
微软正在将其 AI 战略从“单一助手”推向“多智能体协作”的新阶段。今日,微软宣布其全新的智能体功能 Copilot Cowork 正式通过 Frontier 计划 向 Microsoft 365 用户开放。与此同时,内置的 Researcher(研究员) 智能体迎来重大升级,首创 “模型委员会” (Model Council) 机制,实现了不同大模型之间的相互评审与协作。
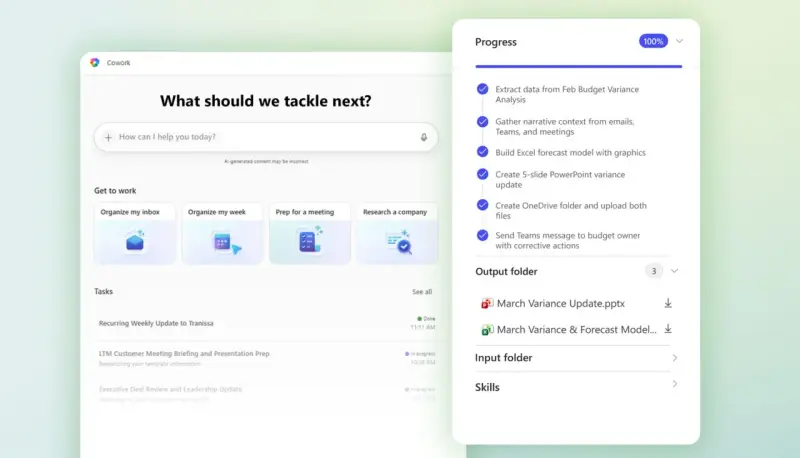
Copilot Cowork:从“对话”到“自主执行”
此前仅在小范围测试的 Copilot Cowork 现已面向 Frontier 计划用户开放。这不仅仅是一个聊天机器人,而是一个自主智能体 (Autonomous Agent):
- 后台自动执行:用户可将复杂任务(如整理数据、起草多封邮件、分析报表)交给 AI,它将在后台自动拆解步骤并执行,无需用户实时盯着屏幕。
- 多任务并行:支持同时发起多项任务,并通过全新的控制面板实时监控进度、干预流程或查看结果。
- 技术底座:该功能深度整合了 Anthropic Claude 的底层技术与微软自身的生态能力,旨在处理更广泛、更复杂的职场任务。
什么是 Frontier 计划?
这是微软推出的早期体验项目,允许 Microsoft 365 企业客户在功能正式公开发布前,优先测试实验性 AI 特性,并提供反馈以优化产品。
Researcher 智能体升级:引入“模型委员会”与“自我评审”
本次更新的重头戏在于 Researcher(研究员) 智能体的进化。微软不再依赖单一模型“一条龙”服务,而是构建了一个多模型协作与制衡系统:
1. Critique(评审)功能:生成与评估分离
为了解决大模型“幻觉”和逻辑漏洞,微软引入了分工机制:
- 生成者:例如使用 OpenAI GPT-5.4 负责任务规划、信息搜集和初稿撰写。
- 评审者:随后调用 Anthropic Claude Opus 4.6 对初稿进行严格审阅、事实核查和润色优化。
- 效果:这种“左脑写稿,右脑挑错”的模式,显著提升了输出的严谨性。
2. Model Council(模型委员会):多方会诊,求同存异
这是业界首创的多模型并排对比功能:
- 运行机制:当用户提出复杂查询时,Model Council 会同时调用 OpenAI 和 Anthropic 的顶级模型独立生成报告。
- 智能总结:随后,一个专门的评审模型会分析这两份报告,总结核心发现,并明确标注出模型间的共识(高置信度信息)与分歧点(需人工进一步核实的信息)。
- 价值:这模拟了人类专家团队的“会诊”过程,帮助用户在决策前看清不同视角的观点,避免被单一模型的偏见误导。
3. 性能实测:DRACO 基准测试胜出
微软透露,经过上述架构升级,Researcher 智能体在 DRACO (深度研究准确性、完整性与客观性) 基准测试中,得分提升了 13.8%。
- 对比竞品:表现优于 Perplexity、Google Gemini、原生 Claude 及 ChatGPT 等主流竞品,特别是在长文档分析和多源信息整合方面。
战略意义:从“工具”到“同事”
微软此次更新释放了两个关键信号:
- 模型中立化 (Model Agnostic):微软不再绑定单一模型供应商,而是根据任务特性(如规划、写作、评审)灵活调度 OpenAI 和 Anthropic 的最强能力,构建“最佳组合”。
- 智能体协作 (Agent Collaboration):AI 不再是被动回答问题的工具,而是能自主规划、相互监督、协同工作的“数字同事” (Coworker)。
如何体验?
目前,Copilot Cowork、Critique 和 Model Council 功能已同步登陆 Microsoft 365 Frontier 计划。
- 适用用户:加入 Frontier 计划的 Microsoft 365 企业客户。
- 后续计划:微软将根据测试反馈进一步优化,预计在未来几个月内逐步向更广泛的 Microsoft 365 Copilot 用户推送。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











