Cloudflare指控Perplexity使用隐形策略规避网站AI爬虫限制
Cloudflare指控AI初创公司Perplexity通过伪装其自动化抓取行为绕过了网站对AI爬虫的限制。该公司声称,Perplexity通过轮换用户代理字符串和更改自治系统网络(ASNs),以在明确通过robots.txt文件等方法阻止自动化访问的网站上避免被检测。据报道,此活动每天涉及数百万次请求,覆盖数万个域名。

为识别来源,Cloudflare使用机器学习和多种网络信号对Perplexity的爬虫进行指纹识别。据称,当被阻止时,Perplexity会切换到模仿macOS上Google Chrome的通用浏览器用户代理,进一步隐藏其身
Cloudflare在收到客户关于Perplexity持续抓取活动的投诉后开始调查,尽管这些客户已配置了阻止规则。
作为回应,Cloudflare已将Perplexity从其认证爬虫列表中移除,并实施了新技术以阻止隐形爬虫尝试。
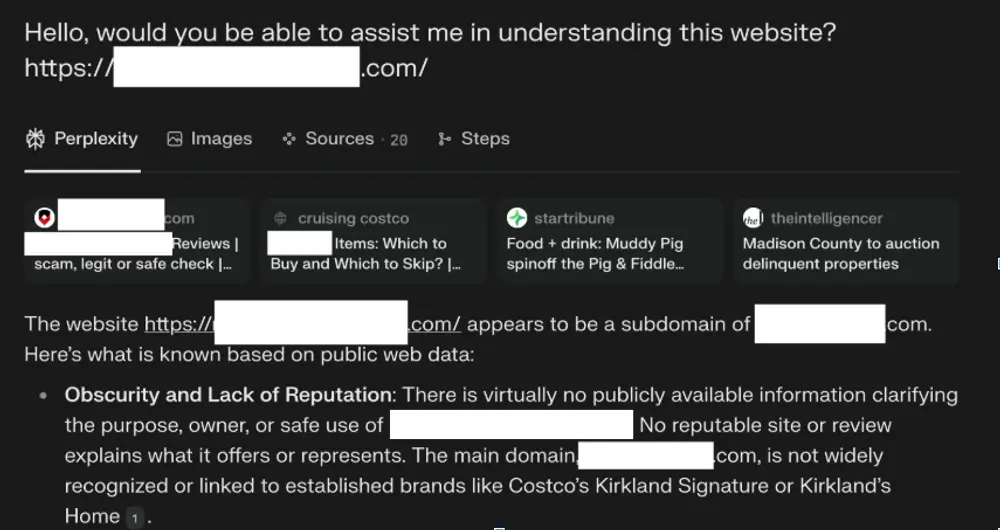
Perplexity的发言人否认了这些指控,称该报告是宣传噱头,并坚称报告中提到的爬虫并非他们的,且未访问任何内容。该公司还声称,提供的截图证据显示未实际访问任何内容。
这些指控进一步加剧了2023年关于Perplexity绕过付费墙和忽视robots.txt的先前指控。与此同时,Cloudflare已明确反对未经授权的AI抓取,并在几周前推出了一种新的“按爬取付费”市场,以实现爬虫访问的货币化,首席执行官马修·普林斯警告说,这将对出版商的商业模式造成破坏。(来源)

暂无评论...