七组家庭就ChatGPT涉自杀与妄想症案件追加起诉OpenAI周四,七组家庭对OpenAI提起诉讼,指控该公司过早发布GPT-4o模型且未设置有效防护机制。其中四起诉讼涉及ChatGPT与家庭成员自杀事件的关联,另外三起则指控ChatGPT强化用户有害妄想,部分...早报# ChatGPT# OpenAI4个月前0180
谷歌在 Mixboard 测试标注与背景移除功能,强化视觉工作流谷歌正在为其 AI 视觉实验平台 Mixboard 测试一系列新功能,包括图像背景移除与高级标注工具,进一步拓展其在教育、演示和产品设计场景中的应用潜力。 Mixboard 是一款基于结构化画布的 A...早报# Mixboard# 谷歌4个月前0200
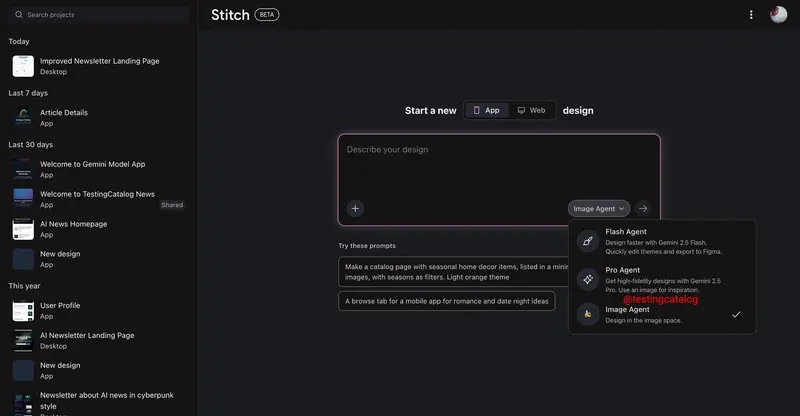
谷歌正为 Stitch 推出图像代理与智能导出功能,强化设计-开发协同谷歌正在为 AI 设计工具 Stitch 推出一系列关键升级,深化其在 UI/UX 设计与工程开发工作流中的整合能力。本次更新聚焦于两大核心功能:图像代理模式与项目文档自动生成,并扩展导出生态,标志着...早报# Stitch# 谷歌4个月前0490
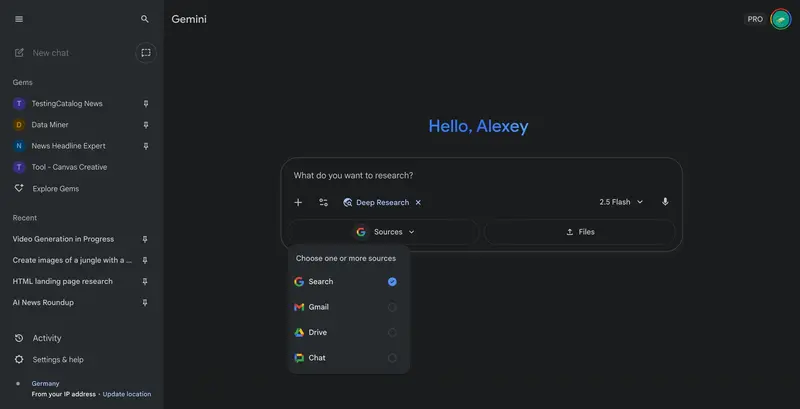
谷歌将 Gemini Deep Research 与 Workspace 数据深度集成谷歌近日正式推出 Gemini Deep Research 的重大升级:支持直接调用用户在 Google Workspace 中的私有数据,包括 Gmail 邮件、Drive 文档(含 PDF、电子表...早报# Gemini Deep Research# 谷歌4个月前0150
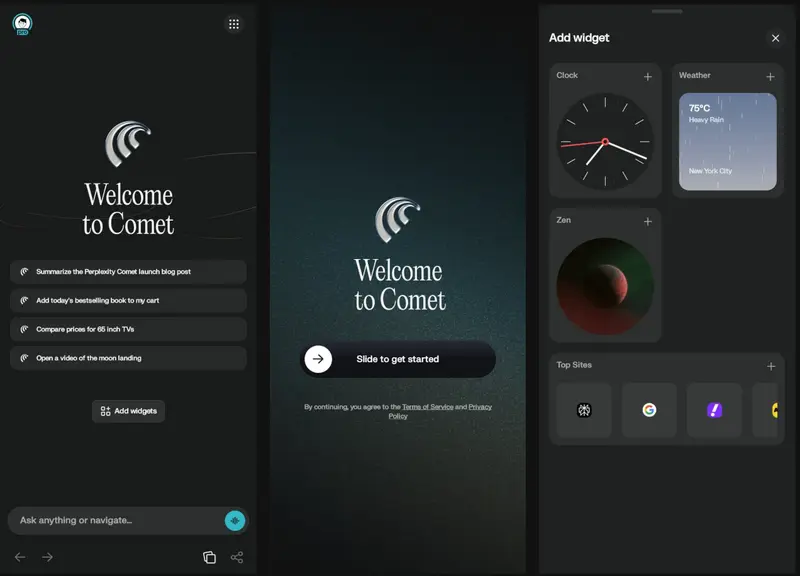
Perplexity 开始测试 Comet Android 浏览器Perplexity 正在对其全新移动浏览器 Comet for Android 进行有限的 beta 测试,目前仅向部分选定用户推送邀请。此次测试标志着其 AI 驱动浏览体验正式从桌面端延伸至移动端...早报# Comet# Perplexity4个月前0200
OpenAI 或将推出 GPT-5.1 Thinking 模型,直面 Gemini 3 Pro 竞争近期,有迹象表明 OpenAI 正在为 GPT-5.1 系列模型的发布做最后准备,其中首个亮相的变体 GPT-5.1 Thinking 已在 ChatGPT 网站的前端或后端组件中被识别。该模型被明确...早报# Gemini 3 Pro# GPT-5.1 Thinking# OpenAI4个月前0780
谷歌云发布第七代 TPU Ironwood 与新型 Axion Arm 实例2025 年 11 月 6 日,谷歌云正式推出其第七代张量处理单元(TPU),并同步发布基于 Arm 架构的Axion 虚拟机与裸金属实例。这两项新产品面向 AI 实验室、SaaS 平台以及正从模型训...硬件# TPU# 谷歌云4个月前0470
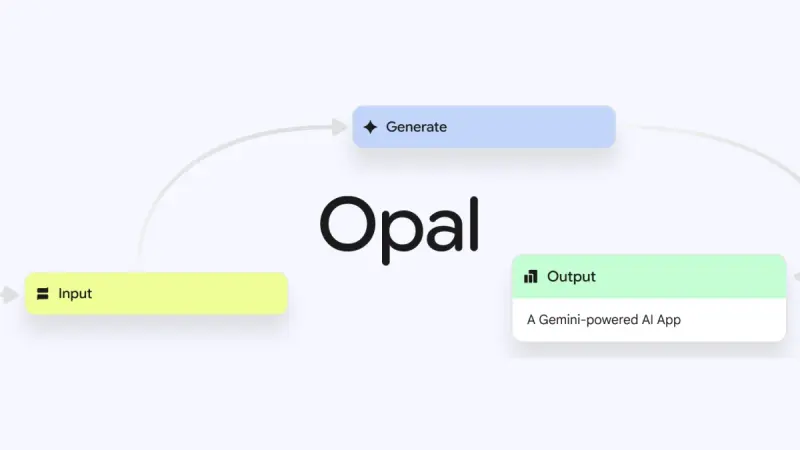
谷歌无代码AI迷你应用创建工具Opal启动全球推广谷歌实验室推出的无代码AI迷你应用构建器Opal,已从16个国家扩展至160多个国家。该工具仍被谷歌标记为"实验性产品",因此功能可能存在不完善之处。 Opal于7月24日率先在美国上线,10月7日拓...早报# Opal# 谷歌4个月前0300
亚马逊推出 Kindle Translate:为独立作者提供免费 AI 翻译工具亚马逊于周四宣布,为其 Kindle Direct Publishing(KDP)平台上的作者推出一项新功能:Kindle Translate —— 一项基于 AI 的自动翻译服务,旨在帮助作者将作品...早报# Kindle Translate# 亚马逊4个月前0400
OpenAI 明确拒绝政府担保:1.4万亿美元算力投入如何融资?上周,OpenAI 首席财务官 Sarah Friar 在《华尔街日报》活动中表示,希望美国政府为公司数据中心建设贷款提供“backstop”——即政府担保。若公司违约,纳税人将承担损失。这一措辞迅速...早报# OpenAI4个月前03100
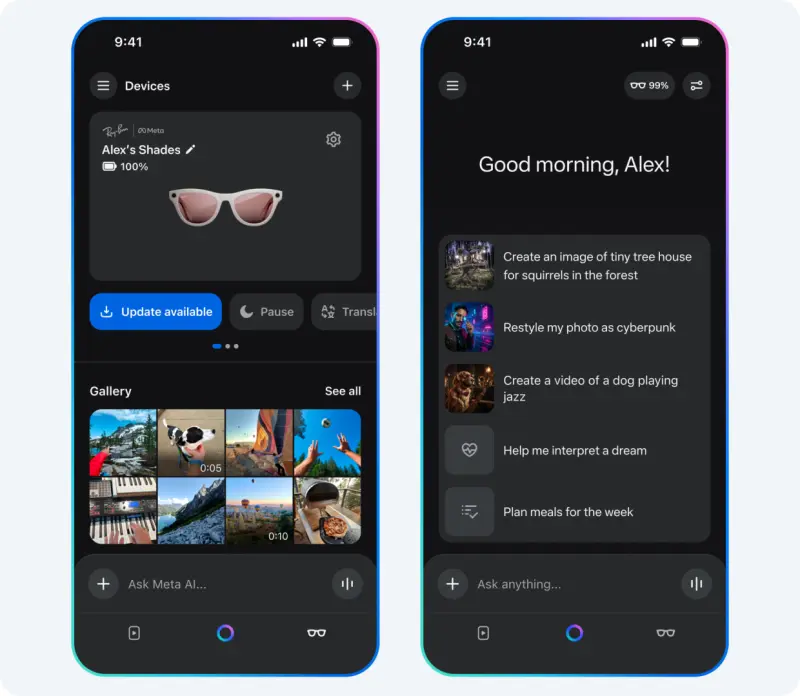
Meta 在欧洲推出 AI 生成视频Vibes,聚焦创作与 remixMeta 于本周四宣布,其 AI 生成视频功能 Vibes 正式在欧洲地区上线,作为 Meta AI 应用的一部分。 Vibes 是一个独立的短视频内容流,所有视频均由 AI 生成,用户可浏览、创作...早报# Meta# Vibes4个月前01000
People Inc. 与微软达成 AI 内容许可协议,同时谷歌搜索流量腰斩美国最大媒体出版商之一 People Inc.(前身为 Dotdash Meredith)近日宣布,已与微软签署一项新的 AI 内容许可协议。这是继去年与 OpenAI 达成合作后,该公司在 AI 授...早报# People# 微软4个月前0220