
此前在大模型测试评估平台LMArena上现身的图像编辑模型nano banana,如今已确认归属谷歌——不过目前它仍处于测试阶段,仅能在LMArena内使用,且需通过“抽卡”方式获取使用资格,常需多轮尝试才能触发该模型生成图片。好在X平台网友Gorden_Sun分享了一套实用技巧,能将抽中nano banana的概率提升至2/3;更关键的是,从生成效果与特性来看,nano banana极有可能就是Gemini 2.0 Flash preview image generation的正式版。
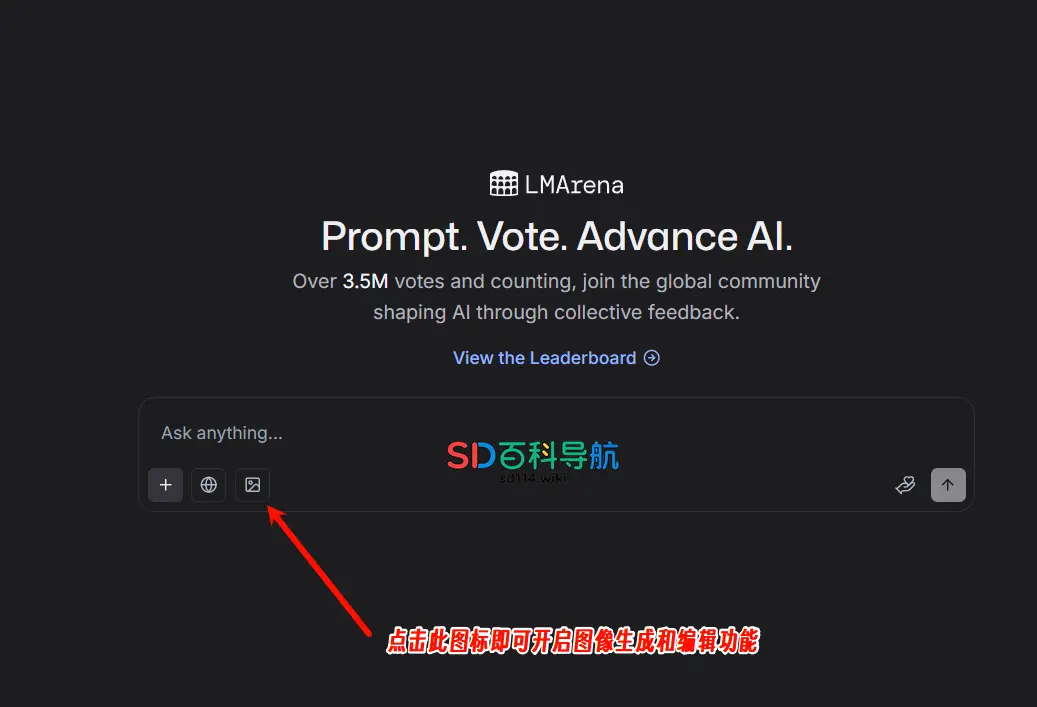
LMArena抽中nano banana的核心技巧:始终上传2张图片
nano banana在LMArena的“抽卡机制”中,并非每次都会出现,而Gorden_Sun的技巧核心在于“通过上传图片数量缩小可选模型范围”,具体操作分三类场景,且均围绕“上传2张图片”展开,操作简单且不影响最终生成效果:
1. 文字生成图片:用2张透明小图搭配文字提示
若你需要通过文字指令生成图片(而非编辑已有图片),无需上传真实素材,只需准备2张尺寸极小的透明图片(例如10x10像素,可通过简单图像工具生成),将其作为“提示词的一部分”上传,再正常输入中文文字提示即可。透明图片的作用仅为“满足多图上传条件”,其本身的token(数据标识)不会对生成内容产生任何影响,不会干扰文字提示的创意表达。
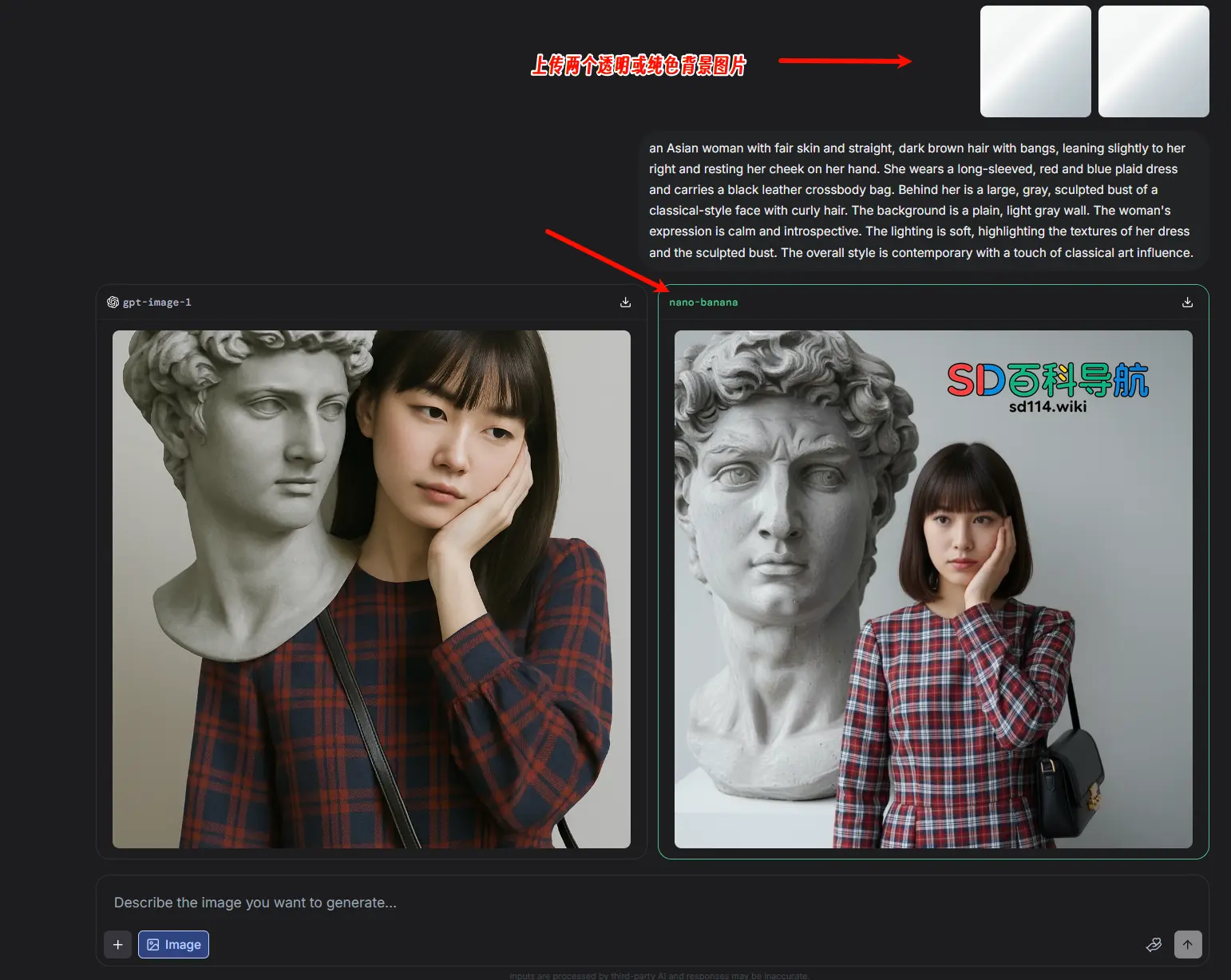
2. 编辑1张图片:目标图+1张透明小图
若需对单张图片进行编辑(如修改风格、添加元素),则上传“需要编辑的目标图片”+“1张透明小图”,两者共同作为提示素材,再输入编辑类文字提示(如“将这张风景图改为赛博朋克风格,保留山脉轮廓”)。这种方式既符合“上传2张图片”的条件,又能确保编辑焦点集中在目标图片上,透明小图不会引入额外干扰。
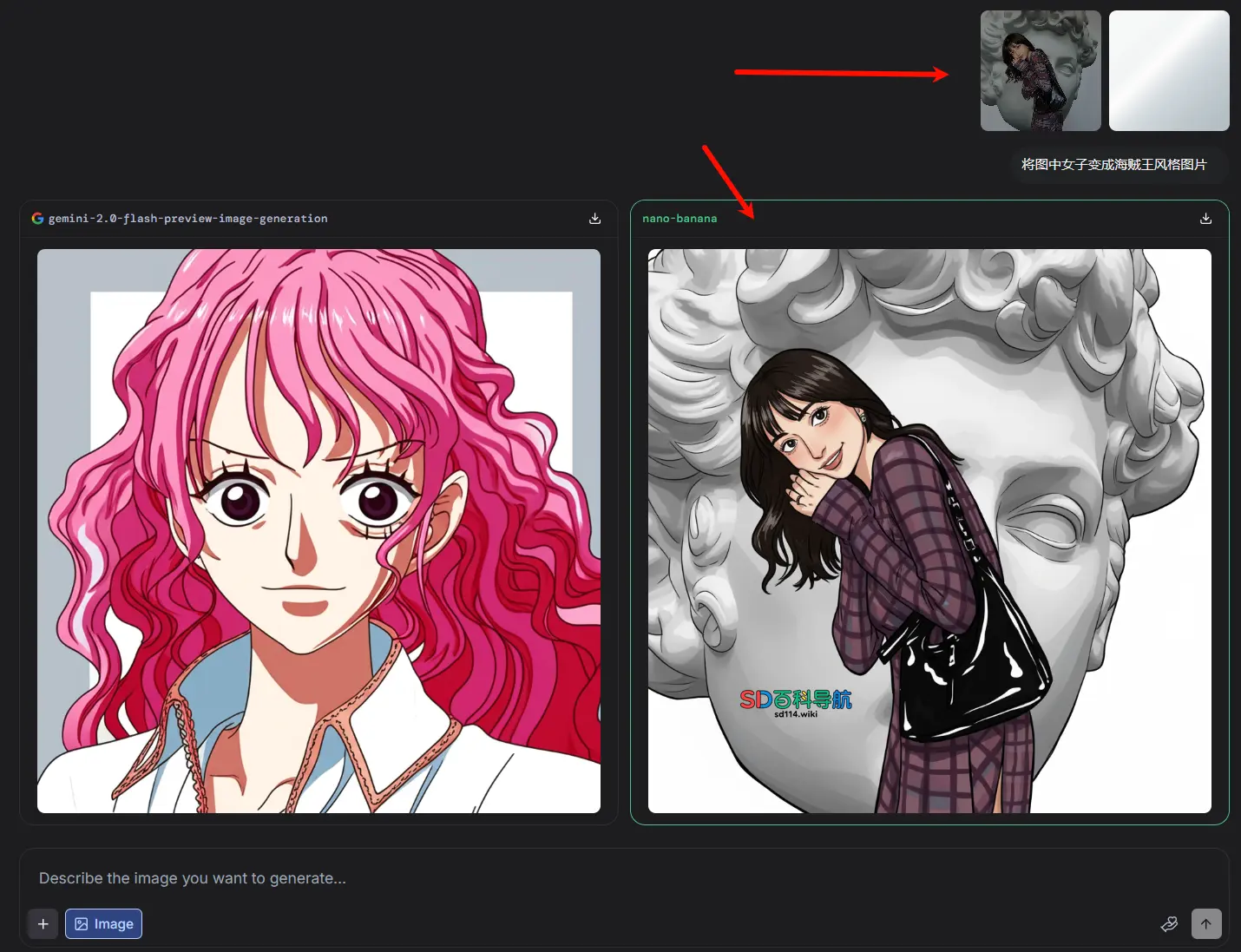
3. 编辑2张及以上图片:直接上传全部目标图
若需同时编辑2张或更多图片(如拼接风格、统一色调),则无需额外添加透明图,直接上传所有需要编辑的目标图片,再输入文字提示即可——此时天然满足“2张及以上图片”的上传条件,可直接触发后续概率优化效果。
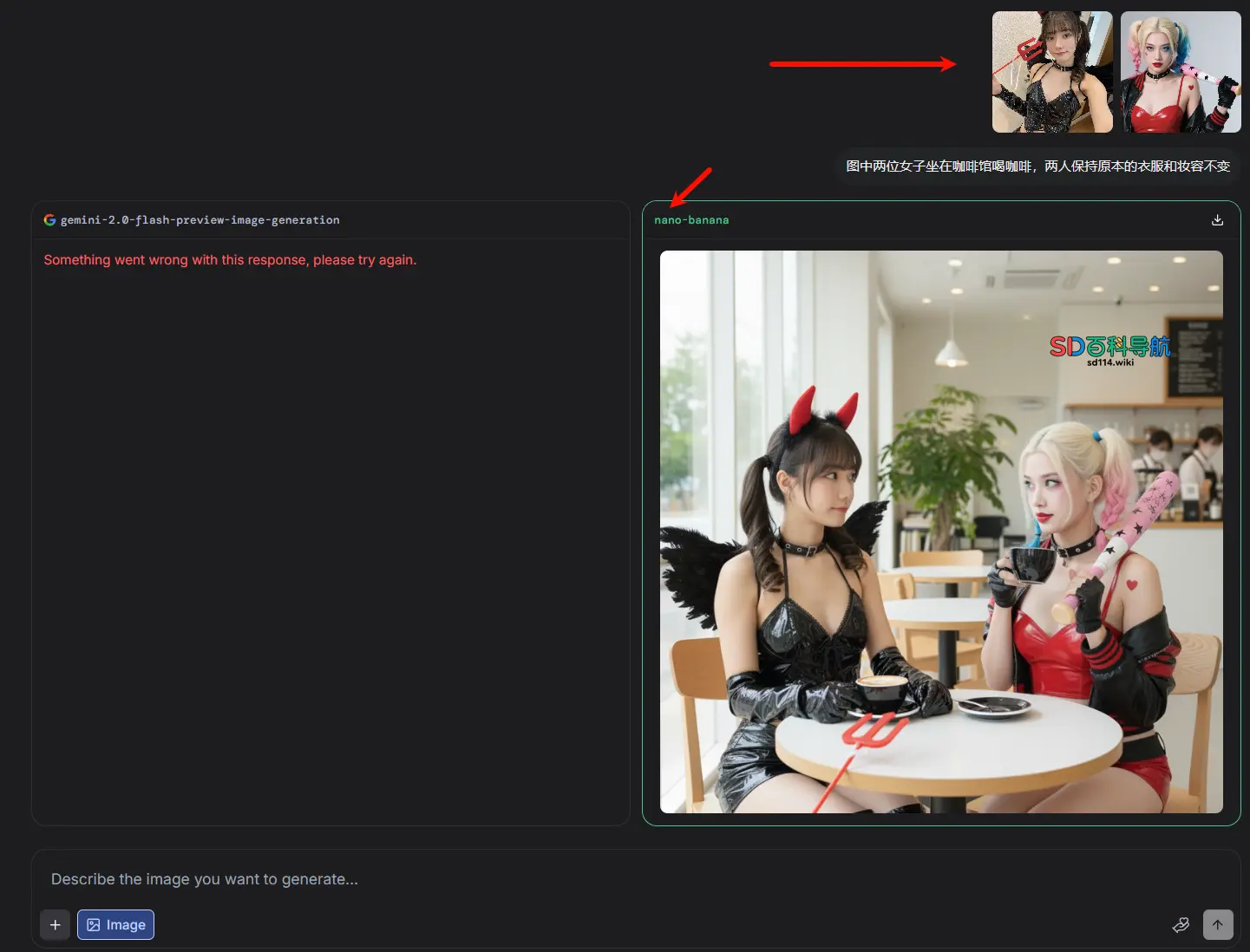
按照这套方法操作后,LMArena中能参与“图像生成/编辑比赛”的模型会被限定为3个:nano banana、Gemini 2.0 Flash preview image generation、GPT-1-image,而非原本的多个随机模型。由于可选范围大幅缩小,且这3个模型中nano banana的触发权重较高,因此抽中概率能提升至2/3,大幅减少无效尝试。
技巧背后的原理:仅3个模型支持多图API,透明图不干扰效果
这套技巧能生效,核心源于LMArena平台的模型调用规则与图像token的特性:
1. 多图上传限制:仅3个模型支持多图API
LMArena内的多数图像模型,其API仅支持“单图上传”或“纯文字提示”,而nano banana、Gemini 2.0 Flash preview image generation、GPT-1-image这3个模型是少数支持“传入多个图片作为提示”的类型。通过强制上传2张图片,可直接过滤掉不支持多图的模型,从根源上缩小可选范围,自然提升目标模型的出现概率。
2. 透明小图的优势:不占用有效token,不影响生成质量
透明图片的像素信息简单,其对应的token(用于模型识别的数据流)不会携带任何有效视觉信息,因此模型在解析提示时,会自动忽略透明图的存在,仅聚焦于文字提示或目标编辑图——这就确保了“为凑数上传的透明图”不会干扰创意表达,生成效果与正常操作完全一致,既达成了“缩小模型范围”的目的,又不损失生成质量。
nano banana的身份揭秘:实为Gemini 2.0 Flash preview image generation正式版
除了抽卡技巧,从实际使用体验来看,nano banana与Gemini 2.0 Flash preview image generation存在高度关联,甚至可判定为后者的正式版,核心依据有两点:
1. 生成效果高度重合,nano banana细节更优
多位测试者反馈,在输入相同提示词(尤其是相同图像编辑需求)时,nano banana与Gemini 2.0 Flash preview image generation生成的图片“整体风格、构图逻辑几乎一致”——例如处理“风景图转动漫风格”时,两者对色彩搭配、线条勾勒的处理方式高度相似。区别在于,nano banana的输出在细节上更丰富:比如人物发丝的层次感、物体表面的纹理质感、背景环境的光影过渡,都比Gemini 2.0 Flash preview版本更细腻,符合“正式版对测试版的优化逻辑”。
2. 功能特性完全匹配,无额外学习成本
无论是支持的提示词类型(中文、英文均兼容)、编辑功能(风格迁移、元素添加、细节修改),还是对多图输入的处理逻辑,nano banana都与Gemini 2.0 Flash preview image generation完全一致。用户从后者切换到前者时,无需适应新的操作习惯或提示词规则,进一步印证了两者的“同源性”——nano banana更像是在Gemini 2.0 Flash preview基础上,完成细节优化后的正式命名版本。
使用建议:适合想提前体验谷歌新图像模型的用户
目前nano banana仅能在LMArena通过抽卡使用,虽有技巧提升概率,但仍存在一定随机性,适合两类用户尝试:
- AI图像模型爱好者:想提前体验谷歌最新图像编辑能力,对比nano banana与其他模型(如GPT-1-image)的生成差异;
- 需要细节优化的创作者:若对Gemini 2.0 Flash preview的细节表现不满,可尝试通过技巧抽中nano banana,获取更细腻的图像输出。
需要注意的是,nano banana仍为测试模型,生成效果可能存在不稳定情况,且LMArena平台的“抽卡机制”未来可能调整,建议在体验时优先保存满意的生成结果。随着谷歌对Gemini生态的整合,预计nano banana(或其正式命名版本)未来会逐步整合到Gemini主应用或其他创意工具中,届时无需依赖抽卡即可直接使用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











