语音 AI 正在飞速发展,但衡量它的尺子却还停留在过去。
现有的基准测试大多依赖合成语音、仅限英语的提示和脚本化的问答,这与真实世界中嘈杂、多变、充满口音的人类对话相去甚远。
大型数据标注巨头 Scale AI 正式推出了 Voice Showdown——据称是全球首个基于真实人类交互视角、通过人类偏好来评估语音 AI 的竞技场。它不仅重新定义了评估标准,更揭开了顶级模型在真实场景下的“遮羞布”。

核心机制:真实人类 vs 盲测对战
Voice Showdown 建立在 Scale 的 ChatLab 平台之上,其运作逻辑简单而残酷:
- 免费使用:用户可免费与全球最前沿的语音模型(如 GPT-4o, Gemini 等)进行自然对话。
- 随机盲测:系统偶尔会发起“对战”,将同一个真实用户语音提示发送给两个匿名模型。
- 人类投票:用户听取两个回答后,选择更自然、更准确的一个。
- 激励对齐:投票后,用户将自动切换到获胜模型继续对话。这一巧妙设计杜绝了随意投票,确保每一个偏好都真实有效。
为什么它比传统基准更可靠?
- 真声音:所有提示来自真实人类录音,而非文本转语音(TTS)合成的完美音频。
- 真多语言:覆盖 六大洲、60+ 种语言,超过 1/3 的对比发生在非英语环境。
- 真对话:81% 的提示是对话性或开放式的,无法用自动化脚本评分,人类偏好是唯一真理。
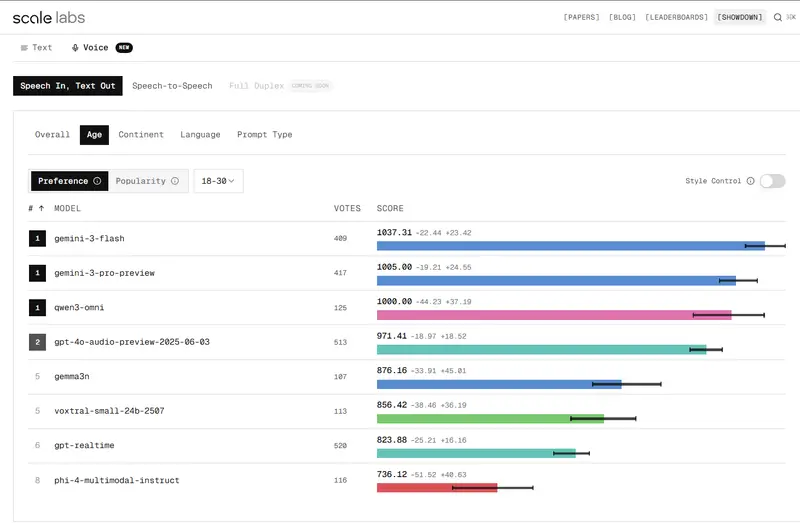
🏆 最新排行榜:Gemini 与 GPT-4o 的巅峰对决
截至 2026 年 3 月 18 日,Voice Showdown 已评估了 11 个前沿模型,结果令人意外:
🎙️ 听写模式 (Speech-to-Text)
- 🥇 冠军:Google Gemini 3 Pro 与 Gemini 3 Flash 并列第一(Elo ≈ 1043-1044)。
- 🥈 季军:GPT-4o Audio 稳居第三。
- 落后者:Gemma3n, Voxtral Small, Phi-4 Multimodal 等开源模型明显掉队。
🗣️ 语音到语音模式 (Speech-to-Speech)
- 🥇 双雄争霸:Gemini 2.5 Flash Audio 与 GPT-4o Audio 在基线排名中 statistically 并列第一。
- 风格调整后:GPT-4o Audio 凭借更自然的音色略胜一筹。
- 黑马:Grok Voice 在风格控制下跃升至接近第二;阿里 Qwen 3 Omni 在纯偏好上表现优异,超出其知名度。
💣 真实数据揭示的四大“至暗时刻”
除了排名,Voice Showdown 最大的价值在于故障诊断,它暴露了现有基准测试完全忽略的致命缺陷:
1. 🌍 多语言差距比想象中更严重
- 现象:在听写模式中,Gemini 3 几乎通吃所有语言。但在语音对话中,表现高度依赖具体语种。
- 惊人发现:GPT Realtime 1.5 在面对非英语提示时,约有 20% 的概率直接用英语回答!
- 原因:传统基准使用干净的合成语音,掩盖了模型在真实口音和噪声下的语言切换故障。
2. 🎚️ 语音选择不仅仅是审美
- 同模型不同命:同一模型的不同音色表现差异巨大。研究发现,某未命名模型中,最佳音色的胜率比最差音色高出 30%。
- 启示:音频呈现本身(语调、停顿、情感)对用户体验的影响,甚至超过了底层智能。
3. 📉 长对话中的“智力退化”
- 现象:大多数基准只测单轮。Voice Showdown 发现,随着对话轮数增加,大多数模型的胜率显著下降,难以维持连贯性和上下文记忆。
- 例外:GPT Realtime 系列是少数在后期回合中表现反而略有提升的模型。
4. ❌ 失败原因大起底
用户投票时会标记原因,数据揭示了各模型的阿喀琉斯之踵:
- Qwen 3 Omni:主要败在语音生成质量(听起来不自然)。
- GPT Realtime 1.5:主要败在音频理解故障(听不懂)及错误的语言切换。
- Grok Voice:表现均衡,但在三个维度(理解、生成、逻辑)上均有小瑕疵。
🚀 未来展望:全双工交互即将来临
目前的排行榜仍基于“回合制”交互(你说完,我说完)。但真实对话是全双工的(可以打断、重叠、实时反应)。
Scale AI 透露,旨在捕捉这些实时动态的全双工评估模式即将上线。届时,将没有任何现有基准能像 Voice Showdown 一样,通过有机的人类偏好数据来衡量真正的实时对话能力。