谷歌 Opal 重磅升级:Gemini 3 Flash 驱动“自主智能体”,一句话生成自动化工作流在“氛围编程”(Vibe Coding)浪潮席卷全球的今天,谷歌再次加码。周二,谷歌宣布为其无代码应用构建平台 Opal 引入了一项革命性功能:自主智能体(Autonomous Agents)。 借助...早报# Opal# 谷歌1个月前0390
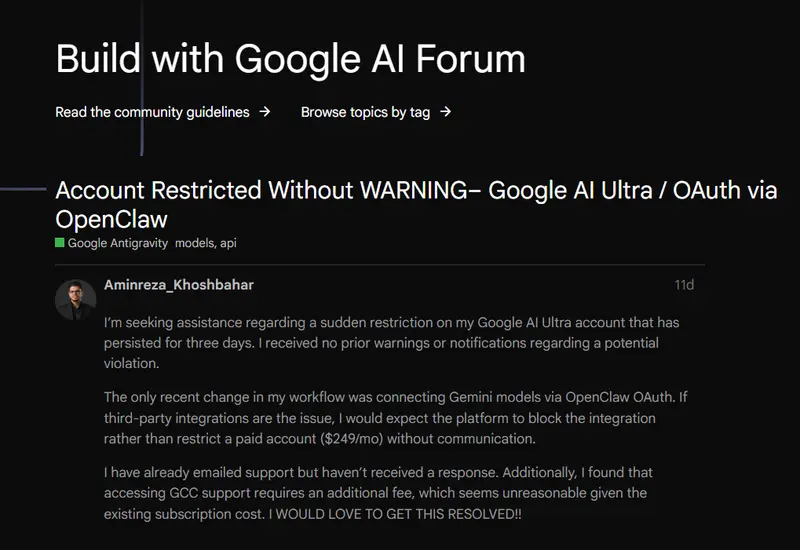
谷歌突袭封禁 OpenClaw:每月 250 美元订阅户遭“连坐”,AI 套利时代终结对于支付了每月 249.99 美元订阅谷歌 AI Ultra 服务的用户来说,没有任何预警,没有详细的解释,甚至没有一封正式的邮件通知,大量用户发现他们通过第三方工具 OpenClaw 访问 Gemi...早报# OpenClaw# 反代# 谷歌1个月前01230
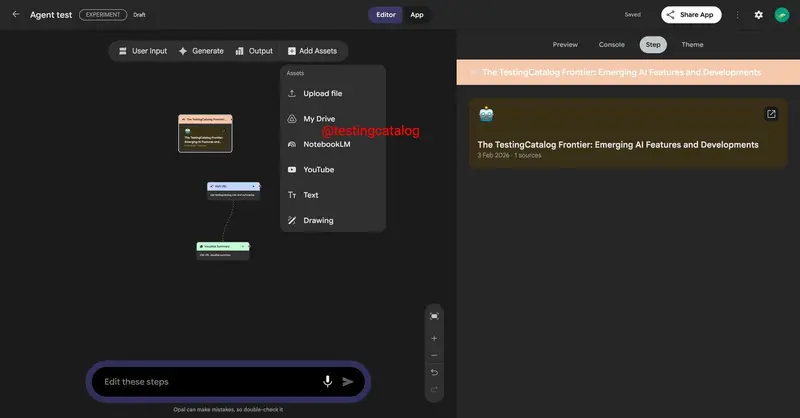
Google Opal 新测试:直接调用 NotebookLM 笔记本,让研究资料变身自动化工作流“燃料”在 AI 辅助工作的版图中,我们往往面临两个割裂的环节:研究与整理(如使用 NotebookLM)和执行与自动化(如使用 Opal)。过去,要将前者转化为后者,往往需要繁琐的手动复制粘贴或数据导出。 ...早报# NotebookLM# Opal# 谷歌1个月前0200
教师现可使用 AI 在 Google Classroom 中为学生提供反馈三年前,当生成式AI初露锋芒时,教育界曾将其视为“作弊神器”,教师们严阵以待,试图在学生利用 AI 代写论文的浪潮中守住学术诚信的底线。然而,时光流转至 2026 年,风向已悄然逆转。曾经被视为威胁的...早报# Google Classroom# 谷歌1个月前0150
谷歌发布 Gemini 3.1 Pro:专为处理最复杂任务打造的更强智能模型当简单的答案已不足以应对挑战时,我们需要更深层的智能。 上周,谷歌针对科学、研究和工程领域的现代难题,对 Gemini 3 Deep Think 进行了重大更新。今天,谷歌正式发布了支撑这些突破的升级...大语言模型早报# Gemini 3 Deep Think# Gemini 3.1 Pro# 谷歌1个月前0310
谷歌发布全新音乐模型 Lyria 3:已集成到Gemini,输入文字或图片,30 秒生成原创音乐谷歌周三正式宣布,其旗舰 AI 助手 Gemini 迎来重大功能升级——集成音乐生成能力。这一新功能由谷歌旗下 DeepMind 团队最新研发的 Lyria 3 模型驱动,目前正处于测试阶段,面向全球...早报语音模型# Lyria 3# 谷歌# 音乐模型1个月前0310
谷歌发布Gemini 3 Deep Think:解锁科研工程推理新高度谷歌正式推出Gemini 3 Deep Think的重大升级,这款专门打造的推理模式,核心目标是突破现有智能边界,精准应对科学、研究与工程领域的各类现代挑战,为相关从业者提供更具专业性的智能支持。 在...早报# Gemini 3 Deep Think# 谷歌2个月前0180
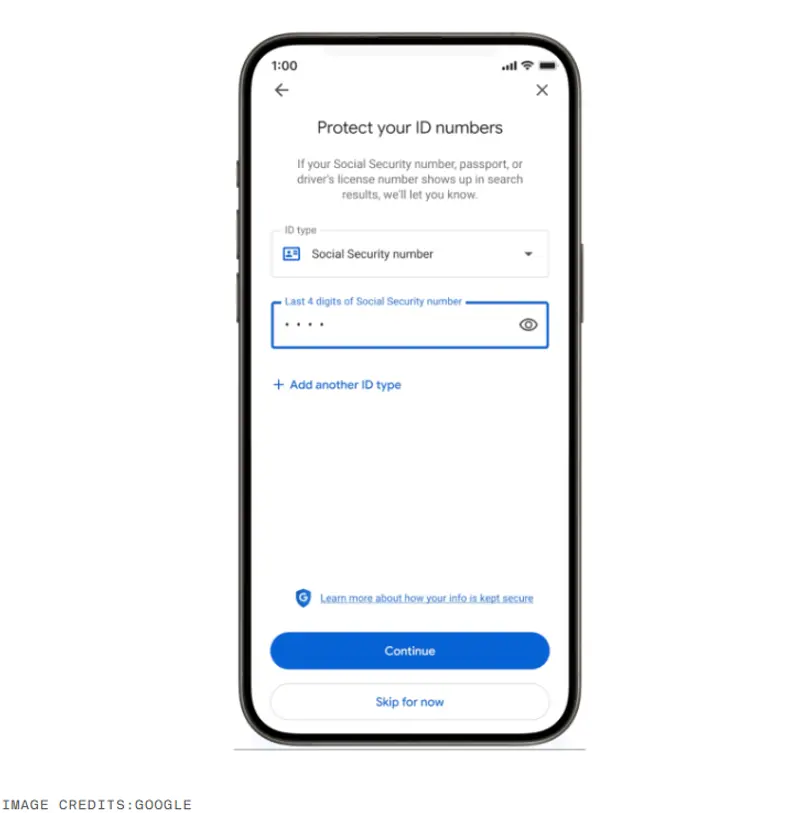
谷歌扩展“关于你的结果”工具:支持移除含身份证件和敏感个人信息的搜索结果作为“更安全的互联网日”活动的一部分,谷歌宣布对其隐私保护工具 “关于你的结果”(Results About You)进行重要升级。新版本不仅扩大了可申请移除的敏感信息范围,还简化了非自愿露骨图像的举...早报# 谷歌2个月前0200
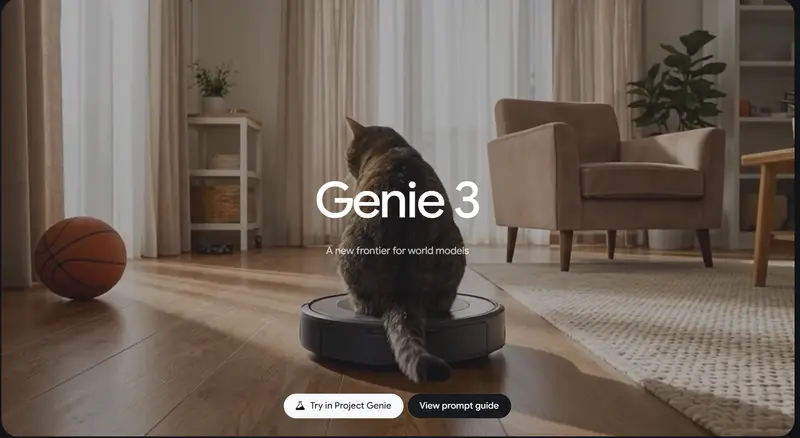
Genie 3驱动!Project Genie 上线:文本/照片生成可探索世界,限时60秒体验Google DeepMind 正式宣布,实验性AI工具 Project Genie 即日起向美国地区的 Google AI Ultra 订阅用户开放访问。这款由最新世界模型 Genie 3、图像生成...早报# Genie 3# Project Genie# 世界模型2个月前02440
Gemini 商业版提供 30 天免费试用,无需绑定支付方式Google 官方为 Gemini Business(商业版) 提供 30 天免费试用,用户可通过任意能接收验证码的邮箱注册,无需绑定信用卡或进行身份认证。该试用包含当前最新模型能力,包括 Gemin...工具# Gemini Business# 谷歌2个月前0360
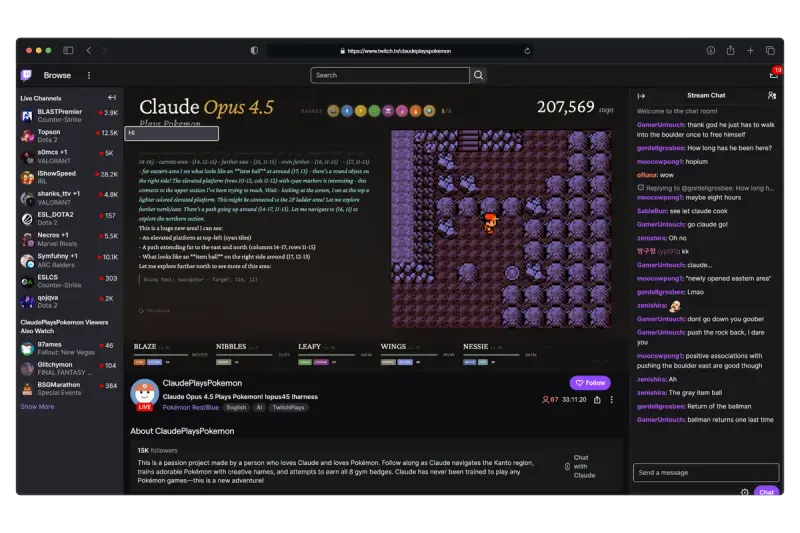
谷歌、OpenAI 和 Anthropic 正用《宝可梦》测试 AI 的真实能力在众多衡量 AI 性能的基准测试中,一个看似“非正式”的实验正在引发关注:让大模型玩《宝可梦·蓝》——这款 1996 年发布的经典 RPG 游戏,正成为评估 AI 推理、规划与长期决策能力的新试验场...早报# Anthropic# OpenAI# 谷歌2个月前0280
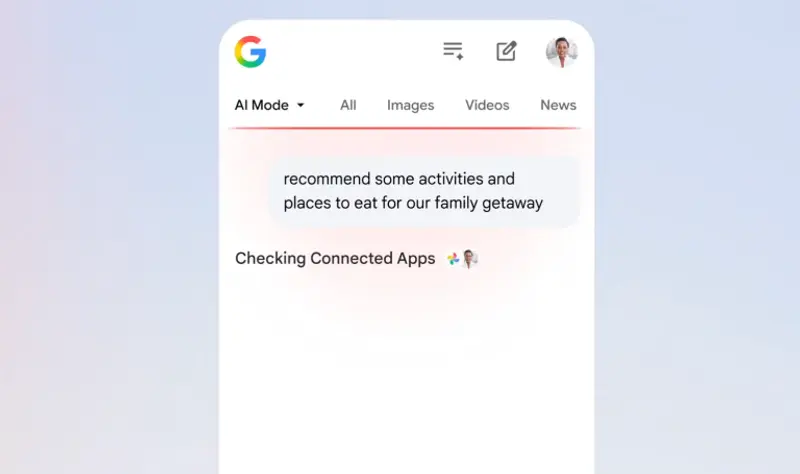
谷歌 AI 模式新增“个人智能”:可调用 Gmail 与相册数据提供定制回复谷歌正在为其 AI 搜索功能 AI 模式(AI Overviews)引入一项名为 “个人智能”(Personal Intelligence)的新能力。该功能允许 AI 在用户授权的前提下,安全地访问其...早报# AI 模式# Gmail# 个人智能2个月前0180