Nunchaku-Qwen-Image-EDIT-2511/Nunchaku-Qwen-Image-2512 官方 Nunchaku 推理引擎 本以高效量化著称,能显著降低显存占用,但近期对阿里新发布的 Qwen-Image-2512 和 Qwen-Image-EDIT-2511 尚未提供官方支持。 好消息是:社区开发者 QuantFunc 已率先完成量化适配,并发布了两个系列的 4-bit 模型,现已可在 ComfyUI 中直接使用。
Street Fighter Hodouken I2V Lora 通过 Street Fighter Hadouken I2V LoRA,你可以轻松将《街头霸王》中的经典“波动拳”招式融入你的视频创作中。无论是经典角色还是自定义形象,只需简单的提示词和参数设置,即可实现极具视觉冲击力的动作效果。
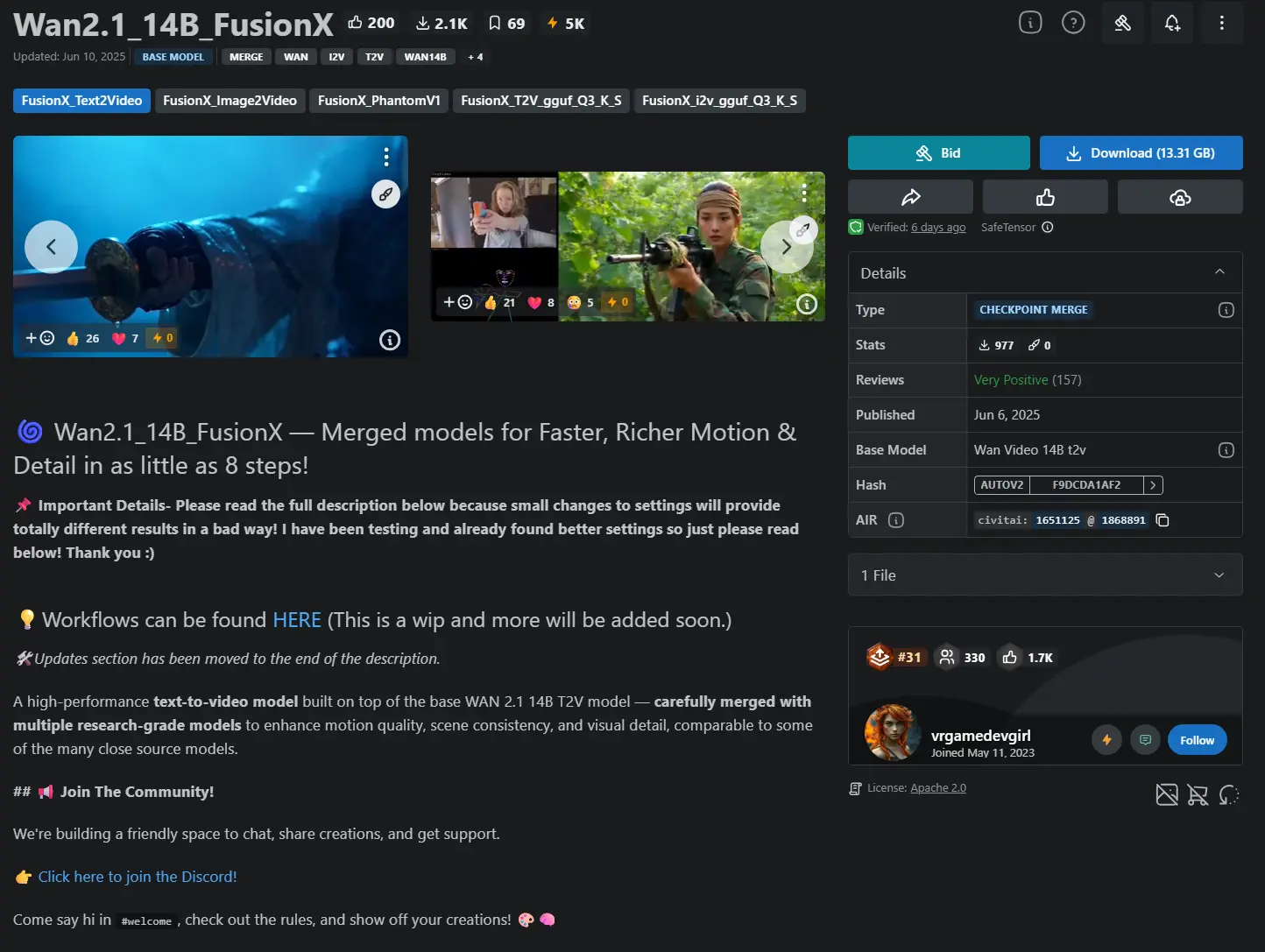
Wan2.1_14B_FusionX Wan2.1_14B_FusionX 是一款基于Wan2.1的融合模型,实现更快、更丰富的运动与细节,最少仅需8个步骤!它不仅提升了生成效率,还在细节表现、运动质量和风格多样性方面做了深度优化,是目前最接近“电影级 AI 视频”的开源模型之一。
Improved Amateur Snapshot Photo Realism 此Lora旨在生成更“真实”且更少“FLUX 风格”的图像。该模型通过优化自然光和人造光的表现、减少散景强度、为图像的每个部分(如皮肤、眼睛、头发和树叶)添加更多细节。
Flux Kontext Makeup Remover Flux Kontext Makeup remover是一个专注于为浓妆女子卸妆的LoRA,基于 FLUX.1-Kontext-dev 模型进行训练,将真实人物的浓妆卸去。
CLAY GPT for flux CLAY GPT for flux 是一个专为 Flux 设计的 LoRA 模型 ,其训练数据完全来自于 GPT-4o 生成的 Clay(黏土)风格图像 。该模型能够帮助用户在文本到图像生成任务中,快速还原出具有手工质感和动画风格的黏土艺术效果。
Tabletop Miniatures Tabletop Miniatures是一款桌面微缩模型Flux Lora,自然就是适合出桌面微缩模型图片,再搭配混元或Wan2.1模型来生成视频,效果会非常好。
Aether Crash Zoom Aether Crash Zoom 是一个专为 Wan 2.2 5B (i2v) 模型设计的轻量适配 LoRA,旨在实现一种极具张力的视觉效果——从远距离构图中突然高速推进,聚焦于远处主体。
Raena-Qwen-Image Raena-Qwen-Image 是一个为 Qwen-Image 微调的 LoRA,专为动漫风格生成设计。该模型的目标是增强 Qwen-Image 在生成高质量动漫输出的能力,具有更清晰的细节、更丰富的色彩和更好的美学效果。
QIE-2509-Object-Remover-Bbox QIE-2509-Object-Remover-Bbox 是为 Qwen-Image-Edit-2509 开发的一个 LoRA,使用边界框引导精确地从图像中移除不需要的物体。
Fix JPEG artifacts compression lora Fix JPEG artifacts compression lora是一款基于图像编辑模型Flux Kontext开发的微调LoRA模型,此模型是用来修复JPEG压缩伪影。
Qwen_Image_4_Grid_Display_Lora Qwen_Image_4_Grid_Display_LoRA 是一款基于 Qwen-Image 模型微调的 LoRA 适配器,专为生成四格统一视觉风格图像而设计。它能够将一个抽象创意或设计概念,一次性输出为四个在色彩、构图、视角和主题上高度一致的图像,形成一个完整的视觉网格,极大提升设计探索与原型迭代的效率。
Flux Kontext Zoom Out LoRA Flux Kontext Zoom Out LoRA 是一款专为图像编辑模型 FLUX.1 Kontext [dev] 训练的 LoRA模型,实现高质量的图像“放大”或“画布外扩”(zoom out)效果。
Character Turnaround Sheet Flux Kontext Character Turnaround Sheet LoRA是一款基于图像编辑模型Flux Kontext的lora,用于创建此特定角色的旋转图。