

ClickHelp AI
ClickHelp 正式推出 ClickHelp AI 套件,标志着ClickHelp迈向智能化文档管理的新阶段。这一套件将多个 AI 功能整合为统一平台,旨在为技术写作团队提供更强的生产力和更高的可扩展性。
大语言模型(LLM)虽强大,但它们也会“编造事实” —— 这就是我们常说的“幻觉”问题。
为了解决这一挑战,UQLM 应运而生。它是一个专为 LLM 输出进行不确定性量化(Uncertainty Quantification)的 Python 工具包,可用于检测模型输出中潜在的幻觉内容。

无论你是研究人员、开发者,还是 AI 系统的设计者,UQLM 都能帮助你更可靠地评估模型输出的质量。
你可以通过 PyPI 安装最新版本的 UQLM:
pip install uqlm无需复杂配置,开箱即用。
UQLM 提供了四种主要类型的评分器,用于从不同角度评估语言模型输出的不确定性,并返回一个 0 到 1 的置信度得分(得分越高,越可信)。
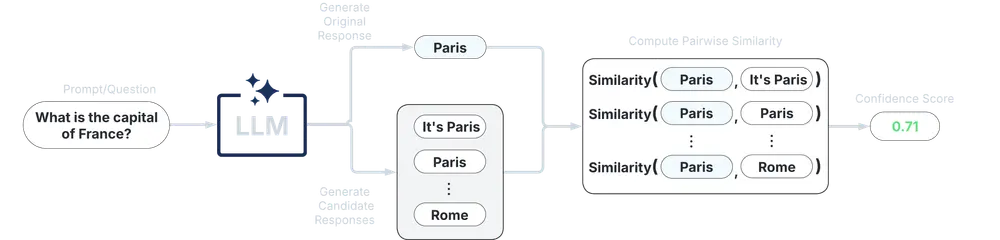

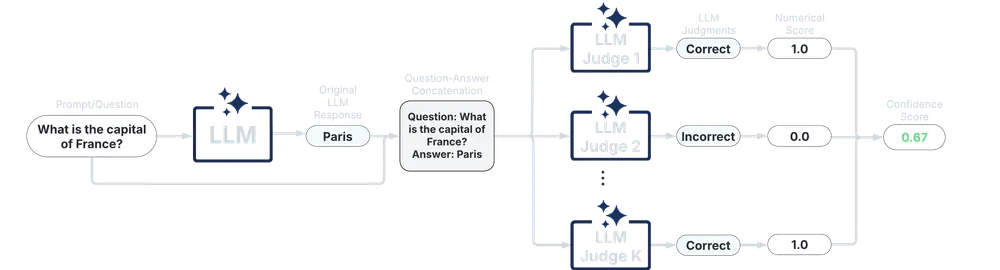

| 评分器类型 | 增加延迟 | 增加成本 | 兼容性 | 使用难度 |
|---|---|---|---|---|
| 黑盒评分器 | 中 - 高 | 高 | 通用,支持任意 LLM | 开箱即用 |
| 白盒评分器 | 极低 | 无 | 非通用,需 token 概率 | 开箱即用 |
| LLM 作为评判者评分器 | 低 - 中 | 低 - 高 | 通用,支持任意 LLM | 开箱即用 |
| 集成评分器 | 灵活组合 | 灵活组合 | 灵活组合 | 新手友好 / 可调优 |
UQLM 的设计目标是:













