
在刚刚落幕的 Create 2025 开发者大会 上,百度发布了一系列重磅 AI 技术成果,展示了其在人工智能领域的技术实力与商业化落地能力。从性能与成本双突破的文心大模型 4.5 Turbo 和 X1 Turbo,到能够重塑直播生态的高说服力数码主播技术,百度不仅为开发者提供了更高效、低成本的工具,还为多个行业注入了新动能。
百度创始人李彦宏在会上强调,AI 应用的核心在于“找对场景、选对模型并善于调优”,才能创造持久价值并渗透更多行业场景。这一理念贯穿了本次大会的技术发布,展现了百度对 AI 未来发展的深刻洞察。
文心大模型 4.5 Turbo 与 X1 Turbo:性能与成本双赢
针对当前大模型普遍存在的模态单一、幻觉高、速度慢及成本昂贵等问题,百度推出了 文心大模型 4.5 Turbo 和 X1 Turbo,旨在为开发者提供更具性价比的选择。

1. 文心 4.5 Turbo:多模态能力全面升级
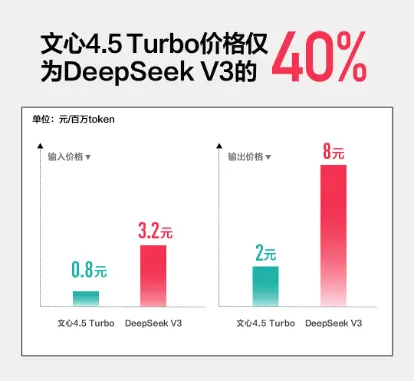
文心 4.5 Turbo 是一款强化多模态能力的模型,支持文本、图像等多种模态输入。其基准测试平均分达到 77.68,超越了 GPT-4o 的 72.76。相比前代文心 4.5,新版本在推理速度上显著提升,同时大幅降低了使用成本:
输入价格:降至 0.8 元/百万 token(降幅达 80%)。 输出价格:仅为 3.2 元,是 DeepSeek-V3 成本的 40%。
李彦宏指出,多模态模型将成为未来主流,纯文本模型市场将逐步萎缩。文心 4.5 Turbo 的推出标志着百度在这一领域的领先地位。
2. 文心 X1 Turbo:深度思考能力再进化
文心 X1 Turbo 基于 4.5 Turbo 进一步优化,增强了思维链能力,在问答、创作、逻辑推理和工具调用等方面表现更优。整体性能领先于 DeepSeek R1 和 V3 最新版,且价格更具竞争力:
输入价格:1 元/百万 token。 输出价格:4 元,仅为 DeepSeek-R1 的 25%。
李彦宏表示,通过优化模型结构与训练方式,百度实现了性能提升与成本降低的双赢,为开发者提供了更灵活的选择。他还强调,只要选对基础模型并善于微调,应用即可保持长期竞争力。
百度计划通过开源与 API 服务进一步降低开发者门槛,推动 AI 技术在教育、医疗、金融等领域的广泛应用。
高说服力数码主播:超拟真体验重塑直播生态
百度慧播星平台推出的 高说服力数码主播 技术成为大会另一亮点。依托文心大模型的剧本生成与多模驱动能力,这一技术实现了数码主播在表情、语气、动作及情绪转换上的超拟真表现,甚至超越传统真人主播体验。
核心优势
一键克隆:用户仅需录制 2 分钟直播视频,即可生成专属数码主播,极大降低了内容创作门槛。 AI 大脑赋能:数码主播内置“AI 大脑”,能根据直播间实时热度与转化数据动态调整互动策略。例如: 自动切换镜头、调用图片或视频素材。 灵活调度助播、场控等角色,实现“一人即营销团队”的高效运营模式。
商业价值
在电商直播、游戏推广及消费品营销等场景中,数码主播展现出巨大潜力。它们不仅能根据商品特点自动生成吸引人的口播脚本,还能通过自然的情绪表达提升观众购买意愿。例如,在电商直播中,数码主播可以根据商品特点生成专业化的脚本,并结合实时数据调整互动策略,从而显著提高转化率与用户黏性。
百度慧播星的技术突破得益于其多模态模型的深度整合,结合语音合成、动作捕捉及情感计算,使数码主播不仅能模拟真人口播效果,还能根据场景需求生成专业化内容。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











