
Advanced Image Captioning App 是一个强大且用户友好的工具,使用最先进的 AI 模型为您的图像生成详细的描述。该应用结合了 Florence-2 和 Llama 3.2 Vision 模型的优势,为您上传的任何图像提供丰富、上下文相关的描述。
✨ 功能
双模型支持:在 Florence-2 和 Llama 3.2 Vision 模型之间进行选择 批处理:一次上传并处理多张图像 有序输出:描述带有时间戳,便于参考 用户友好界面:干净、直观的 Streamlit 界面 错误处理:全面的错误消息和日志记录
🚀 入门指南
先决条件
在开始之前,请确保您的机器上安装了 Python 3.8+。您还需要一些磁盘空间来存储 AI 模型。您还需要在本地机器上安装 Ollama。
安装
克隆此仓库: git clone https://github.com/yourusername/image-captioning-app.git cd image-captioning-app创建虚拟环境(推荐): python -m venv venvsource venv/bin/activate # 在 Windows 上使用:venv\Scripts\activate安装所需的包: pip install -r requirements.txt运行应用:
使用以下简单命令启动应用:
streamlit run app.py应用将在您的默认浏览器中打开。如果未打开,请访问 http://localhost:8501。
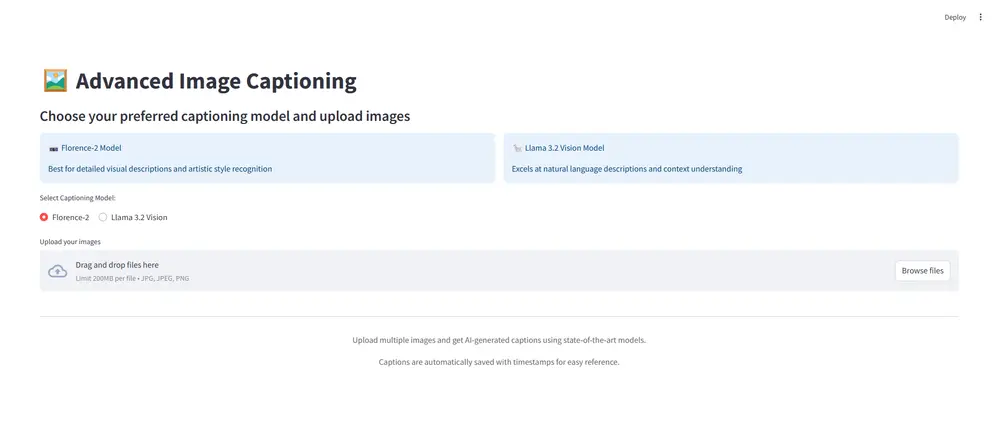
🎯 如何使用
选择模型: Florence-2:适用于详细的视觉描述和艺术风格识别 Llama 3.2 Vision:擅长自然语言描述和上下文理解
上传图像: 点击上传按钮或拖放您的图像 支持 JPG、JPEG 和 PNG 格式 一次上传多张图像进行批处理
获取描述: 应用处理每张图像并显示生成的描述 描述会自动保存在 captions文件夹中每个会话都有自己的时间戳文件夹
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











