
Tabletop Miniatures
Tabletop Miniatures是一款桌面微缩模型Flux Lora,自然就是适合出桌面微缩模型图片,再搭配混元或Wan2.1模型来生成视频,效果会非常好。
bigger breasts and butts是专为图像编辑模型 FLUX.1 Kontext [dev]训练的一个LoRA,用于微调胸部和臀部尺寸,输出可重复输入以增强效果或调整LoRA权重。

bigger breasts and butts是专为图像编辑模型 FLUX.1 Kontext [dev]训练的一个LoRA,用于微调胸部和臀部尺寸,输出可重复输入以增强效果或调整LoRA权重。对于此模型, 训练者ultraautism 还发布了自己的训练心得。

PS:由于ultraautism使用fal.ai训练,其模型无法在ComfyUI-nunchaku 中正常加载,本人已使用之前介绍的ComfyUI-RBG-LoRA-Converter插件进行了转换,大家可以从网盘下载修改版的模型进行使用。
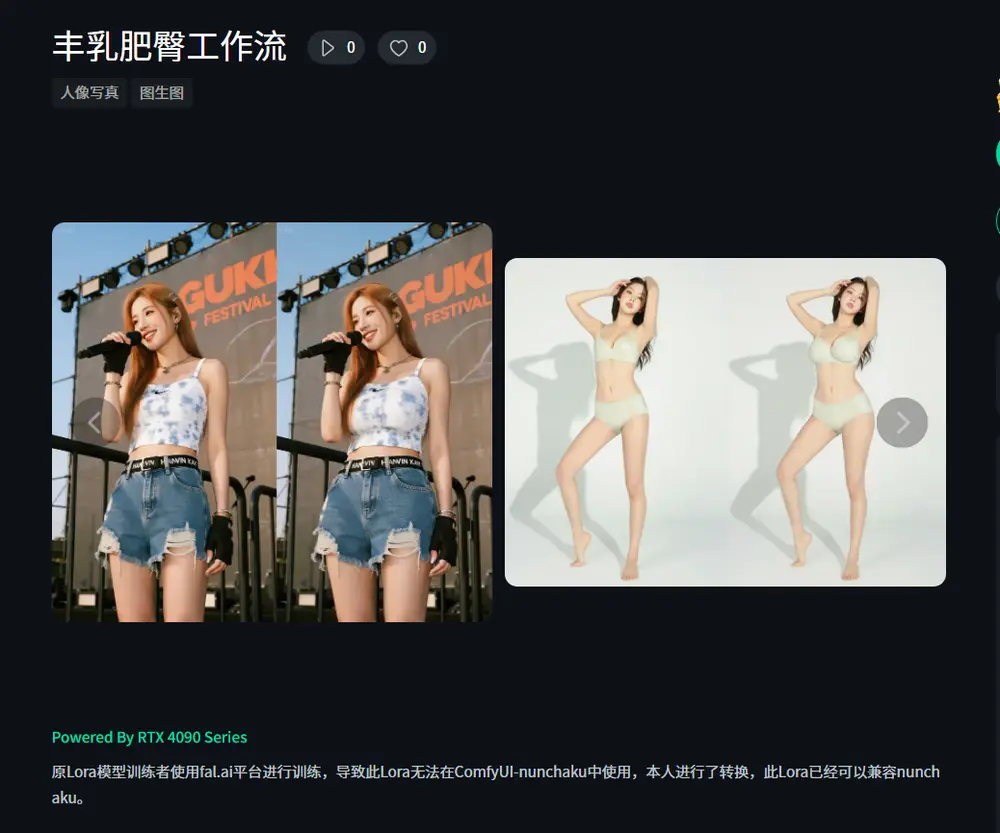
该 LoRA 的设计初衷是:
与传统“滑块 LoRA”不同,这类模型并非通过文本嵌入间接影响生成,而是直接学习图像对之间的变换规律,因此具备更强的上下文理解能力。

训练数据集由 50 对图像组成,使用 3D 虚拟角色平台 Virt-a-Mate(VAM) 渲染生成。
每对图像包含同一角色的两种状态:
所有图像在以下维度保持完全一致:
✅ 优势:VAM 支持“仅调整单一参数”(如胸部大小),其他变量不受影响,确保训练数据的“干净性”。
此外,数据集中包含 21 对双人图像(男女同框),其中仅女性身体发生变化,用于测试模型的选择性编辑能力。
作者选择云端训练以释放本地 GPU 资源,用于生成更多数据集。他认为,对于此类小规模任务,付费换时间是合理选择。
📌 注:测试表明,1000 步通常已足够,适合快速迭代。















