
在人工智能领域,生成式 AI技术不断进步,大语言模型如ChatGPT引领风潮,与此同时,文生图与文本转语音技术也取得显著进展。今天要给大家介绍的ChatTTS就是一个强大的开源文本转语音系统,它是专门为对话场景设计的文本转语音模型,例如大语言模型助手对话任务。它支持英文和中文两种语言。最大的模型使用了10万小时以上的中英文数据进行训练,使得ChatTTS 能够生成高质量和自然度的语音。

ChatTTS简介
ChatTTS 是专为对话场景设计的文本转语音模型,支持英文和中文两种语言。它的最大模型使用了超过10万小时的中英文数据进行训练,能够生成高质量和自然的语音。为了防止滥用,开发者强调负责任和符合伦理地利用这项技术的重要性。为了限制ChatTTS的滥用,开发者在训练过程中添加了额外的高频噪音,并以mp3格式降低音质,同时内部训练了检测模型,计划未来开放。
ChatTTS亮点
- 对话式TTS:优化自然流畅的语音合成,支持多说话人。
- 细粒度控制:模型能预测和控制包括笑声、停顿和插入词在内的细粒度韵律特征。
- 更好的韵律:在韵律方面超越大多数开源TTS模型,提供预训练模型,支持研究。
常见问答
- 硬件需求:生成30秒音频需至少4GB显存,RTX 4090D下,每秒可处理约7字,实时因子约为0.65。
- 稳定性问题:模型可能因自回归特性偶现说话人变换或音质波动,建议多次尝试取优。
- 情感控制:当前模型支持笑声及特定语气标记控制,未来版本将探索更多情感维度控制。
如何获取与使用
- GitHub: https://github.com/2noise/ChatTTS
- 模型下载: https://huggingface.co/2Noise/ChatTTS
- Colab: https://colab.research.google.com/drive/1fJGsNoKxUD62no-Y2mb5onAkhIXbsrI5?usp=sharing
- Hugging Face Demo: https://huggingface.co/spaces/Dzkaka/ChatTTS
使用指南
本地安装:
推荐程序员采用,需英伟达显卡支持,具体步骤可见项目说明或参考社区教程。将项目git到本地后,使用Visual Studio Code或PyCharm编辑器打开此项目,按照图示输入以下代码,然后运行,运行时遇到报错就查看需要什么组件,缺什么组件就装什么组件。(图片来自X用户@AdamCarterCS)
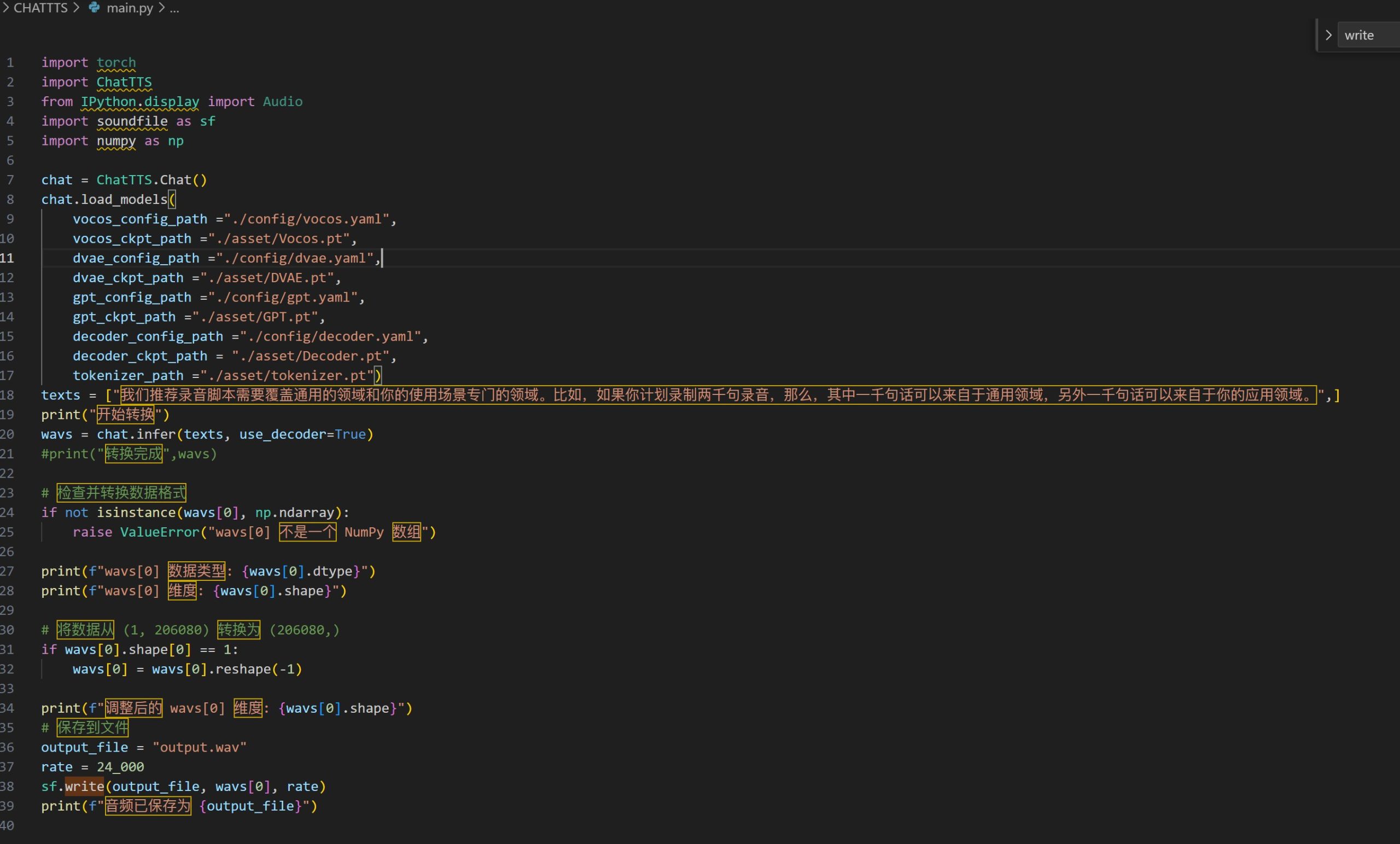
当然大家也可以按照官方的方法,使用命令提示符或终端来执行项目git和运行,当然前提是你已经安装git、python、Cuda等软件。目前也已经有网友制作了整合包,大家可以在B站搜索。
Colab体验:
无需本地配置,网络畅通即可尝试,参考教程视频轻松上手。
Hugging Face Demo:
便捷的UI界面,即开即用,非官方但功能齐全,推荐初学者选用。
注意事项
- 当前版本对中文标点和阿拉伯数字支持有限,建议避免或转换为读音友好的形式。
- 创意表达时,不妨加入[laugh]和[uv_break]指令,让语音更生动。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











