
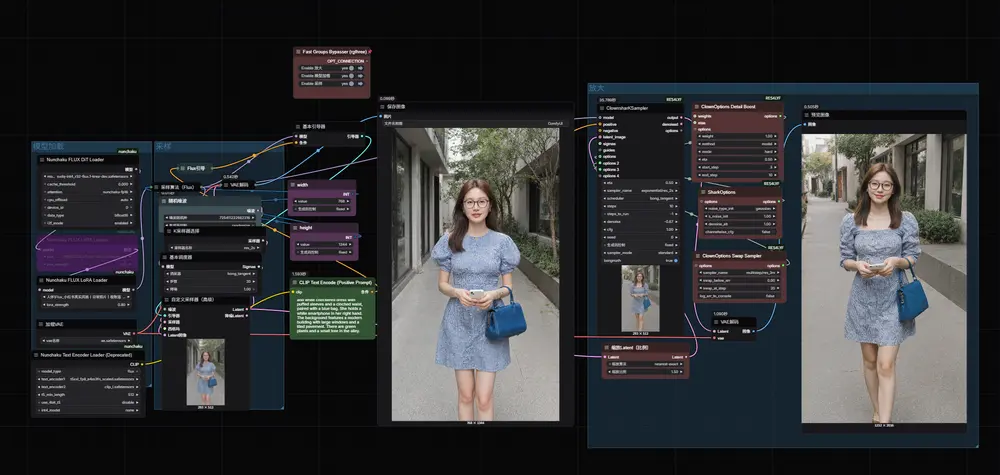
kontext-make-person-real
kontext-make-person-real 是一个针对FLUX.1-Kontext-dev 的小型但高效的 LoRA,专注于提升 AI 生成人物图像的真实感。如果你在使用 SDXL 或 FLUX 时常常遇到人物面部“AI 感”过重的问题,这个 LoRA 值得一试。
nunchaku-flux.1-krea-dev 的意义在于,它证明了即使在 4-bit 低精度下,扩散模型依然可以生成高质量、富有细节的图像。通过 SVDQuant 与 Nunchaku 推理系统的结合,我们得以在不牺牲太多质量的前提下,大幅降低硬件门

nunchaku-flux.1-krea-dev 是 FLUX.1-Krea-dev 模型的Nunchaku 量化版本,专为在消费级显卡上实现高效图像生成而设计。它通过先进的 SVDQuant 量化技术,将原模型压缩至 INT4 或 NVFP4 精度,在显著降低显存占用与计算需求的同时,保持接近原始模型的生成质量。
该版本适用于希望在有限硬件资源下运行高质量文本到图像任务的用户,尤其适合本地部署、边缘设备推理或高吞吐服务场景。
| 特性 | 说明 |
|---|---|
| 📦 INT4 / NVFP4 量化 | 显存占用减少约 60–70%,适合 16GB 及以下显存设备 |
| ⚡ 高效推理 | 在非 Blackwell GPU 上使用 INT4,在 Blackwell(50 系列)上启用 NVFP4 加速 |
| 🎨 质量保留 | 基于 SVDQuant 技术,有效抑制低比特量化中的“异常值”问题,减少生成退化 |

本仓库提供两个量化版本,针对不同 GPU 架构优化:
| 文件名 | 精度 | 适用硬件 | 显存优势 |
|---|---|---|---|
svdq-int4_r32-flux.1-krea-dev.safetensors | INT4(SVDQuant) | 非 Blackwell 显卡 (如 RTX 30/40 系列) | 显存减少 ~65% 推理速度提升明显 |
svdq-fp4_r32-flux.1-krea-dev.safetensors | NVFP4(SVDQuant) | Blackwell 架构显卡 (RTX 50 系列及以上) | 利用原生 FP4 支持 实现极致加速 |
💡 提示:NVFP4 是英伟达在 Blackwell 架构中引入的原生 4-bit 浮点格式,配合 SVDQuant 可实现更高效率与稳定性。
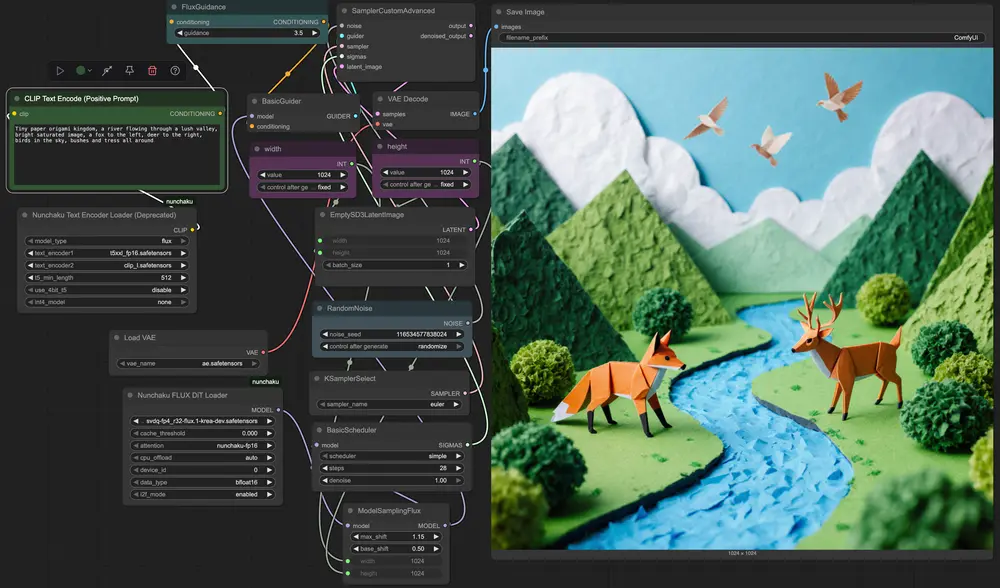
该模型可无缝集成至 ComfyUI,操作简单,无需修改工作流。
.safetensors 文件models/checkpoints/)nunchaku-flux.1-dev.json✅ 支持标准文本提示输入
✅ 兼容 LoRA、ControlNet 等扩展模块(视具体配置而定)












