
据多方消息,可灵AI(Kling AI)将于 2025 年 12 月 3 日前后正式发布 Kling 2.6 视频生成模型,首次内置原生音频生成能力,支持人声说话、歌唱与环境音效,实现视频与声音的同步生成。
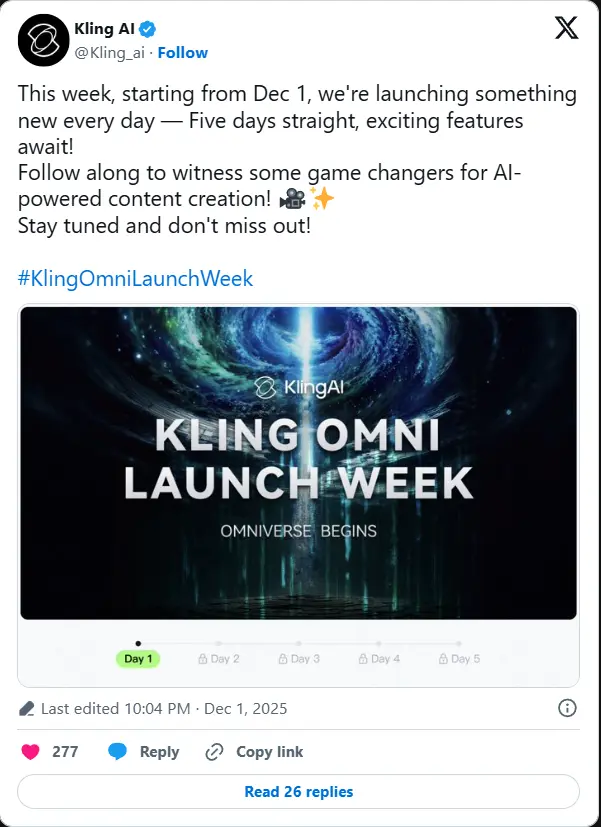
这一升级将使 Kling 成为少数能提供完整多模态生成工作流(图像 → 视频 + 音频)的国产 AI 视频模型,直接对标 OpenAI 的 Sora 2 与 Google 的 Veo 3.1。
核心升级:原生音频集成
- 同步生成:音频不再依赖后期配音或外接工具,而是在视频生成过程中与画面协同输出
- 支持类型:
- 自然口语对话(中英双语首发)
- 歌唱(含旋律与歌词对齐)
- 环境音效(如雨声、街道、机械运转等)
- 技术口号:“See the Sound, Hear the Visual”(看见声音,听见画面)
这意味着用户只需输入一段文本提示,即可获得带同步配音与配乐的完整短视频,大幅降低创作门槛。
产品演进:从 Kling 1.6 到 2.6
Kling 系列自 2024 年起快速迭代:
- Kling 1.6–2.0:基础视频生成
- Kling 2.5:支持高分辨率、精细动作控制、图像到视频
- Kling Omni:多模态中心,整合文本、图像、视频生成
- Kling 2.6:补齐音频短板,形成“文-图-视-声”全链路
目前 Kling 已通过第三方平台(如字节、腾讯生态)向创作者和影视工作室提供 Turbo、Pro、Master 三级服务,2.6 将首先在 Pro 版本上线音频功能。
发布节奏:配合“Kling 发布周”
Kling 背后母公司 快手 宣布,自 12 月 1 日起连续五天发布 AI 新品。鉴于 Kling O1(多模态创作中枢)已于 12 月 1 日亮相,12 月 3 日作为 Kling 2.6 的发布日高度合理。
初期音频功能预计将上线于:
- Kling 官网网页工具
- 快手 AI 创作平台
- 合作伙伴 API
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











