
Project N.O.M.A.D.
Project N.O.M.A.D. 是一个自包含、离线优先的开源知识与教育服务器。通过集成关键的离线工具、海量知识库和本地 AI 模型,N.O.M.A.D. 让你在任何时间、任何地点——即便是在完全断网的环境下——依然保持信息畅通,拥有独立的认知与解决问题的能力。
在本地部署或云端运行大模型时,最令人头疼的时刻莫过于:模型下载到一半发现磁盘不够,或者加载瞬间因显存溢出(OOM)导致进程崩溃。
传统的估算方式往往需要下载完整的权重文件,甚至实际运行一次才能知道真实的内存占用。这不仅浪费时间,更消耗宝贵的带宽和存储资源。
hf-mem 是一个用 Python 编写的超轻量级命令行工具,专为快速估算 Hugging Face Hub 上模型的推理内存需求而设计。它无需下载任何权重文件,仅需几秒即可告诉你:运行这个模型,到底需要多少显存。
⚠️ 注意:hf-mem 目前仍处于实验阶段(v1.0.0 之前)。API 和功能在不同版本间可能会发生重大变化,请在生产环境中谨慎使用,并留意版本兼容性。
hf-mem 的核心魔法在于HTTP 范围请求(Range Requests)。
它不需要下载动辄几十 GB 的 Safetensors 权重文件,而是直接通过 HTTP 协议读取远程文件的元数据(Metadata)。通过分析文件头部的结构信息,它就能精确计算出模型加载所需的内存大小。
整个工具极其精简,核心依赖仅有 httpx。
uv 运行,以获得最佳的性能体验和依赖管理。支持估算 Hugging Face Hub 上各类主流架构模型的推理需求:
使用 uvx 可以直接运行最新版本的 hf-mem,无需手动安装。
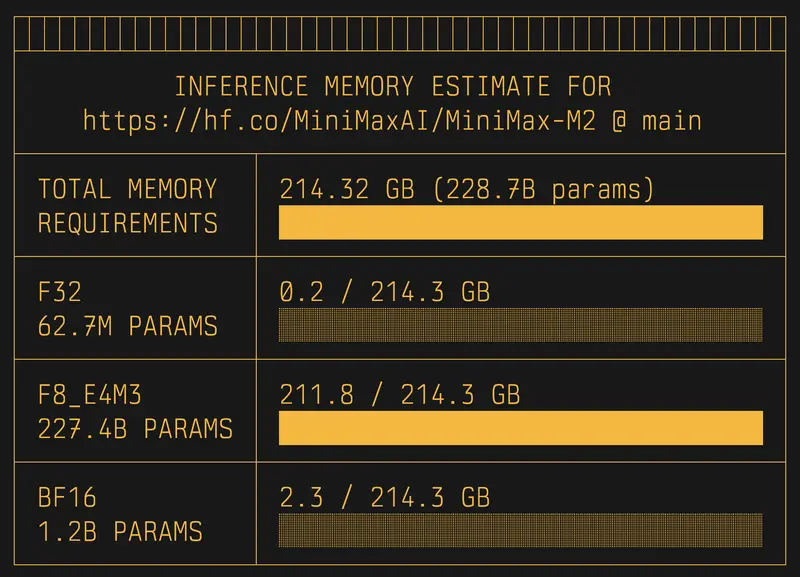
uvx hf-mem --model-id MiniMaxAI/MiniMax-M2
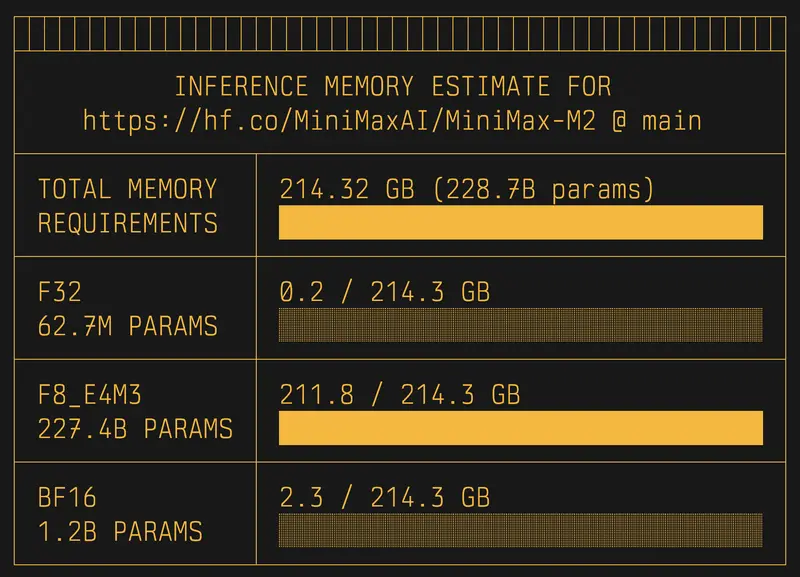
输出将显示模型权重加载所需的基础内存,以及推荐的推理显存余量。
uvx hf-mem --model-id Qwen/Qwen-Image
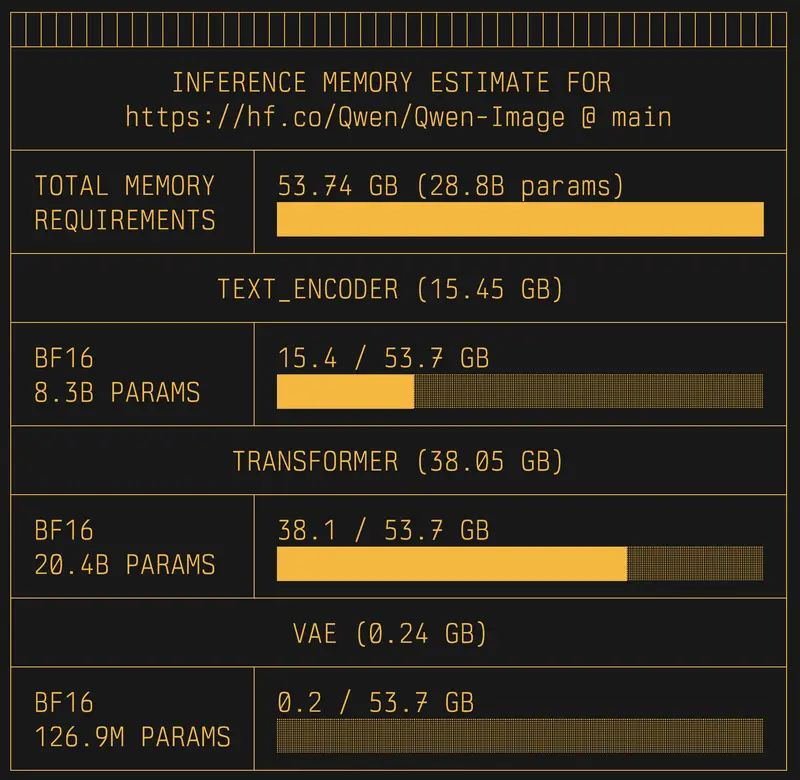
自动识别 Diffusers 架构,计算 UNet、VAE 及 Text Encoder 的总显存占用。
uvx hf-mem --model-id google/embeddinggemma-300m
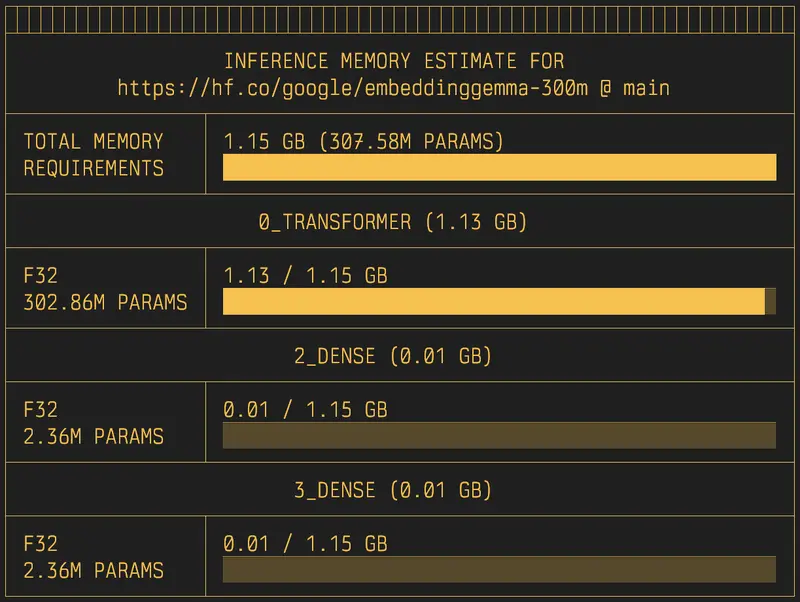
快速评估嵌入模型的轻量化程度,适合边缘设备部署参考。
对于大语言模型(LLM)和多模态模型(VLM),推理时的显存占用不仅来自权重,更来自KV Cache(键值缓存)。随着上下文长度(Context Length)和批次大小(Batch Size)的增加,KV Cache 的显存消耗可能远超模型权重本身。
hf-mem 提供了强大的实验性功能来应对这一挑战。
通过添加 --experimental 标志,hf-mem 将深入分析模型配置,估算动态推理过程中的显存峰值。
uvx hf-mem --model-id MiniMaxAI/MiniMax-M2 --experimental
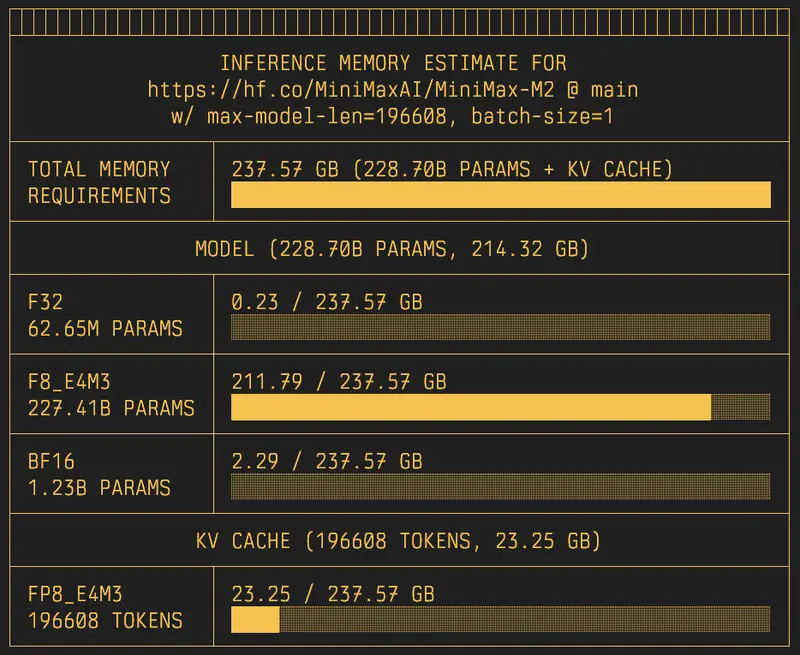
在实验模式下,你可以精细控制估算条件,模拟真实的生产环境:
--max-model-len:指定最大上下文长度。config.json 中的设定。--batch-size:指定并发批次大小。--kv-cache-dtype:指定 KV Cache 的数据类型。auto(自动读取 config.json 中的 torch_dtype 或 quantization_config)。fp16, bf16, int8 等,以评估量化策略带来的显存节省。示例:估算 Batch Size 为 4,上下文长度为 8192 的显存需求
uvx hf-mem --model-id MiniMaxAI/MiniMax-M2 \
--experimental \
--batch-size 4 \
--max-model-len 8192 \
--kv-cache-dtype fp16
hf-mem 不仅是一个独立的 CLI 工具,还设计为可被 AI 代理调用的技能(Skill)。
如果你在使用编码代理(Coding Agent)辅助开发,可以将 hf-mem 配置为代理技能。通过在项目中提供 SKILL.md 描述文件,底层的编码代理可以自动发现并调用 hf-mem。
应用场景:













