STABLE PROJECTORZ - 最新版
STABLE PROJECTORZ是一款免费工具,用于通过StableDiffusion制作纹理和3D内容。它提供了丰富的功能,包括保留UV、通过笔刷混合图层、通过文本或图像生成提示,以及3D修复。
![LightDiffusion-Next 的使用截图[1]](https://pic.sd114.wiki/wp-content/uploads/2025/03/1740993495-1740993495-LightDiffusion-Next-2.webp)
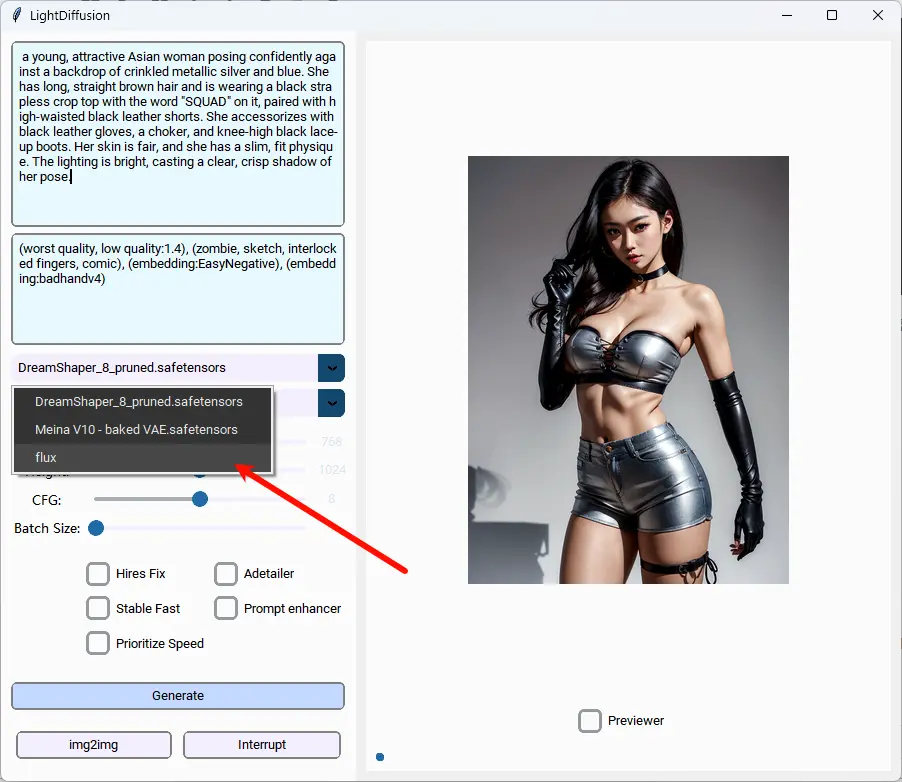
LightDiffusion-Next 是一款集速度、精度和灵活性于一身的 AI 驱动图像生成工具,支持图形界面(GUI)和命令行界面(CLI)。它基于原始的 LightDiffusion 仓库重构并改进而成,不仅提升了可用性、可维护性和功能性,还引入了大量新功能,极大地简化了创作流程。
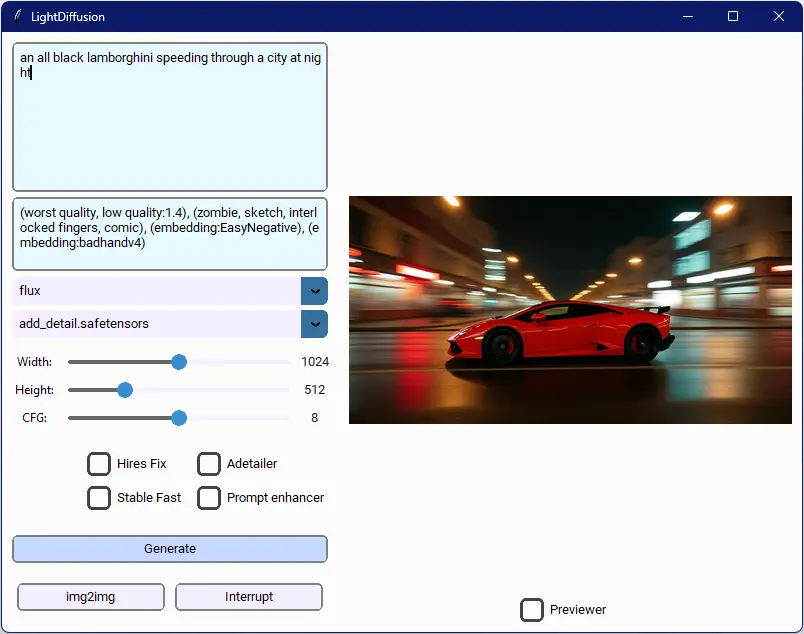
LightDiffusion 最初计划用 Rust 编写,但由于 AI 社区对 Rust 的支持不足,最终选择 Python 实现。其目标是打造一个简单且快速的 AI 图像生成工具。首个版本的 LightDiffusion 仅包含 3000 行代码,基于 Pytorch 开发。然而,随着项目复杂度的提升,重构的需求日益凸显。于是,LightDiffusion-Next 应运而生,它拥有更模块化、更可维护的代码库,并引入了众多新功能和优化。
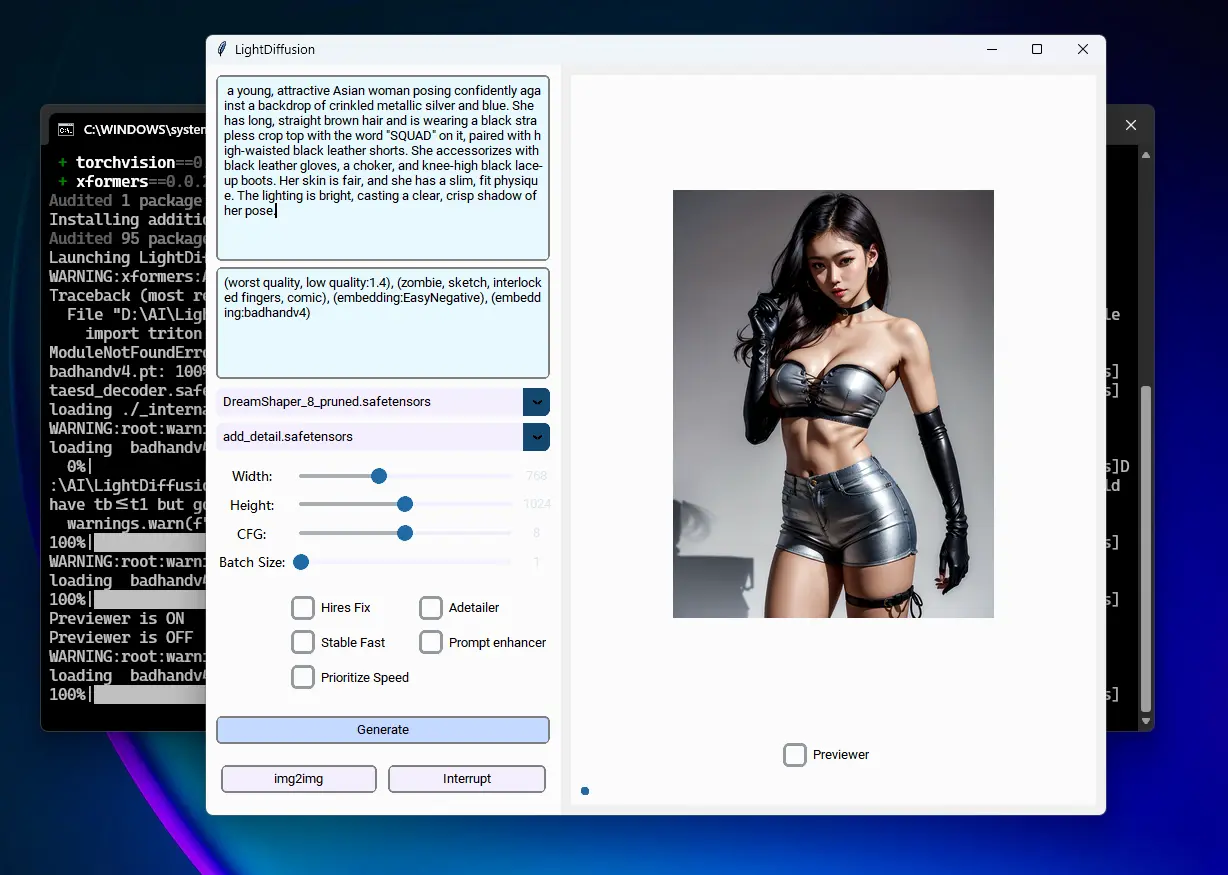
LightDiffusion-Next 提供了一套强大的工具,满足不同层次创作者的需求。其核心功能包括文本到图像(Txt2Img)和图像到图像(Img2Img)生成,支持多种放大方法和采样器,帮助用户轻松生成令人惊叹的图像。
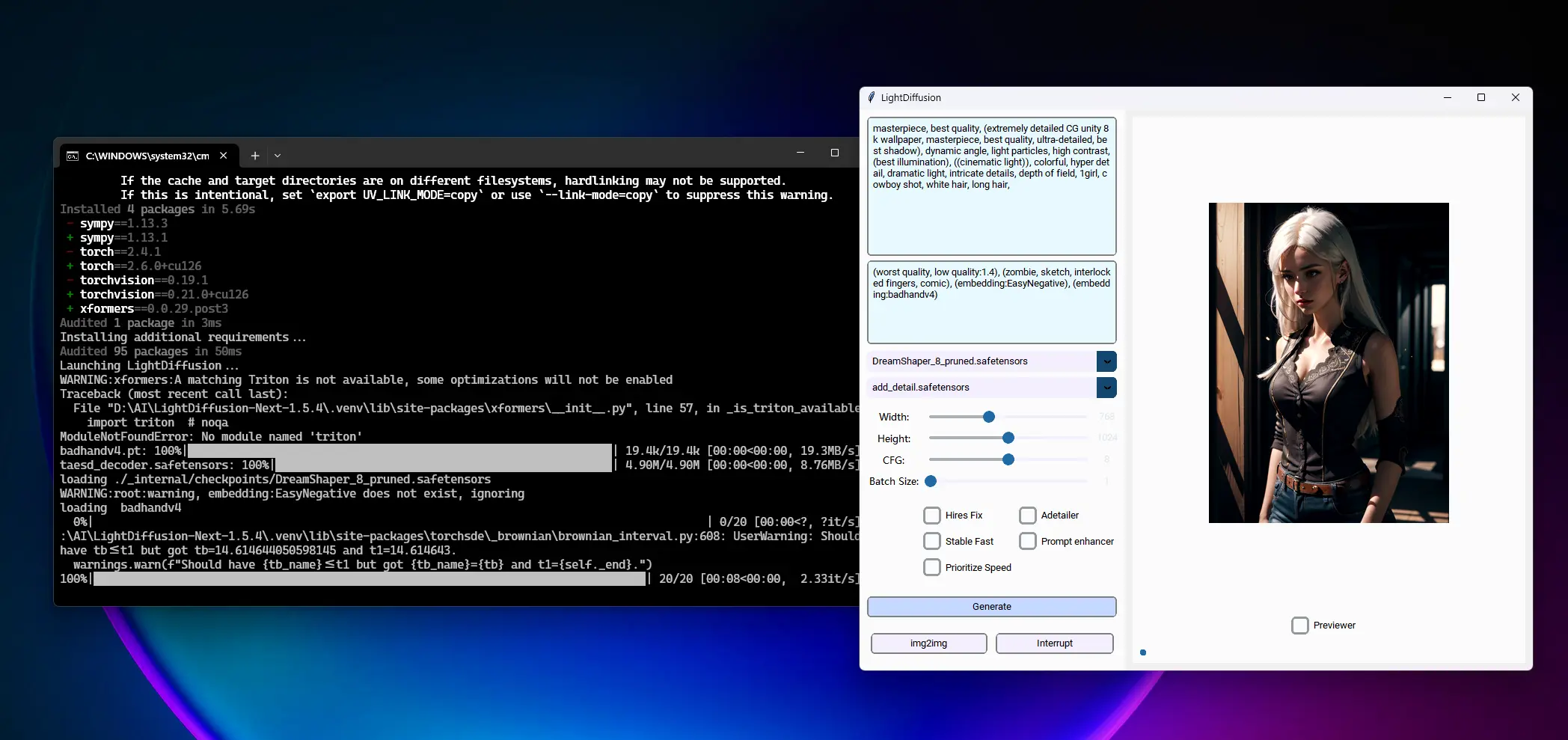
在性能方面,LightDiffusion-Next 表现卓越。以下是基于 1024x1024 分辨率、批量大小为 1、BFloat16 精度的基准测试结果(使用配备 SD1.5 的 3060 移动 GPU 测试):
| 工具 | 速度(it/s) |
|---|---|
| LightDiffusion with Stable-Fast | 2.8 |
| LightDiffusion | 1.9 |
| ComfyUI | 1.4 |
| SDForge | 1.3 |
| SDWebUI | 0.9 |
凭借其卓越的速度和效率,LightDiffusion-Next 成为 AI 图像生成工具的新标杆。
run.bat。
PS:运行run.bat后会自动安装相关组件及两款SD1.5模型,如果想使用Flux模型,需要满足以下条件:
前提条件
在开始之前,请确保你有以下物品:
技巧和窍门