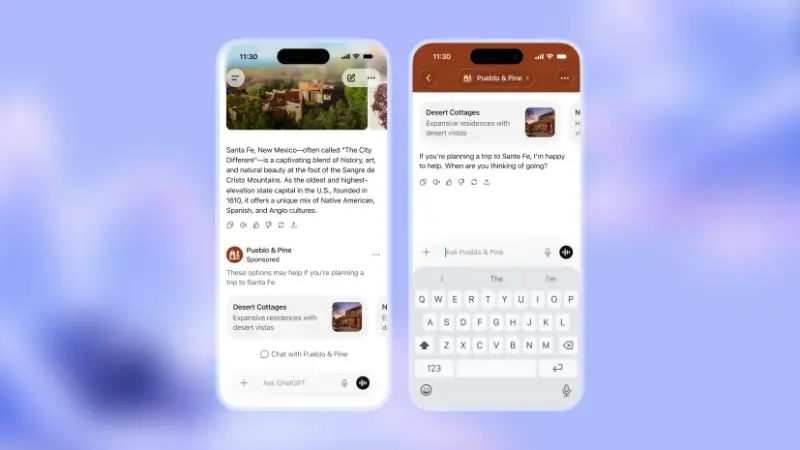
ChatGPT 即将上线广告:免费用户将看到购物链接,Plus 用户不受影响OpenAI 正式宣布:ChatGPT 将引入广告。 从未来几周起,美国地区的免费用户和 ChatGPT Go(8 美元/月)订阅用户,将在聊天界面底部看到明确标注为“赞助”或“广告” 的产品推荐...早报# ChatGPT# OpenAI# 广告2个月前01040
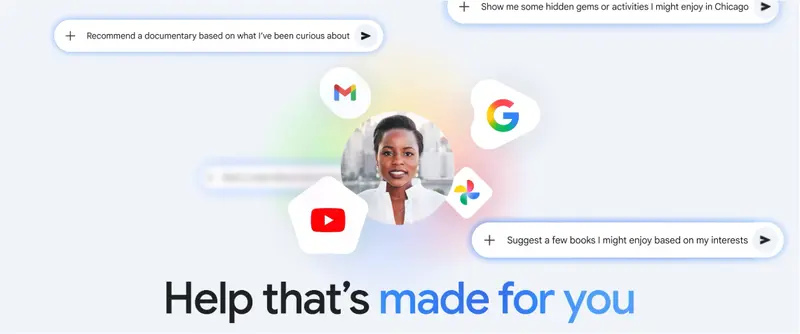
Gemini 推出“个人智能”测试版:能看你的邮件和照片,主动帮你解决问题谷歌本周宣布,其 AI 助手 Gemini 将上线一项名为 “个人智能”(Personal Intelligence) 的新功能。该功能允许 Gemini 在用户授权后,安全地访问 Gmail、Goo...早报# Gemini# 个人智能2个月前0280
字节跳动旗下 AI 编程助手Trae 一周年福利:免费领 600~800 次「超快请求」额度字节跳动旗下 AI 编程助手 Trae 迎来上线一周年。为感谢用户支持,官方推出限时周年庆活动:登录 Trae 国际版,即可免费领取额外「Fast Request」(快速请求)额度,用于加速代码生成与...早报# AI 编程助手# Trae# 字节跳动2个月前0310
谷歌Veo 3.1重磅更新:参考图生成竖屏视频,支持4K超分赋能创作者在AI视频生成领域持续发力的谷歌,于2026年推出了Veo 3.1版本更新,不仅强化了“从素材到视频”的核心功能,还新增竖屏视频输出、升级4K超分辨率技术,并且将工具无缝接入YouTube创作者生态...早报# Veo 3.1# 谷歌2个月前0310
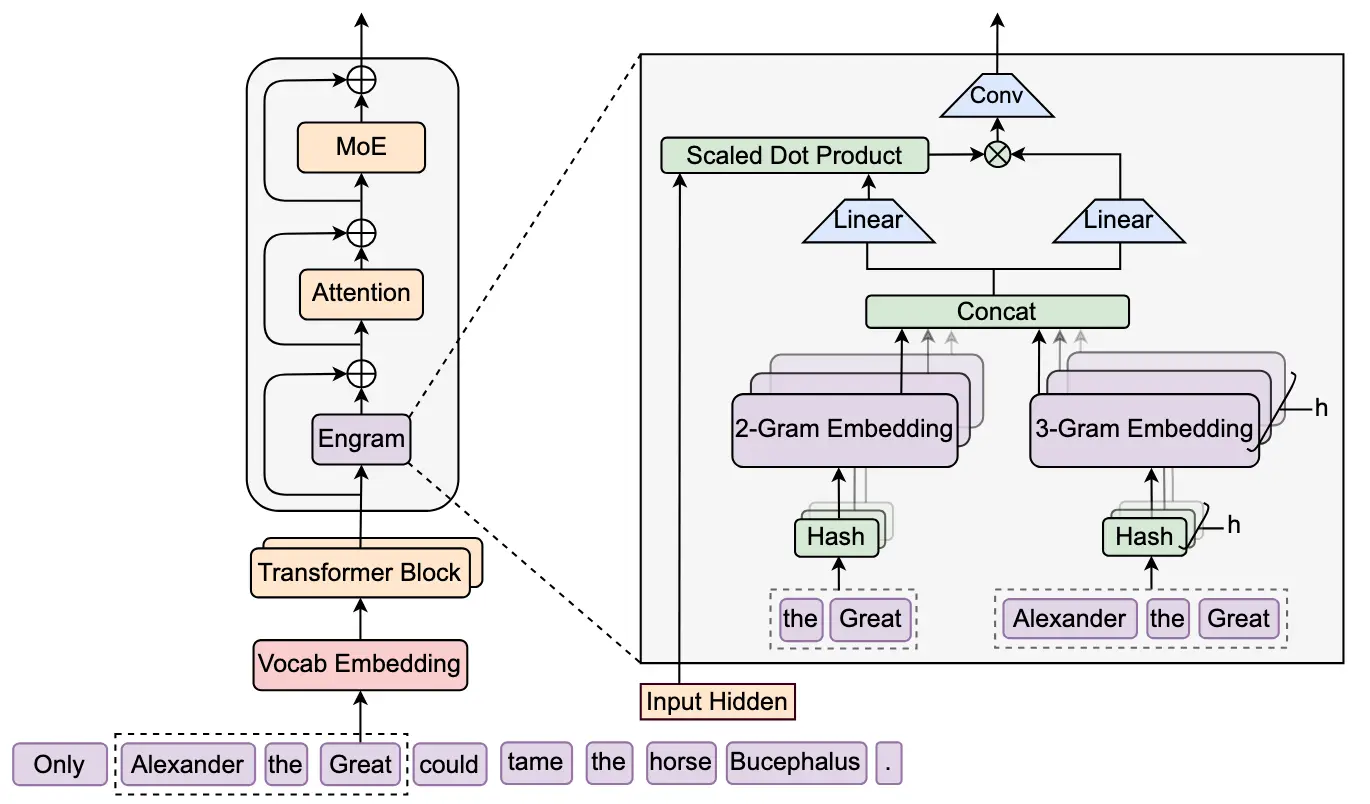
告别 GPU 算力浪费!DeepSeek 条件记忆技术:让大模型检索静态知识更高效当企业级大语言模型(LLM)在回答“iPhone 15 的电池容量是多少?”或“标准 NDA 条款包含哪些内容?”这类问题时,它正在动用为复杂推理设计的昂贵 GPU 计算资源——仅仅为了检索一段静态信...新技术# DeepSeek# Engram# 条件记忆2个月前0440
告别命令行!Anthropic发布Cowork:解锁Claude智能体新玩法,非开发者也能轻松上手Anthropic 正式推出一款名为 Cowork 的全新工具,该工具作为 Claude Code 的简化易用版本,内置在 Claude 桌面应用中,核心优势在于无需用户掌握编程技能,就能借助 Cla...早报# Anthropic# Claude Code# Cowork2个月前01370
苹果谷歌官宣合作:Gemini将为Siri及Apple Intelligence提供底层AI支持苹果与谷歌正式官宣达成多年期合作协议,苹果将采用谷歌的Gemini模型及云技术构建下一代基础模型,为Siri语音助手及Apple Intelligence相关功能提供底层支撑。这一合作是苹果在AI领域...早报# Gemini# 苹果# 谷歌2个月前0280
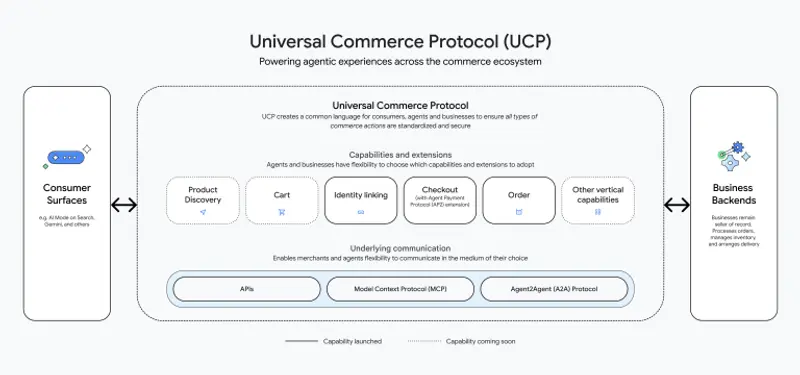
谷歌发布通用商务协议(UCP):让 AI 智能体真正“促成交易”在 2026 年全美零售联合会(NRF)大会上,谷歌联合 Shopify、Etsy、Wayfair、Target 和沃尔玛等零售巨头,正式推出 通用商务协议(Universal Commerce Pr...早报# UCP# 谷歌# 通用商务协议2个月前0780
继 Health 后,OpenAI 将推出 Jobs 智能体,切入职业服务赛道继推出 ChatGPT Health 后,OpenAI 正在内部测试一款名为 ChatGPT Jobs 的新智能体,旨在为用户提供简历优化、职位匹配、职业规划等一站式求职支持。 目前该功能仍处于“内部...早报# Jobs 智能体# OpenAI2个月前0190
xAI 即将推出 Grok Build:本地优先的 Vibe Coding 智能体继 Grok 4.2 发布在即的消息后,xAI 正在为开发者准备一项新工具:Grok Build——一个专注于 Vibe Coding(氛围编程) 的智能体系统,旨在将 Grok 深度融入本地开发工作...早报# Grok Build# xAI2个月前0760
Anthropic 双线封杀:第三方工具遭技术拦截,xAI 等竞品被切断 Claude 使用权Anthropic 近期启动双重管控行动:一方面通过技术防护封杀伪装官方客户端的第三方工具,另一方面以商业条款为由,切断 xAI 等竞争对手对 Claude 模型的未授权访问。这一系列操作不仅冲击了 ...早报# Anthropic# Claude2个月前0900
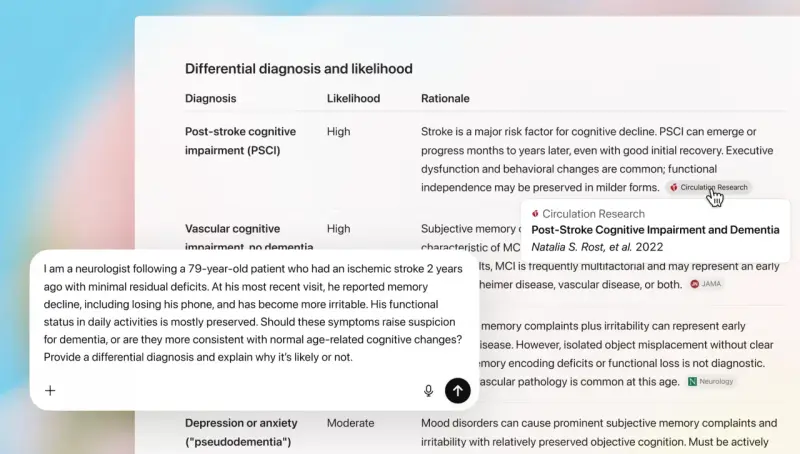
OpenAI 推出符合 HIPAA 规范的 "医疗版 ChatGPT",搭载 GPT-5 模型昨日,OpenAI 宣布推出 ChatGPT for Health,这是一个专注于健康与保健的专用体验。ChatGPT Health 能够连接主流的医疗记录与健康应用程序,以提供更个性化、更优质的回答...早报# OpenAI# OpenAI for Healthcare2个月前0260