OpenAI 于 2 月 13 日发布了 GPT-5.3-Codex-Spark,这不仅是其最新的编程辅助模型,更标志着一个重要的技术转折点:这是 OpenAI 首次在生产环境中部署基于非 Nvidia 芯片的 AI 模型 。该模型运行在 Cerebras Systems 的晶圆级引擎(WSE-3)上,专为需要超低延迟响应的“实时编程”场景而生。

为什么需要 Codex-Spark?
现有的强大 AI 编程模型擅长处理复杂的、长时间运行的任务,但在开发者进行快速迭代——如编辑代码片段、即时重构或调试时——模型响应的延迟会打断心流。Codex-Spark 的目标就是解决这个问题。它并非追求最强的推理能力,而是追求最快的交互速度,在保持足够智能的同时,将响应时间压缩到极致。
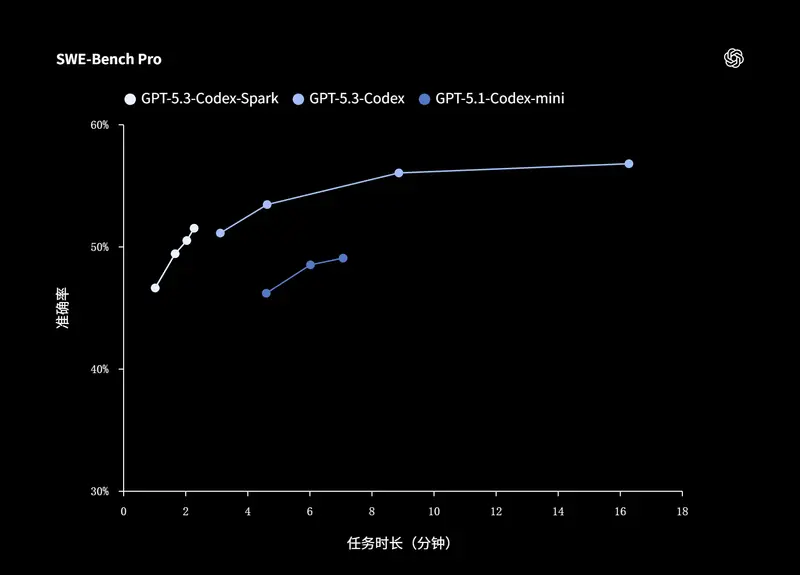
据官方介绍,Codex-Spark 在优化配置下,每秒可处理超过 1000 个令牌,并已向 ChatGPT Pro 订阅用户开放研究预览 。
Cerebras 芯片:为低延迟而生
支撑 Codex-Spark 极速体验的,是 Cerebras 的第三代晶圆级引擎(WSE-3)。与传统由多个 GPU 组成的集群不同,Cerebras 将数十万个 AI 核心集成在一块巨大的单晶圆上,并配备超大容量的片上内存。这种独特的架构极大减少了数据在芯片间的搬运,从根本上降低了推理延迟,使其成为交互式工作负载的理想选择。
OpenAI 强调,此举并非要取代 Nvidia。公司表示,Nvidia 的 GPU 仍是其训练和通用推理基础设施的“基石”,而 Cerebras 则是针对特定低延迟场景的有力补充。未来,两种硬件甚至可能在同一工作负载中协同,以达到最佳性能。
不只是模型快,整个链路都在优化
为了让“实时”名副其实,OpenAI 不仅优化了模型本身,还对整个请求-响应链路进行了深度改造:
- 重写推理栈:精简了客户端与服务器间的流式传输逻辑,重构会话初始化流程。
- 启用 WebSocket:默认为 Codex-Spark 启用 WebSocket 长连接,将单次往返开销降低 80%,首字延迟缩短 50%。
这些底层优化确保了开发者在与模型协作时,能获得近乎即时的反馈。
当前可用性与未来规划
目前,Codex-Spark 研究预览版已面向 ChatGPT Pro 用户开放,可在 Codex 应用、CLI 及 VS Code 扩展中使用。它支持 128k 上下文窗口,仅接受文本输入,并拥有独立的速率限制 。
OpenAI 将 Codex-Spark 视为其“双模式互补”战略的第一步:一方面有能处理数天长任务的强大模型,另一方面有专注于即时交互的轻量模型。未来,这两种模式将深度融合,让开发者既能享受快速的交互反馈环,又能将耗时任务无缝委托给后台智能体。
随着模型能力的不断增强,交互速度已成为新的瓶颈。Codex-Spark 的出现,正是为了打通这一瓶颈,让 AI 编程助手真正融入开发者的日常编码节奏。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











