Anthropic 今日宣布了一项对开发者和企业用户极具重磅意义的更新:Claude Opus 4.6 和 Sonnet 4.6 模型的 100 万(1M)上下文窗口 现已全面可用,且不再收取任何长上下文额外费用。
- 文档:https://platform.claude.com/docs/zh-CN/build-with-claude/context-windows
这意味着,无论你的输入是 9,000 词元还是 900,000 词元,都将按照统一的标准费率计费。这一举措彻底消除了以往使用超长上下文时的“溢价焦虑”,标志着大模型长文本应用进入了普惠阶段。
核心变革:统一费率,拒绝“长度税”
此前,许多模型厂商会对超过一定长度的上下文收取高额附加费(乘数)。Anthropic 此次直接取消了这一限制:
- 统一计价:整个 100 万窗口均适用标准定价。
- Opus 4.6: 输入 $5 / 百万词元 | 输出 $25 / 百万词元
- Sonnet 4.6: 输入 $3 / 百万词元 | 输出 $15 / 百万词元
- 无乘数机制:一个 90 万词元的请求,其单价与一个 9 千词元的请求完全相同。
- 吞吐量不变:标准账户的速率限制(Rate Limits)适用于整个窗口,不会因为上下文变长而降低并发能力。
媒体处理能力暴涨 6 倍
除了文本,多模态处理能力也迎来了巨大飞跃:
- 上限提升:每个请求支持的图像或 PDF 页面数量从 100 张激增至 600 张。
- 应用场景:现在你可以一次性上传整本数百页的技术手册、法律合同全集或大型图表集,让模型进行跨页面的深度关联分析。
- 全平台同步:该特性已在 Claude 原生平台、Microsoft Azure Foundry 和 Google Cloud Vertex AI 上同步上线。
无缝升级:无需代码改动
对于开发者而言,这次升级极其平滑:
- 自动生效:超过 20 万词元的请求将自动启用 100 万上下文能力,无需任何特殊配置。
- 废弃测试版标头:如果你之前在代码中添加了
beta标头来尝试长上下文,现在可以直接移除(即使保留也会被忽略),系统会自动处理。 - Claude Code 集成:对于使用 Opus 4.6 的 Claude Code Max、Team 及 Enterprise 用户,100 万上下文已成为默认设置。这意味着 AI 编程助手能记住更完整的代码库历史、更长的调试日志,减少因上下文压缩导致的信息丢失。
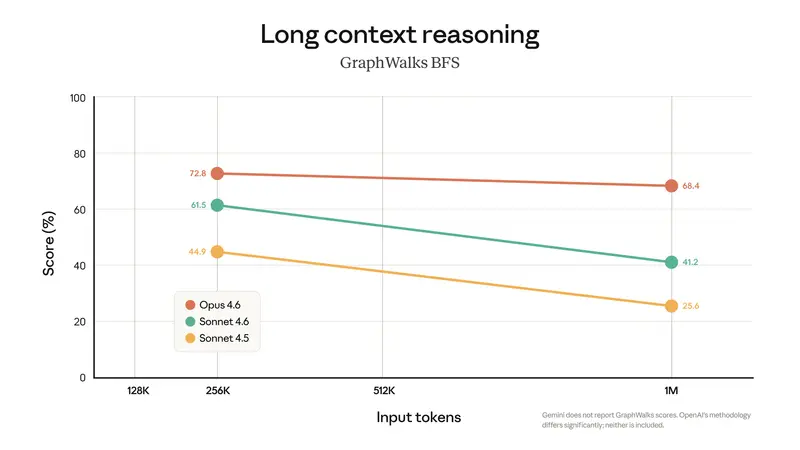
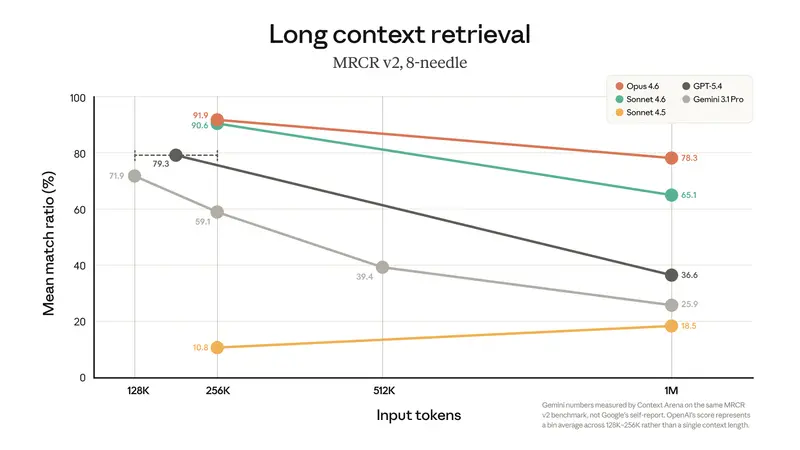
实力验证:不仅仅是“能塞进”,更是“记得住”
拥有大窗口是一回事,能否有效利用是另一回事。Anthropic 强调了其模型在长上下文中的检索与推理能力:
- Opus 4.6: 在 MRCR v2 (大规模上下文检索) 基准测试中得分 78.3%。
- Sonnet 4.6: 在 GraphWalks BFS (100 万词元图遍历) 测试中得分 68.4%。
- 行业领先:两者均在同等上下文长度的前沿模型中表现最佳。
实际意义:
你不再需要工程师花费大量时间编写复杂的“上下文清理”、“有损摘要”或“分块检索”逻辑。你可以直接将整个代码库、数千页的法律文档或智能体长期运行的完整追踪记录(包含所有工具调用、观察结果和中间推理)“喂”给模型,它能精准地定位细节并进行跨文档推理。
可用性渠道
即日起,100 万上下文功能已在以下平台全面开放:
- Claude.ai (原生平台)
- Amazon Bedrock
- Google Cloud Vertex AI
- Microsoft Azure Foundry
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...