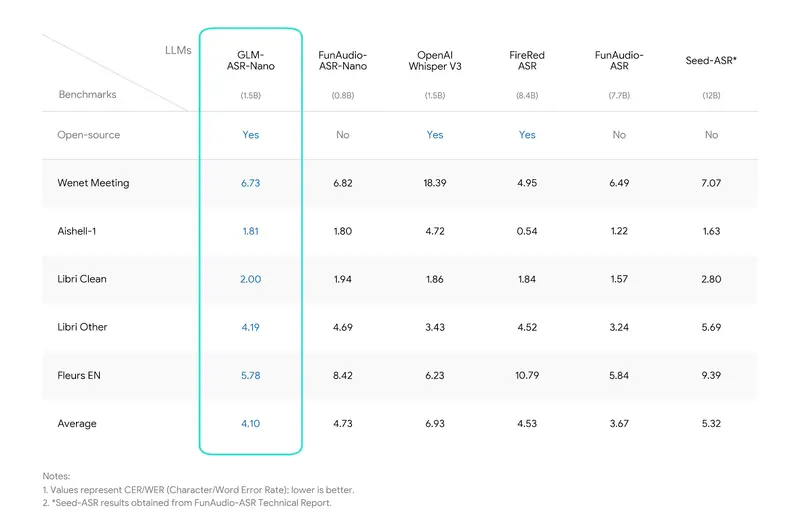
智谱AI语音识别模型GLM-ASR双版本登场:云端版精准识别多场景,Nano版开源免费,笔记本/手机均可部署智谱AI全新发布 GLM-ASR 系列语音识别模型,包含云端部署的 GLM-ASR-2512 与端侧轻量化的 GLM-ASR-Nano-2512 两个版本。其中 Nano 版以 1.5B 紧凑参数规模...语音模型# GLM-ASR-2512# GLM-ASR-Nano-2512# 智谱AI4个月前0430
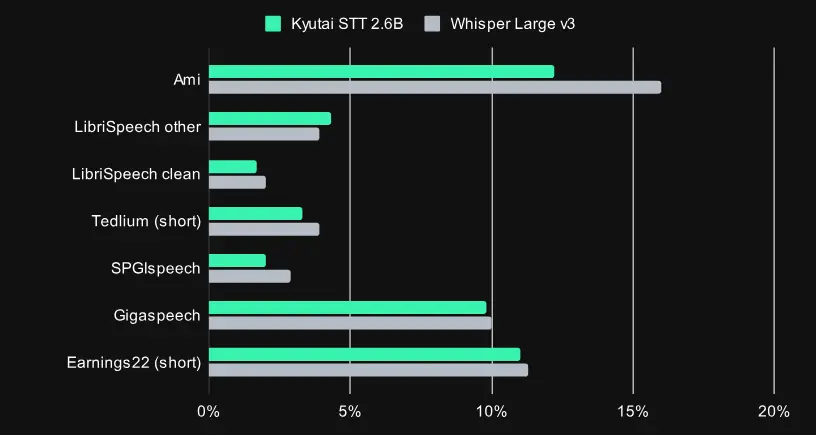
Kyutai STT:低延迟、高吞吐的流式语音识别模型,专为实时交互优化近日,Kyutai 实验室发布了一款全新的流式语音转文本(Speech-to-Text)模型——Kyutai STT,专为实时语音交互场景设计,在延迟与准确性之间实现了出色平衡,非常适合如语音助手、在...语音模型# Kyutai STT# 语音识别模型9个月前03710
Rev推出开源自动语音识别模型Reverb和话者分离模型Rev 最近宣布开源其尖端的 Reverb 自动语音识别 (ASR) 和话者分离模型。经过 200,000 小时高质量人工转录的英语语音训练,Reverb 在长篇语音识别领域中表现出色,超越了所有现有...语音模型# Reverb# 话者分离模型# 语音识别模型1年前08010
Useful开源自动语音识别 (ASR) 模型Moonshine:专门针对实时转录和语音命令处理进行了优化Useful开源了一款名为 Moonshine 的全新语音转文本模型。这款模型不仅在速度和效率上超越了目前最领先的 OpenAI 的 Whisper 模型,而且在准确率方面也达到了同等水平甚至更优。M...语音模型# Moonshine# 语音识别模型1年前07240