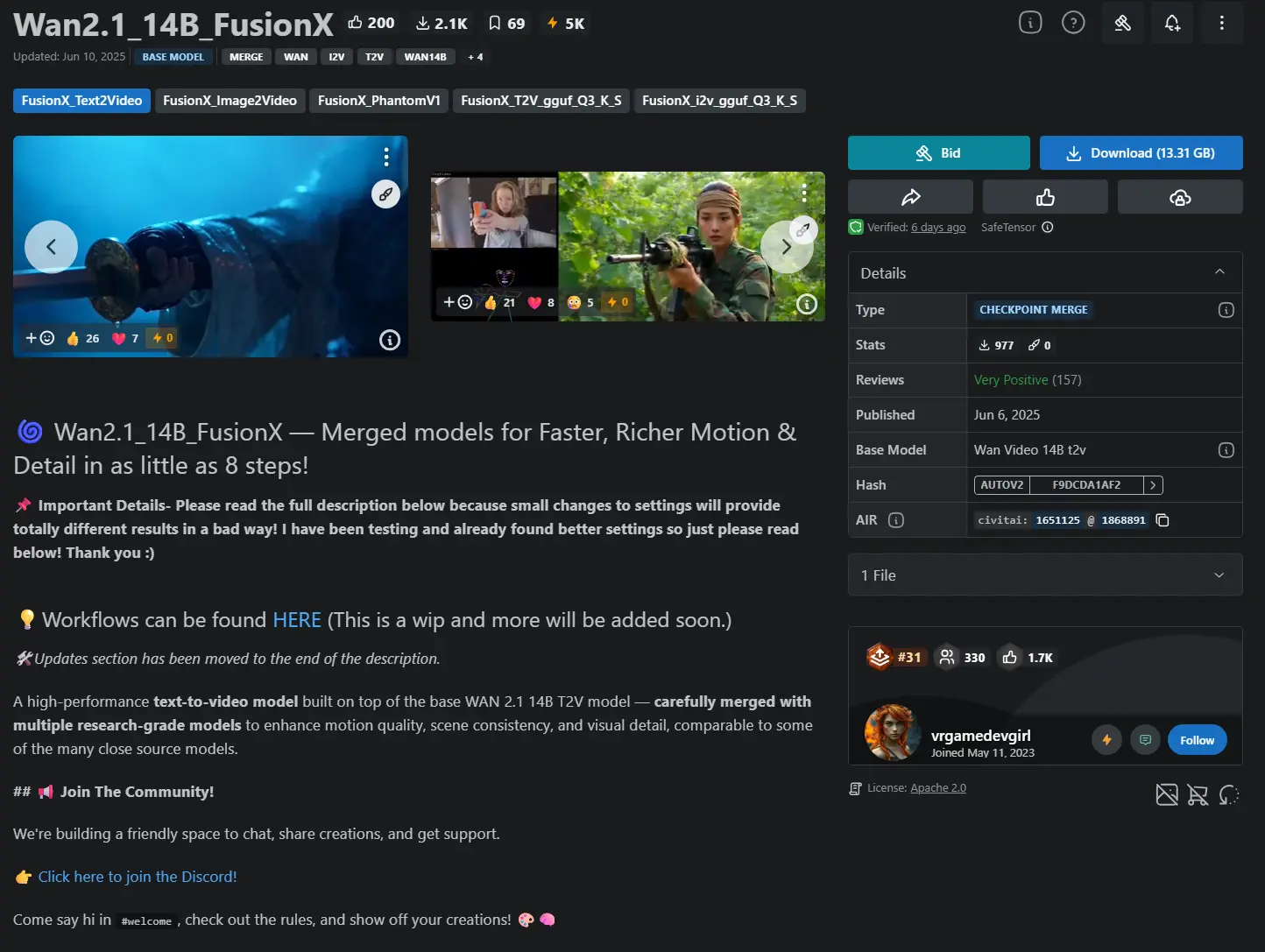
Gurren Lagann / Anime Style Wan 2.2 14B Lora
Gurren Lagann / Anime Style Wan 2.2 14B Lora是一个致敬《天元突破》动画美学的 Wan 2.2 风格 LoRA,是一个为 Wan 2.2 T2V 14B 模型设计的风格 LoRA,致力于还原 Gainax 2007 年经典动画《天元突破 红莲螺岩》的独特视觉语言与动态节奏。

尽管 WAN 2.1 和 WAN 2.2 最初定位为视频生成模型,但其强大的视觉生成能力同样适用于静态图像任务。近期,训练者 00quebec 基于 WAN 2.2/WAN 2.1 推出了一款专注于文生图的 LoRA 模型 —— Instagirl,旨在复现 Instagram 风格的女性人像摄影。
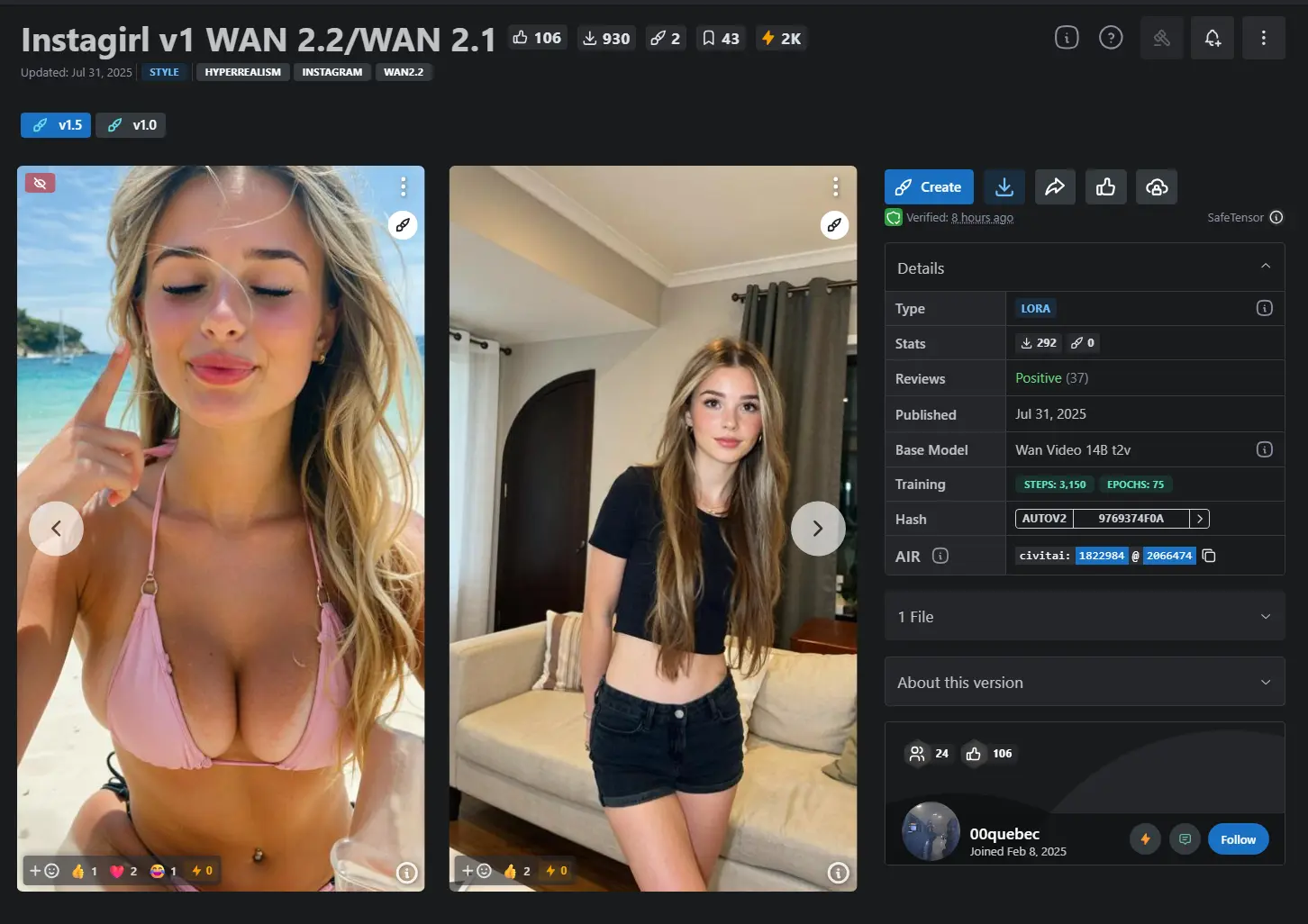
Instagirl该模型专注于还原真实社交平台中常见的女性人像风格:生活化构图、手机拍摄质感、自然光影与穿搭氛围。
训练者 00quebec 分享了其在实际使用中的高效工作流:借助 ChatGPT 自动化生成符合模型输入习惯的提示词。
操作方式如下:
• 以主体和LoRA触发词开头,精确写为:Instagirl,娇小身材,然后按以下顺序继续:姿势 → 相机角度 → 服装及主要配饰 → 环境/背景 → 照明 → 额外氛围。
• 保持措辞自然但简洁——像是给朋友的快速笔记——每个细节用逗号分隔,而非完整句子(例如:纽约市,阴郁的日子,漂亮女孩,自拍)。
• 说明照片为业余手机画质,明确指出头发颜色、类型和面部结构;仅当为镜子自拍时,添加主体手持银色iPhone(三摄像头)的描述。
• 忽略所有纹身、穿孔、身体改造、眼镜、屏幕上的GUI或图标。
• 避免使用填充词,避免使用LoRA触发词的同义词,以保持其影响力。
• 在段落后,新起一行,列出以下内容:可见传感器噪点、人工过度锐化、重度HDR光晕、业余照片、过曝高光、丢失阴影。
Instagirl, 娇小身材, 侧身站立, 低角度拍摄, 白色吊带上衣搭配高腰牛仔热裤, 城市街道背景, 正午阳光直射, 轻松夏日氛围, 棕色波浪长发, 瓜子脸, 皮肤白皙
可见传感器噪点, 人工过度锐化, 重度HDR光晕, 业余照片, 过曝高光, 丢失阴影
此格式提示词可直接用于支持 WAN 系列模型的生成平台(如 ComfyUI、Auto1111 等),帮助稳定激活 LoRA 风格特征。