快手旗下 可灵 AI 通过官方公众号宣布,其首个 音画同出模型 正式上线。该模型可在单次生成中同步输出画面、自然语音、匹配音效与环境氛围,首次实现“音”与“画”的深度协同创作。
新模型作为 可灵 2.6 的核心升级,提供两条创作路径:
- 文生音画:输入一段文字,自动生成包含语音、画面与背景音效的完整视频;
- 图生音画:上传一张静态图片,让画面“开口说话”并动起来,适用于人像、产品图、插画等场景。
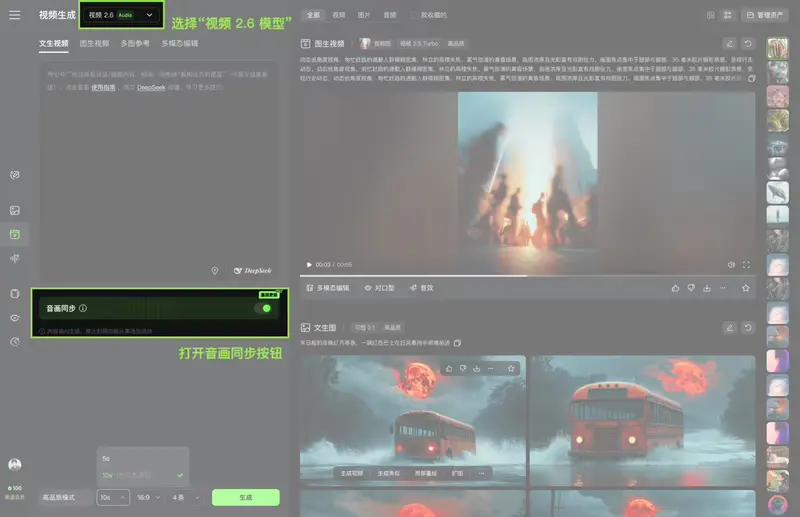
支持四大典型创作场景
- 单人独白
商品展示、生活 Vlog、新闻播报、演讲视频等,AI 自动匹配口型、语调与背景氛围。 - 旁白解说
适用于商品讲解、赛事解说、纪录片或故事叙述,语音与画面节奏精准同步。 - 多人对白
支持访谈、短剧等多角色对话场景,可区分不同角色的声线与画面呈现。 - 音乐表演
包括唱歌、说唱、多人合唱、乐器演奏等,音画节奏统一,氛围感强。
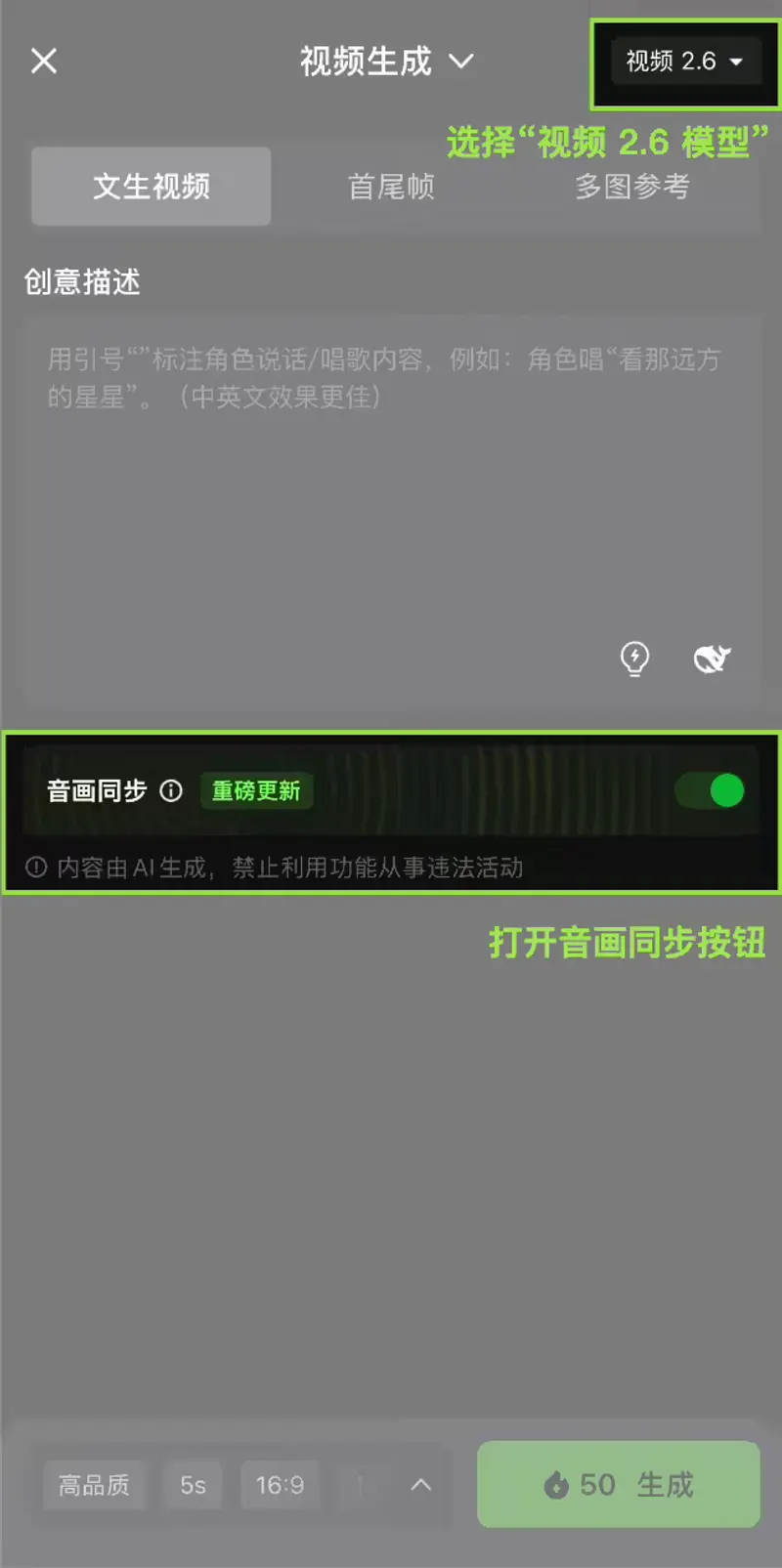
“音画由您全盘掌控”
可灵 AI 强调,新模型不仅自动化程度高,也保留充分的用户控制权:
- 可调节语音风格(如正式、亲切、激昂);
- 可指定音效类型(如城市街道、森林鸟鸣、咖啡馆背景);
- 可控制画面动态节奏与镜头语言。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











