庞大的 14B 全模型。LoRA 的体积远小于完整模型,更适合本地部署和灵活调整。
Relighting Kontext Dev LoRA Relighting Kontext Dev LoRA v3 是一款功能强大且实用的图像重新照明模型,尤其适合需要快速调整光影效果的用户。无论是专业设计师、摄影师还是普通爱好者,都可以通过它轻松实现高质量的图像重新照明效果。
Studio Ghibli Style Studio Ghibli Style是一款吉卜力风Wan2.1-T2V-14B Lora,使用训练工具musubi-tuner ,使用 240 个剪辑和 120 张图像的混合数据集进行了 ~90 小时的训练而成。
Live Wallpaper Style Live Wallpaper Style 是一款专为生成动态壁纸风格视频而设计的LoRA,提供了多种版本以满足不同需求,包括 Wan I2V 14B 720P、Wan I2V 14B 480P 和 Hunyuan T2V 版本。
Qwen-Image-Edit-InStyle Qwen-Image-Edit-InStyle 是对 Qwen-Image-Edit 模型在风格迁移能力上的一次重要增强。 它让原本“泛化有余、精准不足”的风格迁移,变得可预测、可控制、可复用,特别适用于: 艺术创作中的风格探索、品牌视觉统一性生成、游戏与动画概念设计、个性化内容生成。
Qwen Edit Figure Maker wen Edit Figure Maker由模型训练者 aldniki217 基于 Qwen Image Edit 模型微调训练的 LoRA,灵感源自谷歌 Nano Banana模型的“真实手办”玩法,但更稳定、更可控、更支持中文。
Kontext-Emoji-LoRA Kontext-Emoji-LoRA是一个用于风格迁移的模型,基于FLUX.1-Kontext-dev 训练,适用于人类形象的emoji风格化任务,可在 ComfyUI 中使用。
Tattoo Kontext Dev LoRA Tattoo Kontext Dev LoRA 的核心优势在于其对人体结构与皮肤质感的深刻理解。它能将用户提供的纹身设计草图,精准地“贴合”到指定的身体部位,并自动处理细节。
Improved Amateur Snapshot Photo Realism 此Lora旨在生成更“真实”且更少“FLUX 风格”的图像。该模型通过优化自然光和人造光的表现、减少散景强度、为图像的每个部分(如皮肤、眼睛、头发和树叶)添加更多细节。
Character Turnaround Sheet Flux Kontext Character Turnaround Sheet LoRA是一款基于图像编辑模型Flux Kontext的lora,用于创建此特定角色的旋转图。