Beyond Memorization:通过不同的架构和训练方法来提升大语言模型多步推理能力阿联酋MBZUAI、莫斯科物理技术学院、莫斯科AIRI和伦敦数学科学研究所的研究人员推出Beyond Memorization,通过不同的架构和训练方法来提升大语言模型(LLMs)多步推理能力。作者们...新技术# Beyond Memorization# 大语言模型6个月前0930
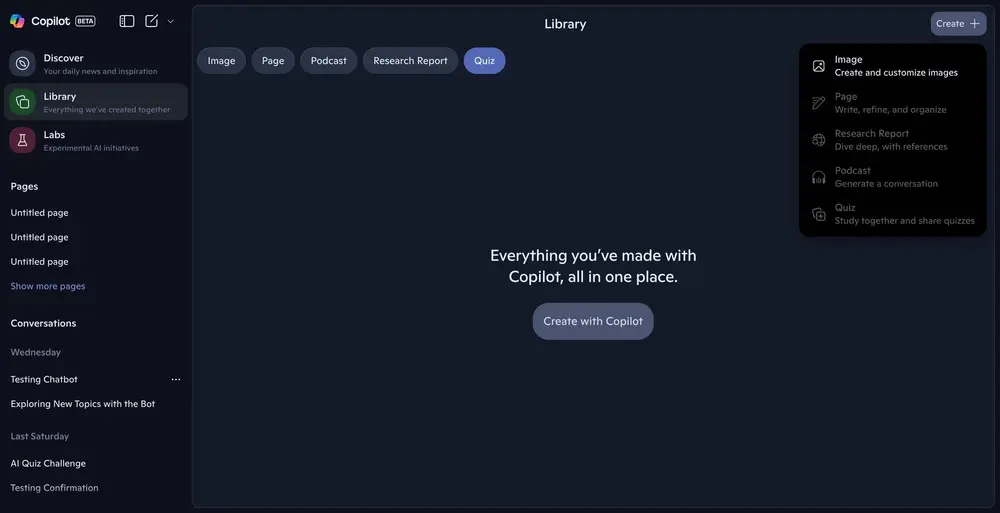
微软测试Copilot库新类别:新增播客、文档、测验分类,强化内容管理能力微软正持续扩充Copilot的功能边界,近期针对即将推出的Copilot库展开测试,计划在现有图像分类之外,新增“播客”“研究文档”“测验”三大专用类别。这一调整旨在将Copilot库打造成“数字内容...早报# Copilot# 微软6个月前0770
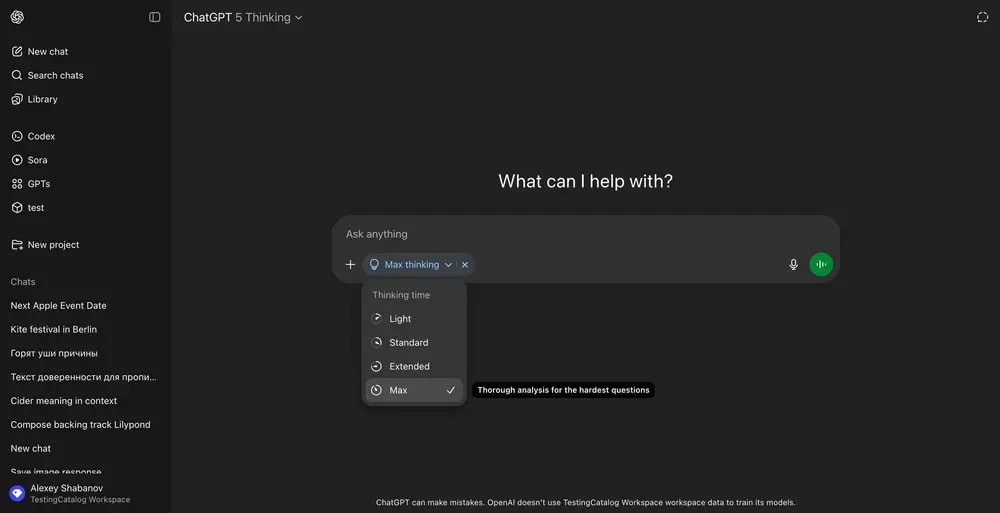
OpenAI 测试两大新工具:可控“思考努力”与对话分支,提升交互灵活性OpenAI 正持续迭代 GPT-5 平台功能,近期针对 Pro、Enterprise 及部分团队用户,测试两项核心工具:一是优化后的“努力选择器”,可精准控制模型的计算投入深度;二是全新的“对话分支...早报# GPT-5# OpenAI6个月前0880
印度首富穆克什·安巴尼联手谷歌与Meta,为印度构建AI骨干在印度首富穆克什·安巴尼的最新战略蓝图中,AI不再只是技术升级,而是一场国家级的基础设施建设。 在信实工业(Reliance Industries)第48届年度股东大会上,安巴尼正式宣布成立新子公司 ...百科# Reliance Intelligence# 信实工业# 穆克什·安巴尼6个月前01370
Meta 143亿美元押注Scale AI遇挫:高管离职、转向竞品,超级智能实验室陷混乱6月,Meta曾以143亿美元大手笔投资数据标注巨头Scale AI,并将其CEO亚历山大·王(Alexandr Wang)及多名高管纳入旗下Meta超级智能实验室(MSL),试图加速AI超级智能研发...早报# Meta# Scale AI6个月前0960
OpenAI 押注 gpt-realtime 抢占语音AI市场:以指令遵循与自然表现力突破企业级需求在竞争日益激烈的语音AI赛道,OpenAI 推出全新模型 gpt-realtime,试图以“精准遵循复杂指令”和“自然富有表现力的语音”两大核心优势,切入企业级应用市场。该模型将通过全面开放的 Rea...早报# gpt-realtime# OpenAI6个月前0810
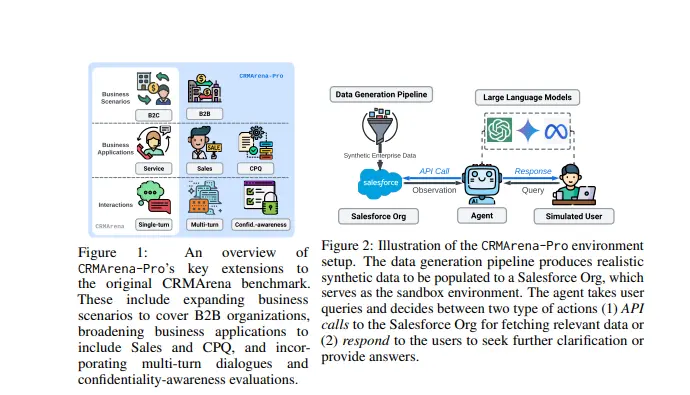
应对 95% AI 试点失败!Salesforce 发布 CRMArena-Pro,模拟真实业务环境企业AI的一大痛点是“演示时亮眼,落地时拉胯”——MIT最新报告显示,95%的企业生成式AI试点无法推进至生产阶段,Salesforce自身研究也发现,仅依赖大语言模型(LLM)的AI代理在复杂业务场...新技术# CRMArena-Pro# Salesforce6个月前01510
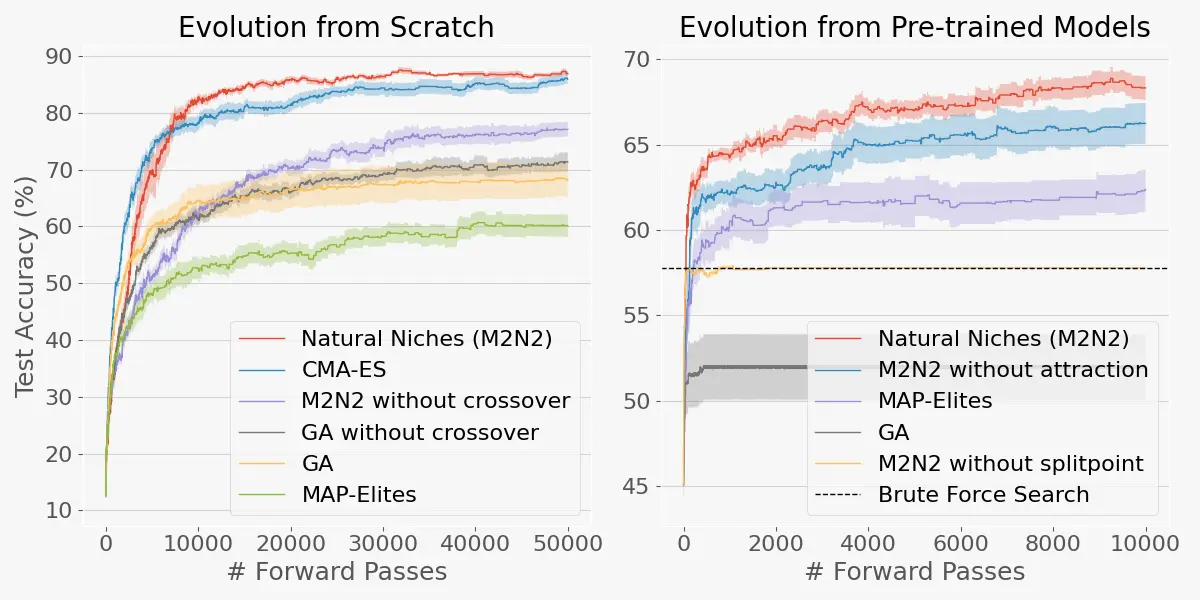
Sakana AI 新算法 M2N2:无需重新训练,让 AI 模型 “进化” 得更强日本 AI 实验室 Sakana AI 近期推出一项突破性技术 ——自然生态位模型合并(M2N2) ,彻底改变了 AI 模型的优化逻辑。与传统依赖昂贵算力和海量数据的 “重新训练”“微调” 不同,M2...新技术# M2N2# Sakana AI6个月前01370
扎克伯格的AI野心引发Meta震荡:新老势力碰撞、重组不断,离职潮暗流涌动为实现“个人超级智能”的AI野心,Meta CEO马克·扎克伯格正推动公司二十年来最剧烈的领导层重组。这场以“砸钱抢人”为起点的变革,却引发了一系列连锁反应:新聘AI高管威胁离职、资深员工批量出走、内...早报# Meta# 扎克伯格6个月前0900
FFmpeg 8 正式发布:集成 Whisper 实现离线字幕、GPU 加速编码,还兼容古老格式知名多媒体处理工具 FFmpeg 近日推出第八个主要版本 ——FFmpeg 8.0,代号 “Huffman”(致敬 1952 年发明的霍夫曼无损压缩算法)。此次更新不仅带来了用户期待的 “自动加字幕...早报# FFmpeg 8.0# Whisper6个月前02700
Vivaldi CEO 强硬表态:坚决禁止浏览器集成生成式 AI,网页该由人类主导“不在我的浏览器里!” 挪威浏览器厂商 Vivaldi 的 CEO 乔恩・冯・泰茨纳(Jon von Tetzchner)近期再次强化立场 —— 坚决拒绝在自家浏览器中集成生成式 AI。在行业纷纷追逐...早报# Vivaldi# 浏览器6个月前0750
微软发布两款自研AI模型:MAI-Voice-1落地多产品,MAI-1-preview开启公开测试微软AI(Microsoft AI,简称MAI)正式推出两款自研AI模型——语音生成模型MAI-Voice-1与基础模型MAI-1-preview。其中,MAI-Voice-1已率先整合至Copilo...早报# MAI-1-preview# MAI-Voice-1# 微软6个月前0810