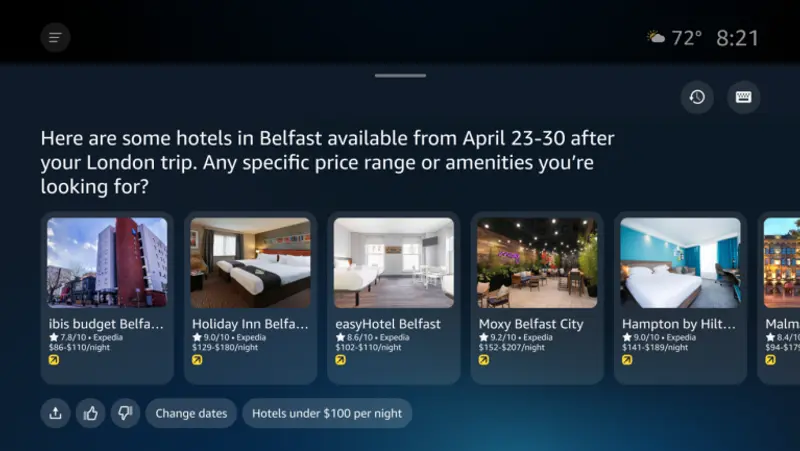
Runway 最新推出其下一代动作捕捉模型 Act-Two,在生成质量、动作一致性及细节表现力方面实现了重大突破。
该模型能够基于一段驱动表演视频和一个参考角色图像,自动生成高质量的动画输出,涵盖头部、面部表情、上半身及手部动作,甚至能保留背景信息,实现更加自然和沉浸的角色驱动效果。
Act-Two 相较于 Act-One 的关键升级
Act-Two 是 Runway 动作捕捉技术的一次全面进化,在多个核心维度上实现了显著提升:
| 维度 | Act-One | Act-Two |
|---|---|---|
| 保真度 | 支持基本动作捕捉 | 显著增强的运动细节还原能力 |
| 一致性 | 有时出现帧间抖动 | 多帧间保持高度一致性 |
| 支持部位 | 仅限身体动作 | 支持头部、面部、上半身、手部完整追踪 |
| 角色适配性 | 有限风格适应 | 可适配多种艺术风格与环境设定 |
| 背景处理 | 不支持背景保留 | 能够保留并融合原始背景 |
这意味着,无论是写实风格还是卡通风格的角色,Act-Two 都能准确地将你的表演转化为高质量的动画内容。
核心功能亮点
🎭 单一视频输入,多维动画输出
只需提供:
- 一段你的“表演”视频(可为手持拍摄或录屏)
- 一张目标角色的参考图(可以是照片、插画或3D渲染)
即可自动完成从表演到动画的转换过程,适用于虚拟偶像、游戏角色、广告制作、影视特效等多种场景。
👤 全面支持头部、面部、手部动作捕捉
Act-Two 弥补了第一代模型在面部表情和手部细节上的不足:
- 精准捕捉微笑、皱眉、眨眼等微表情
- 支持手指弯曲、手势变化等精细动作
- 上半身姿态同步自然流畅
🌍 自动保留背景,提升场景真实感
不同于以往模型仅关注角色本身,Act-Two 还能识别并保留原视频中的背景元素,使生成结果更具沉浸感和现实意义。
🧠 更强的风格泛化能力
无论你的角色是写实风格、动漫风、Q版还是抽象设计,Act-Two 都能根据输入视频生成符合角色特征的动画,极大拓宽了应用场景。
应用场景广泛,助力创意表达
Act-Two 适用于以下使用场景:
- 🎬 影视与短视频创作:快速将演员表演转化为动画角色
- 🎮 游戏开发:为角色创建自然的动作库,减少手工调优时间
- 🖼️ 虚拟主播 / 数字人:实时驱动 AI 角色进行直播或互动
- 📺 广告与营销:高效生成高质量角色动画,降低制作门槛
- 🎨 创意实验:探索不同风格与表演之间的动态映射关系
当前可用性
目前,Act-Two 已向所有 Runway 企业客户 和 创意合作伙伴 开放访问权限。
官方表示将在未来几天内逐步向公众开放,让更多创作者有机会体验这一全新模型的强大能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











