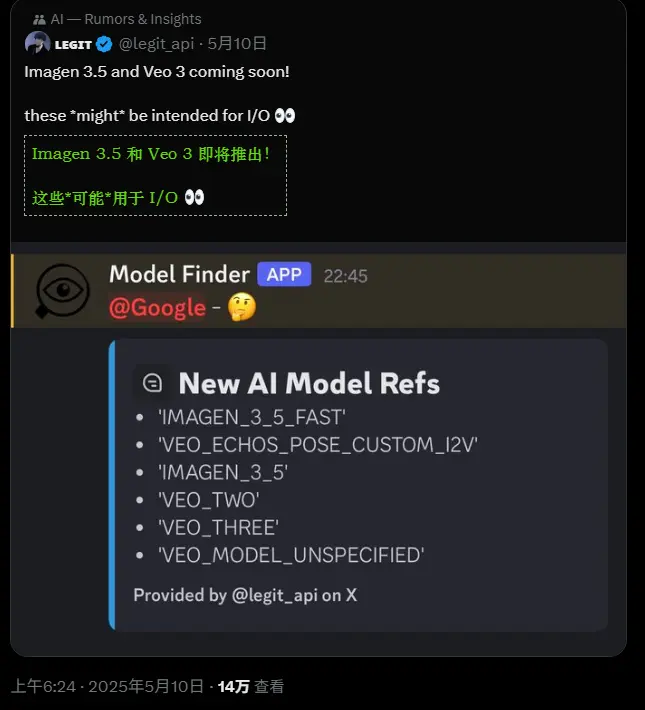
谷歌正计划在2025年5月20日的年度I/O开发者大会上发布其下一代图像和视频生成模型,包括备受期待的Veo 3和Imagen 4系列。这一消息引发了科技界的广泛关注,预览标识如veo-3.0-generate-preview、imagen-4.0-generate-preview-05-20和imagen-4.0-ultra-generate-exp-05-20的曝光,进一步证实了这些新模型的技术进展和分阶段发布的策略。
双轨策略:Veo与Imagen各司其职
从命名和功能划分来看,谷歌似乎延续了其双轨策略:
- Veo系列专注于视频生成,旨在为用户提供高质量、连贯性更强的动态内容创作能力。
- Imagen系列则专注于逼真的照片合成和风格化图像生成,满足用户对静态视觉内容的多样化需求。
此次更新中,“预览”和“Ultra”标签的出现尤其引人注目。“预览”版本可能代表基础能力的公开测试版,而“Ultra”版本则暗示更高级的功能或性能优化,适合专业创意工作者和商业用途。这种多层次的产品布局,表明谷歌正在努力满足不同用户群体的需求,从个人创作者到企业客户都能找到适合自己的工具。

技术升级:更高的保真度与多模态整合
虽然关于新模型的具体能力尚未完全披露,但从Imagen 3到Imagen 4、Veo 2到Veo 3的过渡可以推测,谷歌在以下几个方面进行了显著改进:
- 更高的保真度:无论是静态图像还是动态视频,新模型可能会提供更逼真的细节表现,减少以往生成内容中的模糊或失真现象。
- 更长的生成序列连贯性:对于视频生成而言,帧间连贯性和叙事流畅性是关键。Veo 3可能在这些方面实现了突破,使其更适合制作复杂的动态内容。
- 多模态整合:谷歌近期将AI生成媒体整合到NotebookLM和Gemini等产品中的尝试,表明其正在构建一个统一的多模态框架。用户或许能够通过同一模型无缝切换文本、图像和视频创作,从而提升工作效率。
分阶段发布:实验室测试与正式上线
从命名中的时间戳(如05-20)可以看出,谷歌可能采取分阶段发布策略。这意味着Imagen 4和Veo 3可能会先通过谷歌实验室进行早期测试,随后逐步扩展到更广泛的用户群体。这种方式不仅有助于收集用户反馈,还能降低大规模部署的风险。
不过,目前尚不清楚这些工具在发布时的具体可用范围。它们可能会以实验室邀请制的形式推出,也可能直接面向公众开放,甚至仅限于企业层级使用。无论如何,谷歌显然希望通过这些新模型重新确立其在生成媒体领域的领先地位。
竞争压力下的战略布局
近年来,OpenAI、Anthropic和xAI等公司在生成式AI领域频频发力,给谷歌带来了不小的竞争压力。尤其是在图像和视频生成方面,市场对更高质量和更高效工具的需求不断增长。在此背景下,谷歌加速推出Imagen 4和Veo 3,不仅是对竞争对手的回应,更是其在生成媒体领域技术实力的一次集中展示。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











