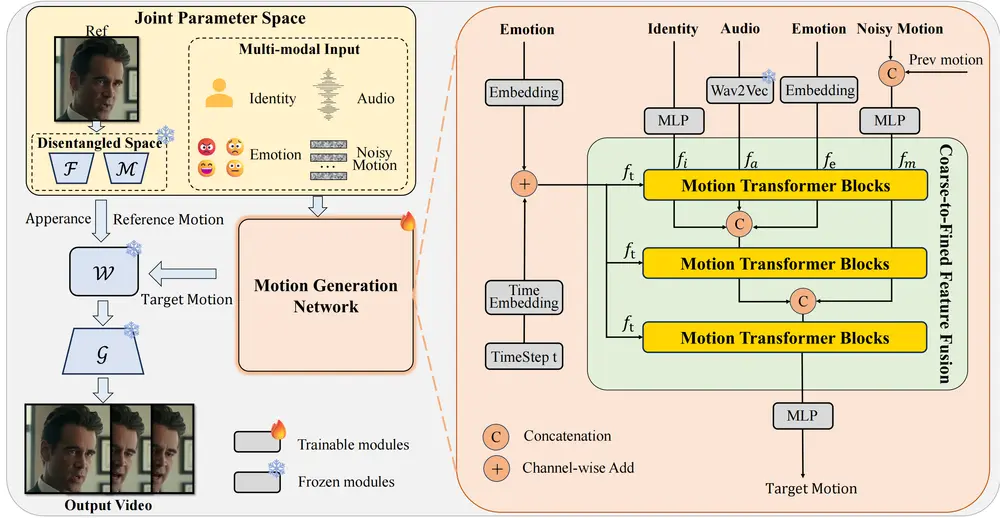
多模态扩散架构MoDA:用于生成具有任意身份和语音音频的“会说话的头像”阿里达摩院、浙江大学、湖畔实验室的研究人员推出多模态扩散架构MoDA,用于生成具有任意身份和语音音频的“会说话的头像”(talking head)。 项目主页:https://lixinyyang.g...视频模型# MoDA# 多模态6个月前01120