Ollama 宣布与 OpenAI 合作,将后者最新发布的开放权重模型 gpt-oss-20b 和 gpt-oss-120b 正式引入其平台。
这是 OpenAI 自 GPT-2 以来首批开放权重语言模型,而 Ollama 的集成使其成为首个原生支持 gpt-oss 系列的本地推理平台。
开发者现在可通过 Ollama 在本地设备上运行这两款高性能模型,用于推理、代理任务和定制化开发,无需依赖云端 API。
为什么这次集成意义重大?
OpenAI 发布 gpt-oss 系列,标志着其在开源战略上的重大转向。但仅有模型权重并不足以实现广泛落地——部署工具链的完善程度,决定了开发者能否真正用起来。
Ollama 的作用正在于此:它提供了一个极简、高效、跨平台的本地运行环境,让 gpt-oss 模型从“可下载”变为“可运行”。
此次合作不仅是技术对接,更是生态协同的体现:
- OpenAI 提供最先进的开放模型
- Ollama 提供最便捷的本地化部署方案
- 英伟达提供硬件级性能优化
三方合力,推动 AI 模型真正走向“设备端优先”。
核心功能:为本地代理工作流而生
gpt-oss 模型在 Ollama 中具备完整能力支持,专为构建本地 AI 代理(Agent)而优化。
✅ 原生代理能力
- 函数调用:支持结构化工具调用
- Python 代码执行:在沙盒环境中运行代码
- 网页搜索:Ollama 提供可选内置搜索功能,增强模型对最新信息的访问能力
- 结构化输出:支持 JSON Schema 输出,便于集成到应用中
✅ 完整链式推理(CoT)
开发者可查看模型的完整思考过程,便于调试、验证逻辑与增强信任。
⚠️ 注意:CoT 内容可能包含幻觉或不安全语言,不应直接展示给最终用户。
✅ 可配置推理力度
支持三种推理模式:
- 低:低延迟,适合简单任务
- 中:平衡性能与速度
- 高:深度推理,适合复杂规划
通过系统提示即可切换,灵活适配不同场景。
✅ 支持微调
gpt-oss 采用 Apache 2.0 许可证,允许:
- 在私有数据上进行参数高效微调(PEFT)
- 构建定制化 AI 助手
- 商业化部署,无专利限制
为开发者提供了真正的“所有权”。
技术亮点:MXFP4 量化,原生支持
OpenAI 对 gpt-oss 模型采用了创新的 MXFP4 量化格式:
- MoE 权重(占总参数 90% 以上)被量化为 4.25 位
- 显著降低内存占用
- gpt-oss-20b 可在 16GB 内存设备运行
- gpt-oss-120b 可适配 单块 80GB GPU
Ollama 原生支持 MXFP4 格式,无需用户手动量化或转换。其新引擎已开发专用内核,确保推理效率与精度。
Ollama 团队还与 OpenAI 合作,对照其参考实现进行基准测试,确保输出质量一致。
两款模型,两种定位
| 模型 | 参数 | 定位 | 部署要求 |
|---|---|---|---|
| gpt-oss-20b | 21B | 低延迟、边缘设备、快速迭代 | 16GB RAM,消费级笔记本 |
| gpt-oss-120b | 117B | 高性能、生产级、复杂推理 | 单块 80GB GPU |
- gpt-oss-20b 适合本地开发、私有化部署、移动端集成;
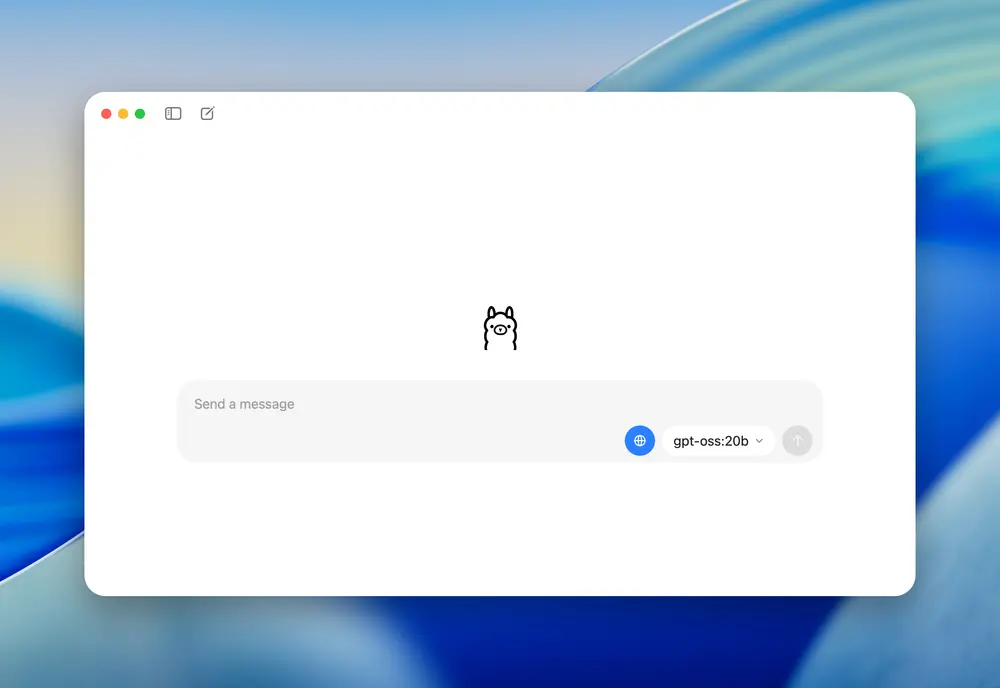
- gpt-oss-120b 适合企业级代理系统、RAG 引擎、自动化工作流。
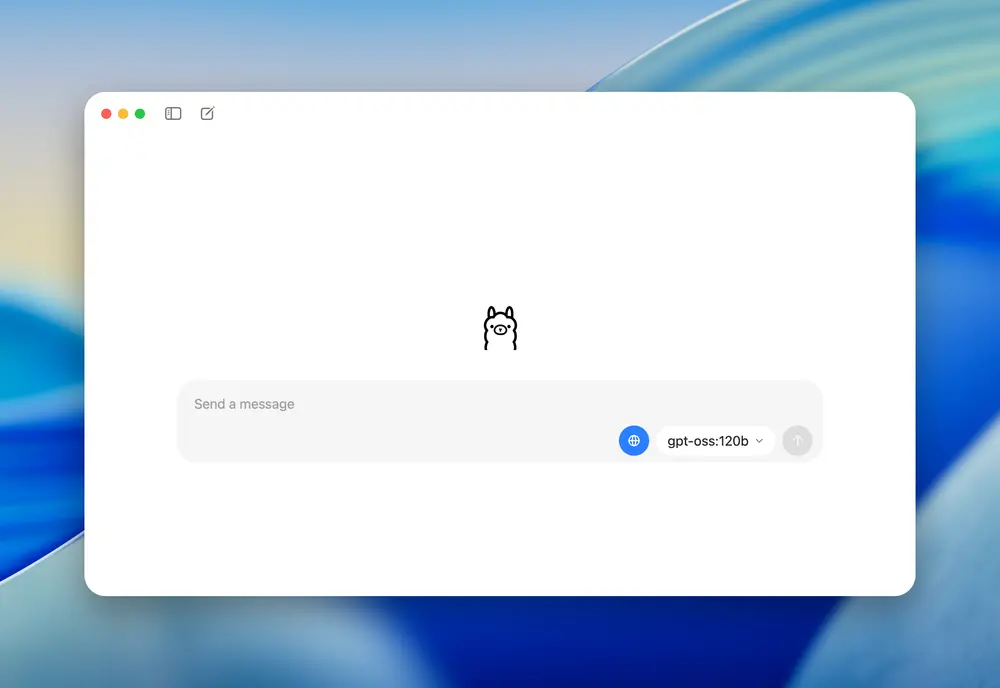
英伟达深度合作:RTX 用户性能再提升
为充分发挥硬件潜力,英伟达与 Ollama 正在深化合作,优化 gpt-oss 模型在以下平台的性能:
- 英伟达 GeForce RTX 系列消费级显卡
- RTX PRO 专业显卡
这意味着:
- 更高的推理吞吐量
- 更低的延迟
- 更高效的显存利用
RTX 用户将能以更高性能运行这些先进模型,进一步推动“本地大模型”普及。

如何开始使用?
只需两步:
- 下载 最新版本 Ollama
- 在终端运行:
# 运行 20B 模型
ollama run gpt-oss:20b
# 运行 120B 模型
ollama run gpt-oss:120b
模型也可通过 Ollama 桌面应用直接下载和管理。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











