
在 AI 音乐领域,生成一段“听起来像歌”的音频已不再困难。真正的挑战在于:如何让 AI 创作一首有结构、有情绪、有叙事感的完整作品。
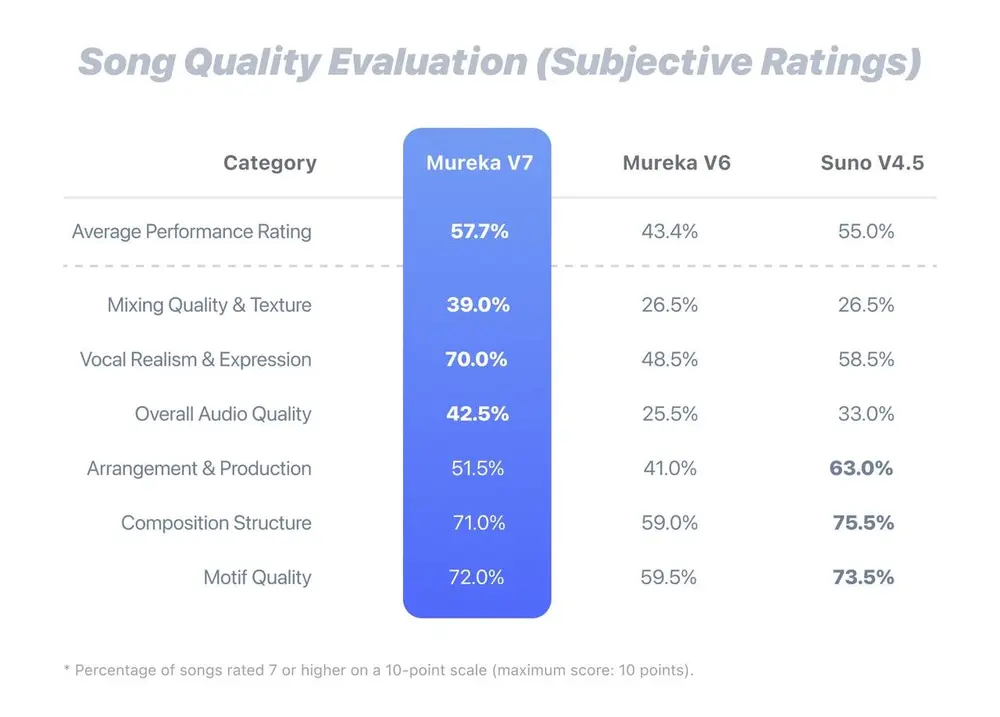
昆仑天工最新发布的 Mureka V7,正朝着这个方向迈出关键一步。它由全新的 MusiCoT(Music Chain-of-Thought,音乐思维链)框架驱动,在旋律连贯性、结构完整性和情感表达上实现显著提升,整体表现已基本追平当前行业标杆 Suno 4.5。
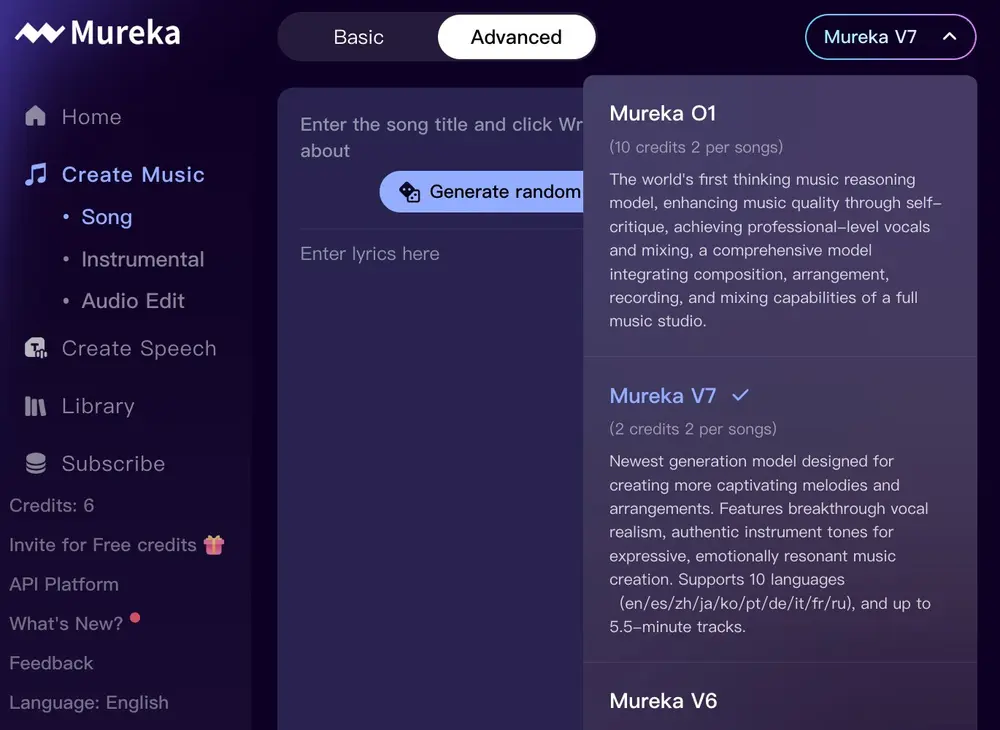
更值得关注的是,V7 版本首次原生集成 Text-to-Speech(TTS)功能,支持语音定制与声音克隆,将 AI 音乐的能力边界拓展至播客、旁白、影视配音等多元场景。
核心升级:从“拼接音符”到“构思作品”
传统 AI 音乐模型往往聚焦于局部音符的连贯性——确保每一段旋律听起来自然。但这种“逐段生成”的方式,容易导致整首曲子缺乏统一的结构与情绪推进。
Mureka V7 的突破在于其底层框架:MusiCoT。
MusiCoT:让 AI 像作曲家一样思考
MusiCoT 的核心思想是:先规划,再创作。
在生成音频前,模型会先完成以下“作曲规划”:
- 结构设计:确定前奏、主歌、副歌、桥段、尾声的布局
- 情感曲线:规划整首曲子的情绪起伏(如从平静到激昂)
- 乐器编排:决定各段落的配器与音色组合
只有在完成整体构思后,模型才开始填充具体旋律与和声。
这使得生成的音乐不再是“片段的堆叠”,而是具备起承转合的完整作品。
参考音频生成:更智能的风格理解
Mureka V7 对“参考音频”(Reference Audio)的支持也全面升级。
用户上传一段参考曲目后,模型不仅能匹配其节奏与调性,更能理解:
- 情绪氛围(如忧郁、欢快、紧张)
- 编曲风格(如电子、摇滚、管弦)
- 段落结构(如主副歌切换方式)
这一能力特别适用于:
- 电影/游戏配乐的风格匹配
- 音乐混音与再创作
- 快速生成符合品牌调性的背景音乐
重磅新增:原生集成TTS
本次更新最实用的功能之一,是 TTS 的深度集成。
Mureka V7 不再只是一个“作曲工具”,更是一个端到端的声音内容生成平台。
✅ 支持三大语音模式:
| 模式 | 说明 |
|---|---|
| 预设语音 | 内置多种高质量语音角色(如男声、女声、童声) |
| 提示控制语音 | 通过文本提示设计语音风格(如“温暖的中年男声,略带沙哑”) |
| 声音克隆 | 上传 30 秒以上人声样本,即可克隆专属音色 |
应用场景拓展:
- 生成带人声演唱的完整歌曲
- 制作 AI 旁白与播客节目
- 为短视频、动画快速配音
所有功能均在同一平台内完成,无需切换工具。
为什么 Mureka V7 值得关注?
| 维度 | Mureka V7 的优势 |
|---|---|
| 音乐结构 | 首次实现“先构思后生成”,显著提升连贯性 |
| 创作逻辑 | 接近人类作曲流程,更适合叙事性内容 |
| 功能集成 | TTS 原生支持,减少工作流切换 |
| 可控性 | 通过提示与参考音频实现精准风格控制 |
| 工业化能力 | 设计上支持规模化生成,适合内容平台与创作者生态 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











