据近期泄露的基准测试数据显示,xAI 正在开发中的 Grok 4 模型在多个关键评估指标上表现卓越,有望成为当前最先进的大语言模型(SOTA)之一。尽管尚未正式发布,但其在多个权威测试中展现出的潜力已引发广泛关注。
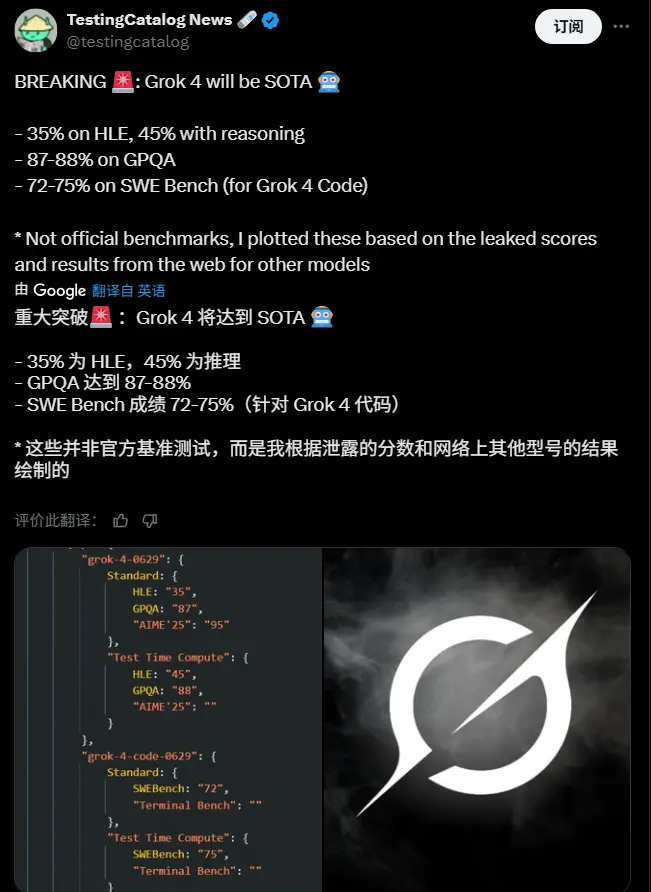
主要测试成绩(泄露数据):
| 测试项目 | Grok 4 成绩 | 备注 |
|---|---|---|
| Humanity Last Exam (HLE) | 基础得分 35%,推理模式下达 45% | 超过此前最高分 o3 Pro 的 26% |
| GPQA | 87–88% | 当前领先模型平均水平为 80% 左右 |
| SWE Bench(代码能力) | 72–75% | 接近 Gemini Code 1.5 Pro 和 o3 Pro |
这些数据如果属实,意味着 Grok 4 在多个维度上超越了目前市场上主流的大型语言模型,包括 OpenAI 的 o3 Pro、Anthropic 的 Claude 4 Opus 和谷歌的 Gemini 2.5 Pro。
💡 核心突破点:Humanity Last Exam 上的飞跃
Humanity Last Exam 是一项旨在衡量 AI 是否能通过人类最难考试之一的挑战性测试。它不仅考察知识广度,更强调逻辑推理和深度理解能力。
- Grok 4 基础得分:35%
- 启用推理机制后提升至:45%
相比之下,当前领先的 o3 Pro 仅获得 26% 分数。这一跃升表明 Grok 4 在复杂推理与问题解决方面取得了实质性进展。
技术背景与战略意义
xAI 的研发节奏
- 内部版本构建日期:6 月 29 日 和 7 月 2 日
- 可能在 7 月 4 日之后发布(与马斯克此前暗示一致)
- xAI 控制台与文档中已出现 Grok 4 相关条目,表明其接近完成状态
性能优势解读
- 多任务泛化能力增强:尤其在 GPQA(通用物理与科学问答)上的高分显示其对复杂概念的理解能力。
- 代码生成与修复能力显著提升:SWE Bench 得分 72–75%,说明其在真实软件工程场景下的实用价值。
- 推理模块优化明显:启用推理机制后 HLE 成绩大幅上升,表明 xAI 在思维链(Chain-of-Thought)与规划能力上有重要突破。
目标用户群体
Grok 4 的推出将主要受益于以下几类用户:
- 开发者与研究人员:利用更强的推理与编码能力进行高级任务开发;
- 企业级用户:需要处理复杂业务逻辑、自动化流程或智能客服的企业;
- 教育与科研机构:用于教学辅助、自动评测与研究支持;
- 消费者产品用户:若 Grok 4 的 API 支持扩展到消费端应用(如 Twitter/X 集成),普通用户也将体验到更强大的交互能力。
发布时间与竞争压力
虽然官方尚未公布具体发布时间,但从内部构建记录与文档更新来看:
- 极有可能在未来一周内正式发布;
- 若延迟,可能与模型微调、API 整合等细节优化有关;
- 面临来自 OpenAI GPT-5、谷歌 Gemini 2.5 Pro、以及 Anthropic Claude 4 的激烈竞争。
xAI 的战略一直以“快速迭代 + 强性能突破”为核心,此次 Grok 4 若如期发布并验证其性能,将进一步巩固其作为前沿 AI 实验室的地位。
开发者生态与部署路径
从现有信息推测,Grok 4 的部署方式可能延续 xAI 以往风格:
- 开发者控制台优先上线:供已有 Grok 用户试用;
- API 扩展:支持第三方集成与企业服务;
- 消费端整合:可能通过 X 平台逐步向公众开放。
此外,xAI 还可能提供:
- 更强的多模态支持(图像/音频/文本联合处理);
- 更低延迟与更高并发处理能力;
- 更灵活的定制选项(如轻量版 Grok 4 Mini);
📈 行业影响预测
如果 Grok 4 的基准测试结果属实,并顺利发布,其将带来的影响包括:
| 影响方向 | 描述 |
|---|---|
| 🧠 AI 模型性能标准提升 | Grok 4 或将成为新的“性能标杆”,推动其他实验室加速创新 |
| 🤖 企业应用场景拓宽 | 更强的推理能力使 AI 可胜任更复杂的决策任务 |
| 🎓 教育与科研工具升级 | 可用于模拟考试、智能辅导、论文辅助写作等场景 |
| 🧑💻 开发者工具链强化 | 提升代码生成、调试、重构等开发效率 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...