
TimeCapsule LLM 是一个实验性语言模型项目,其目标是通过仅使用特定历史时期的文本进行训练,构建一个尽可能“还原历史语言风格与世界观”的语言模型。与传统微调不同,该项目从头开始训练,旨在减少现代偏见,探索语言模型在特定历史语境下的表达能力。
本项目基于 Andrej Karpathy 的 nanoGPT 构建,核心训练脚本和模型架构均直接借鉴其开源成果。
项目目标
构建一个仅基于1800-1850年伦敦地区文本训练的语言模型,尝试模拟该时期的语言风格、世界观和知识边界。
与“假装古老”的AI不同,TimeCapsule LLM 的设计目标是:
- 不包含现代概念
- 不生成现代知识幻觉
- 尽可能基于原始历史文本进行推理
我们希望通过这个项目探索语言模型在特定历史语境下的表现力,以及从零开始训练语言模型的可行性。
为什么选择从头训练?
如果仅对现代预训练模型(如 GPT-2)进行微调,模型仍会保留大量现代语言和知识结构,难以真正还原历史语境。
- 微调只能调整已有知识的表达方式,无法“删除”已有信息
- 语言模型会倾向于使用现代术语和概念进行回应
因此,要实现“历史还原”,唯一可行的方法是从头训练,使用完全来自目标时期的文本数据。
当前进展(截至2025年7月)
✅ 已完成
- 时间段设定:1800–1850年,地点:伦敦
- 数据收集:已整理约50个原始文本文件,总数据量约187MB
- 模型架构:基于 nanoGPT 构建,参数量约1600万
- 初步训练:已完成第一阶段训练,模型开始展现历史语言风格
🔍 初步观察
- 模型能使用19世纪风格的语言进行回应
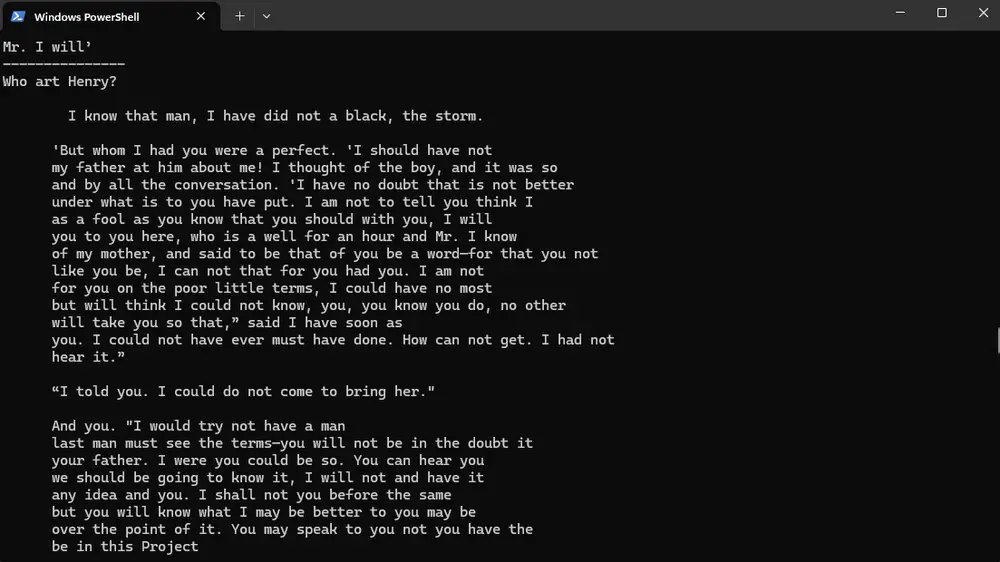
- 例如提示
Who art Henry?,模型回应I know that man, I have did not a black, the storm. - 回答虽不完整,但未引入现代术语或概念
- 生成内容仍缺乏连贯性,符合当前训练数据规模的表现
后续计划
📚 数据扩展
- 目标:从50本书扩展至500–600本
- 挑战:确保书籍为原始出版物,不含现代注释或OCR错误
- 来源:1800–1850年伦敦出版的书籍、法律文件、报纸等
🧱 模型优化
- 构建更完整的分词器
- 改进训练流程,提升生成文本的连贯性
- 逐步提升模型参数规模(视硬件条件)
如何使用此项目?
该项目主要聚焦于历史文本的收集、清洗与训练数据准备,并不包含完整的语言模型训练教程。有关模型训练部分,请参考 nanoGPT 官方文档。
步骤 1:收集历史文本
- 收集目标时期的公共领域书籍、文档的
.txt文件(如 1800–1850 年伦敦出版物) - 可使用项目中的
download_texts_improved.py自动下载书籍 - 使用脚本或手动清理文本文件,移除 Project Gutenberg 的页眉/页脚、现代注释或 OCR 错误
步骤 2:构建分词器
- 在清理后的数据上运行
train_tokenizer.py或train_tokenizer_hf.py - 生成
vocab.json和merges.txt,定义模型的词汇表和合并规则
步骤 3:训练模型(使用 nanoGPT)
- 模型训练部分请参考 nanoGPT 的训练流程
- 本项目使用 nanoGPT 架构,但你也可以选择其他语言模型架构
常见问题解答
为什么不使用微调或 LoRA?
本项目的目标是从零开始训练一个没有现代偏见的语言模型。微调无法完全清除预训练模型中包含的现代知识,因此无法实现项目目标。
你用了哪些训练数据?
我使用的是1800–1850年伦敦出版的书籍、法律文件、报纸等原始文献。目前训练集包含约50个文件,总大小约187MB。
当前模型规模如何?
目前模型参数约为1600万,训练设备为:
- GPU:GeForce RTX 4060
- CPU:i5-13400F
- 内存:16GB DDR5
后续将根据数据扩展情况逐步提升模型规模。
技术细节
| 项目 | 描述 |
|---|---|
| 模型架构 | 基于 nanoGPT |
| 参数规模 | 约 16M(后续将增加) |
| 训练数据 | 1800–1850年伦敦出版物,约187MB |
| 分词方式 | 自定义 BPE 分词器 |
| 输出长度 | 依赖模型训练设置 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











