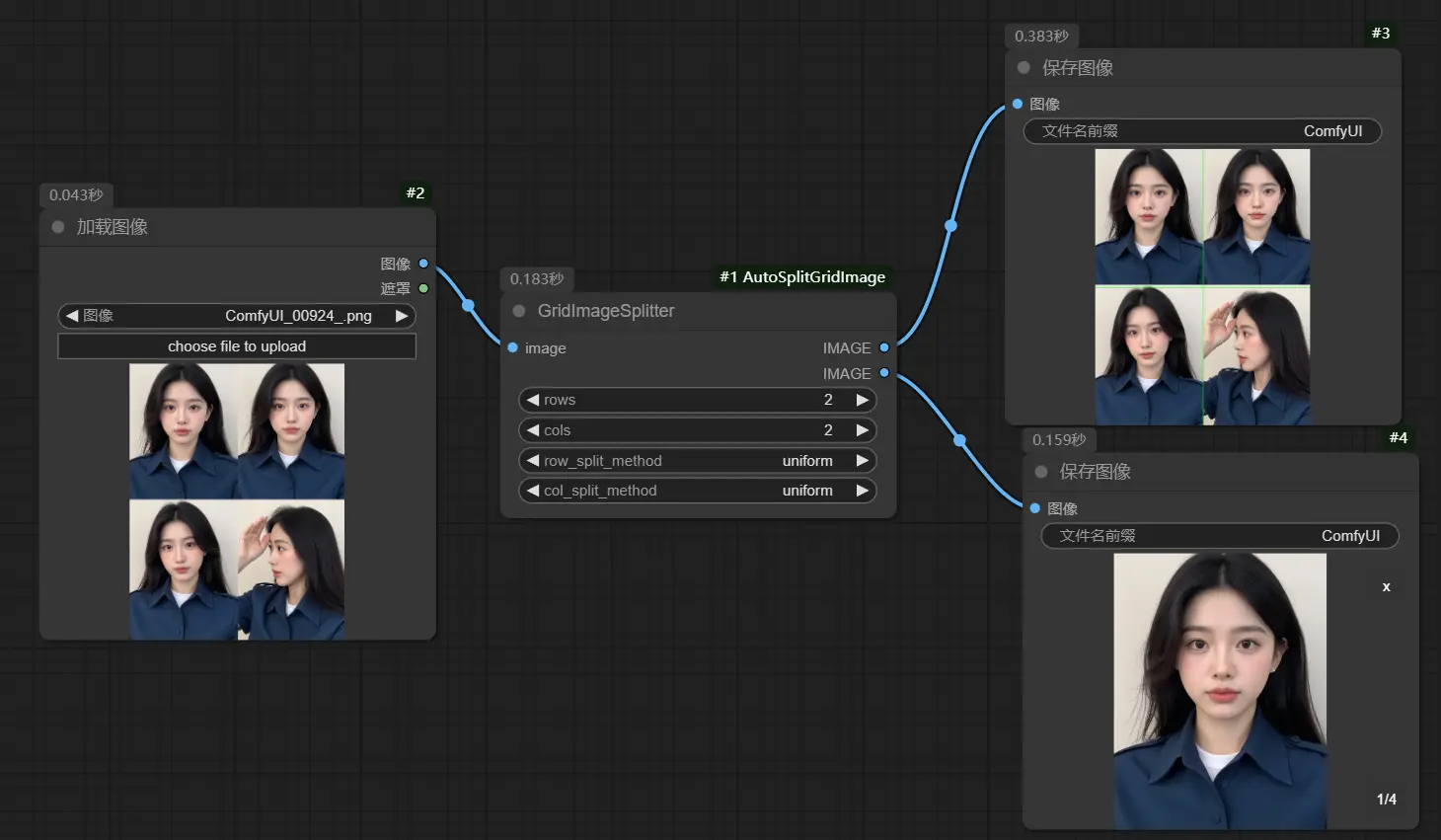
在运行大型视频生成或扩散模型时,显存(VRAM)不足是常见瓶颈。为解决这一问题,开发者eddyhhlure1Eddy推出 Enhanced BlockSwap (CUDA Optimized) ——一款专为 ComfyUI 设计的高性能内存管理节点,通过智能分块交换与 CUDA 核心级优化,显著提升 GPU 利用率并防止 OOM(内存溢出)错误。
该节点特别适用于 RTX 3090、4090、5090 等大显存设备,在处理长序列视频生成、高分辨率图像推理等重负载任务中表现优异。
核心功能亮点
1. 智能 VRAM 管理
- 自动 VRAM-DRAM 平衡
基于模型结构、层数与硬件规格进行数学建模,精确计算最优内存分配比例。 - 50% 阈值触发机制
当 VRAM 使用率超过 50% 时,自动启用分块迁移策略,提前预防溢出。 - VRAM 优先 + DRAM 缓冲
关键张量保留在显存中以保证性能,非关键大张量按需迁移到系统内存(DRAM),实现平滑过渡。 - 实时监控防溢出
动态追踪显存占用、传输带宽与 GPU 利用率,确保推理过程稳定运行。
2. CUDA 层面深度优化
- 多流并行传输
利用 CUDA 多流(Multi-Stream)技术,实现计算与数据搬运重叠,最大化 GPU 利用率。 - 自动硬件调优
支持 RTX 3090/4090/5090 等主流型号,根据 SM 数量、显存容量自动配置最佳参数。 - 智能流数量调节
动态调整num_cuda_streams,匹配当前任务的并行需求,避免资源浪费或竞争。 - 带宽目标自适应
根据可用 VRAM 容量智能设定bandwidth_target,平衡速度与稳定性。
3. 核心算法设计
- 张量优先级管理
区分关键计算张量与临时缓存,优先保留前者于 VRAM。 - 数学驱动的内存分配
不依赖经验参数,而是基于模型大小与硬件能力进行量化决策。 - 动态 blocks_to_swap 计算
自动确定每次应交换的模块数量,减少手动调参负担。 - 全程性能监控
提供 GPU 利用率、显存使用、PCIe 传输速率等关键指标反馈。
安装步骤
- 复制文件夹
将IntelligentVRAMNode文件夹复制到你的 ComfyUI 插件目录:ComfyUI/custom_nodes/IntelligentVRAMNode/ - 重启 ComfyUI
启动或重启 ComfyUI,加载新节点。 - 查找节点
在节点浏览器中搜索以下类别:
→ WanVideoWrapper / Enhanced
使用节点:WanVideo Enhanced BlockSwap (CUDA Optimized)
推荐配置(推荐新手使用)
WanVideo Enhanced BlockSwap (CUDA Optimized):
├── auto_hardware_tuning: True # 启用自动调优(推荐)
├── vram_threshold_percent: 50.0 # 显存超 50% 触发迁移
├── enable_cuda_optimization: True # 开启 CUDA 多流优化
├── enable_dram_optimization: True # 启用 DRAM 缓冲优化
└── debug_mode: False # 关闭调试日志
此模式适用于绝大多数场景,无需手动干预即可获得良好性能。
手动配置(高级用户)
WanVideo Enhanced BlockSwap (CUDA Optimized):
├── auto_hardware_tuning: False # 关闭自动调优
├── blocks_to_swap: 8 # 自定义交换块数
├── num_cuda_streams: 12 # 设置 CUDA 流数量
├── bandwidth_target: 0.8 # 显存使用目标比例
└── vram_threshold_percent: 50.0 # 触发阈值保持默认
⚠️ 注意:仅当
auto_hardware_tuning = False时,blocks_to_swap和num_cuda_streams才生效。
参数说明表
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
auto_hardware_tuning | Boolean | True | 是否根据 GPU 型号自动优化参数 |
vram_threshold_percent | Float | 50.0 | 显存使用率超过此值触发迁移 |
blocks_to_swap | Int | 0 | 手动设置每次交换的模块数量 |
num_cuda_streams | Int | 8 | CUDA 并行流数量,影响传输效率 |
bandwidth_target | Float | 0.8 | 内存使用目标比例(0.0~1.0) |
enable_cuda_optimization | Boolean | True | 是否启用多流传输优化 |
enable_dram_optimization | Boolean | True | 是否启用 DRAM 缓冲策略 |
debug_mode | Boolean | False | 是否输出详细日志用于调试 |
实测性能提升(RTX 5090, 32GB VRAM)
| 指标 | 优化前 | 优化后 | 提升效果 |
|---|---|---|---|
| VRAM 使用率 | >95% | <50% | 显著降低,远离溢出风险 |
| OOM 错误 | 频发 | 完全消除 | 推理稳定性大幅提升 |
| CUDA 利用率 | 14–28% | >60% | GPU 计算资源得到充分利用 |
| 支持模型规模 | 中等 | 更大/更长序列 | 可运行更高复杂度任务 |
内存管理策略总结
- ✅ VRAM 优先:保障核心计算路径低延迟
- ✅ DRAM 智能缓冲:作为溢出层,不中断流程
- ✅ 分层迁移机制:按张量重要性分级处理
- ✅ 动态自适应调整:实时响应负载变化,持续优化
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











