
9月9日,WAVE SUMMIT 深度学习开发者大会 2025 在北京举行。百度首席技术官、深度学习技术及应用国家工程研究中心主任 王海峰 在会上正式发布 文心大模型 X1.1 ——一款在事实性、指令遵循和智能体能力上实现显著提升的深度思考模型。

目前,用户可通过 文心一言官网 和 文小言 APP 使用文心大模型 X1.1。同时,该模型已正式上线 百度智能云千帆平台,面向企业客户与开发者全面开放调用,助力AI应用高效落地。
文心X1.1:基于强化学习的深度思考升级
文心大模型 X1 系列定位于“深度思考”场景,旨在提升模型在复杂任务中的推理与决策能力。X1.1 是基于 文心大模型 4.5 进一步训练而来,通过引入更先进的训练框架,实现了多维度能力跃升。
核心升级:迭代式混合强化学习训练框架
X1.1 采用全新的 迭代式混合强化学习训练框架,包含两大关键技术路径:
- 混合强化学习(Hybrid RL)
同时优化通用任务(如问答、摘要)与智能体任务(如工具调用、多步决策),提升模型在真实场景中的综合表现。 - 自蒸馏数据的迭代式生产与训练
利用高质量自生成数据持续反哺模型训练,在不依赖大量人工标注的前提下,稳步提升模型整体效果。
能力提升数据(对比 X1):
| 能力维度 | 提升幅度 |
|---|---|
| 事实性 | +34.8% |
| 指令遵循 | +12.5% |
| 智能体任务表现 | +9.6% |
这些改进使得 X1.1 在复杂任务中更具可靠性,尤其适用于需要高准确率与强逻辑推理的企业级应用。
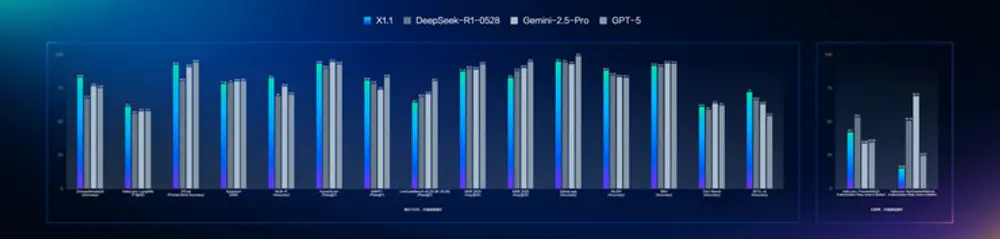
权威评测表现:超越 DeepSeek R1,对标国际顶尖水平
在多个权威基准测试中,文心大模型 X1.1 展现出强劲竞争力:
- 整体表现超越 DeepSeek R1-0528,在多项任务中取得领先;
- 在与 GPT-5 和 Gemini 2.5 Pro 的对比中,效果基本持平,部分任务甚至略有优势。
这一成绩标志着国产大模型在核心能力上已具备与国际顶尖模型同台竞技的实力。
飞桨文心协同优化:底层框架全面升级
文心大模型的持续进化,离不开底层深度学习平台的支持。大会同期,百度发布了 飞桨 PaddlePaddle 核心框架 3.2 版本,在训练效率、硬件适配与生态工具链方面实现全面升级。
飞桨 3.2 主要更新:
- 大模型训练优化:支持更高效的分布式训练策略,降低长序列训练显存开销;
- 硬件适配增强:新增对国产AI芯片的深度支持,提升异构计算兼容性;
- 生态工具链升级:
- ERNIEKit:大模型开发套件,支持快速微调与任务定制;
- FastDeploy:高效部署套件,覆盖端、边、云全场景推理加速。
飞桨与文心的联合优化,形成了“框架 + 模型 + 工具”的完整技术闭环,显著缩短从研发到落地的周期。
生态规模持续扩大:2333万开发者,76万企业
随着技术能力的不断提升,飞桨文心生态也进入规模化发展阶段。
截至最新数据:
- 生态开发者总数达 2333 万
- 服务企业数量达 76 万家
这一数字不仅体现了飞桨在国内深度学习领域的广泛影响力,也反映出大模型技术正在加速渗透各行各业,推动产业智能化升级。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











