苹果发布多模态统一模型Manzano:能够同时理解和生成视觉内容苹果发布多模态统一模型Manzano,它能够同时理解和生成视觉内容。该模型通过结合一个混合图像标记化器和精心设计的训练方案,显著减少了在理解和生成能力之间的性能权衡。Manzano 在统一模型中实现了...多模态模型# Manzano# 多模态统一模型6个月前01120
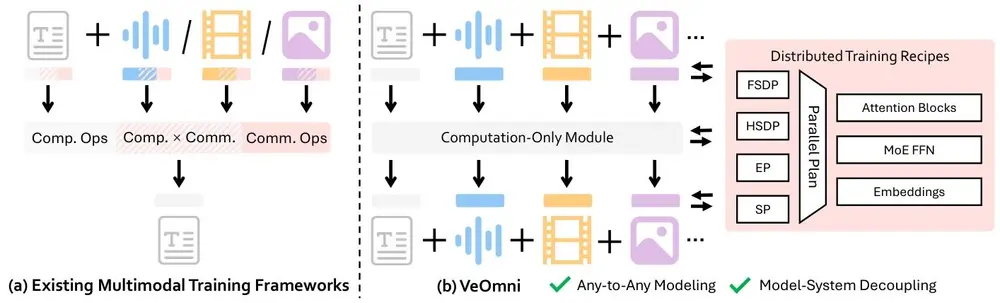
字节跳动开源 VeOmni:一个面向全模态大模型的 PyTorch 原生训练框架在大模型从“能说”向“能看、能听、能理解”演进的当下,多模态统一模型(Omni-Modal LLMs)正成为技术前沿。然而,训练一个同时处理文本、图像、语音和视频的全能模型,仍面临工程复杂、扩展困难...多模态模型# VeOmni# 多模态统一模型# 字节跳动8个月前02110
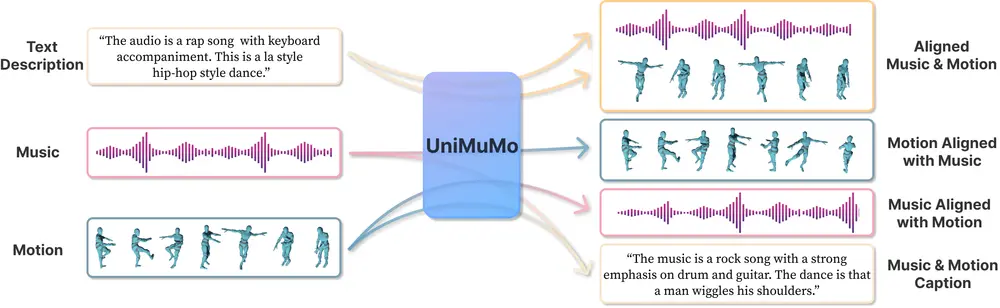
多模态统一模型UniMuMo:能够处理文本、音乐和动作(运动)数据,并在这三种模式之间生成内容香港中文大学、华盛顿大学、不列颠哥伦比亚大学、麻省大学阿默斯特分校、 MIT-IBM Watson AI 实验室和思科研究院的研究人员推出多模态统一模型UniMuMo,它能够处理文本、音乐和动作(运动...新技术# UniMuMo# 多模态统一模型1年前05300