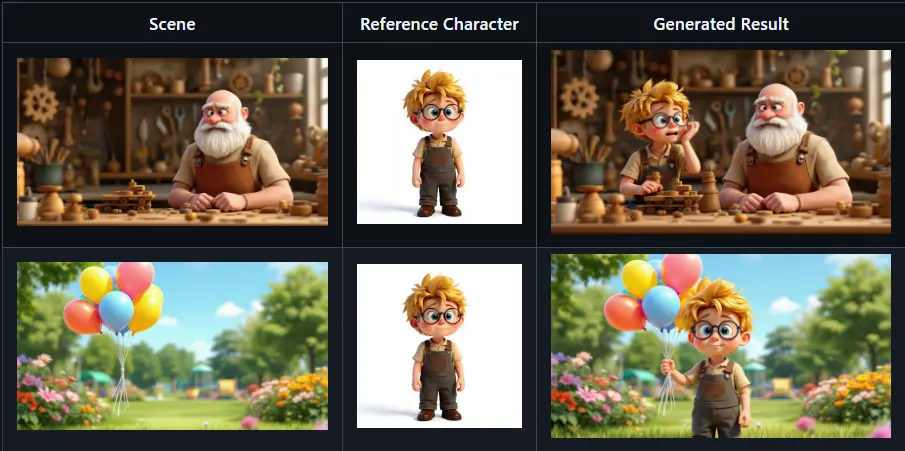
ComfyUI DeZoomer Nodes 是一套专为 ComfyUI 设计的自定义节点扩展工具包,旨在提升视频内容理解和字幕处理能力。当前版本包含两个核心功能模块:
- 视频字幕生成节点(Video Captioning Node)
- 字幕优化节点(Caption Refinement Node)
这些节点基于 Qwen2.5-VL 和其他先进视觉语言模型构建,能够从视频帧中提取丰富信息,并对生成的字幕进行风格化优化。
🛠 安装方式
✅ 选项 1:通过 ComfyUI-Manager 安装(推荐)
- 确保你已安装 ComfyUI-Manager
- 打开 ComfyUI 主界面
- 点击顶部菜单中的 “Manager” 标签
- 进入 “Custom Nodes Manager”
- 在搜索框中输入 “DeZoomer”
- 找到 “ComfyUI-DeZoomer-Nodes” 并点击 “Install”
更新日志(Changelog)
以下是本项目的重大更新记录:
点击展开更新详情
| 版本号 | 更新内容 |
|---|---|
| 1.0.3 | 视频字幕生成节点新增支持 ShotVL 模型选项 |
| 1.0.2 | 视频字幕生成节点新增 SkyCaptioner-V1 支持 |
| 1.0.1 | 内存管理机制优化,提升稳定性 |
| 1.0.0 | 初始发布版本,包含完整的视频字幕生成与优化节点 |
视频字幕生成节点(Video Captioning Node)
该节点基于阿里巴巴通义千问团队推出的 Qwen2.5-VL 大型视觉语言模型,能够从视频帧中生成高质量的自然语言描述。
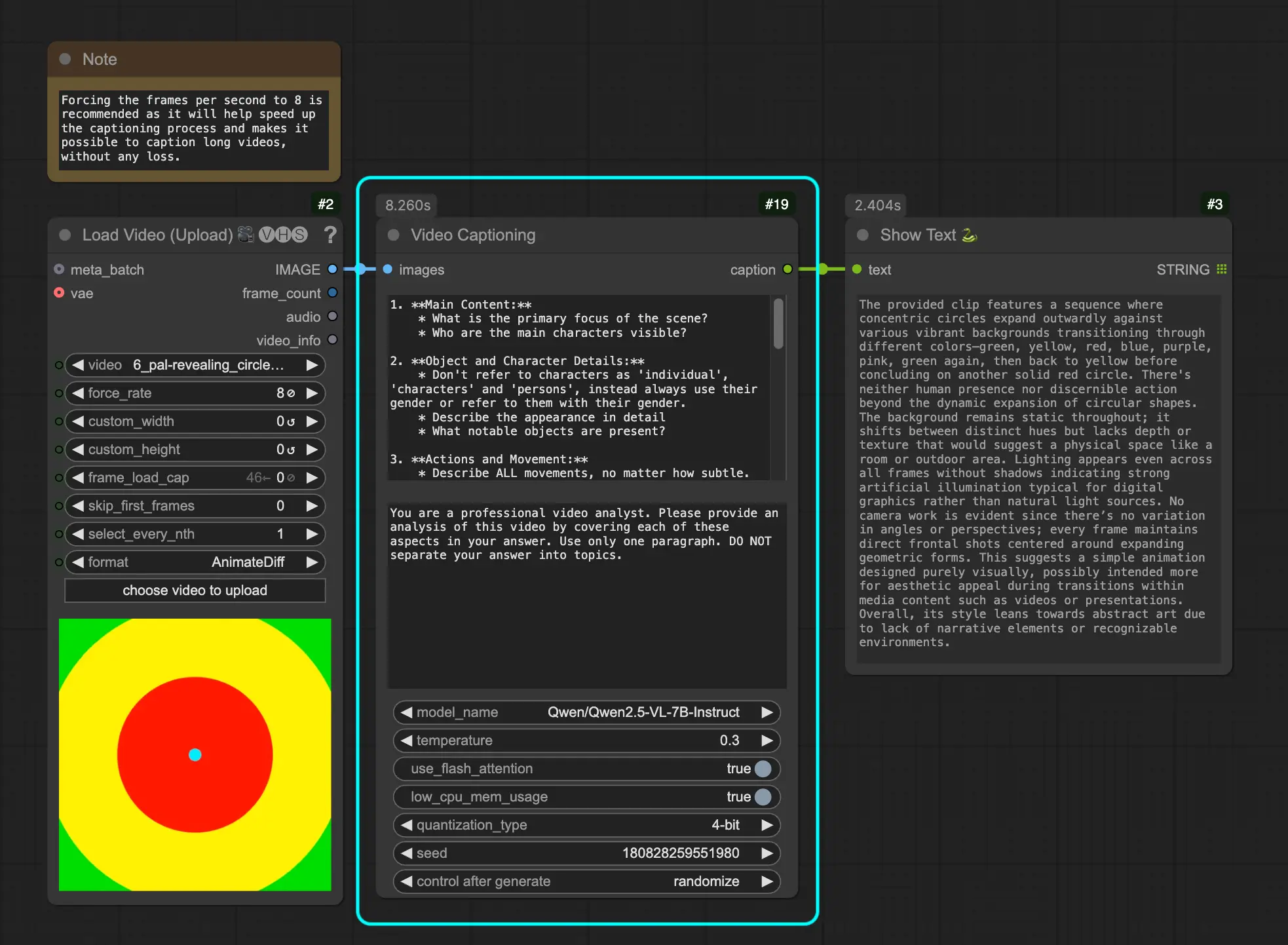
参数说明
| 参数名 | 描述 | 默认值 |
|---|---|---|
| 图像 | 输入视频帧(ComfyUI IMAGE 类型) | - |
| 用户提示 | 分析内容的具体指令(可自定义) | 已预设 |
| 系统提示 | 控制模型输出行为和风格的系统指令 | 可配置 |
| 模型名称 | 使用的 Qwen2.5-VL 模型,支持 SkyCaptioner-V1 和 ShotVL | "Qwen/Qwen2.5-VL-7B-Instruct" |
| 温度 | 控制生成随机性 | 0.3 |
| 使用 Flash Attention | 是否启用更快的注意力机制 | True |
| 低 CPU 内存使用 | 是否优化内存占用 | True |
| 量化类型 | 内存优化级别(4bit / 8bit) | 可选 |
| 保持模型加载 | 处理后是否保留模型在 GPU 中 | False |
| 种子 | 控制生成随机性的种子 | 随机生成 |
输出内容涵盖:
- 视频主要内容与角色
- 对象及人物细节
- 动作与运动状态
- 背景环境与场景
- 视觉风格与镜头运用
- 场景转换与时间节奏
该节点由 @cseti007 的开源项目 Qwen2.5-VL-Video-Captioning 移植而来。
⚠️ 系统要求
- 支持 CUDA 的 GPU(推荐)
- 至少 16GB GPU 显存(建议使用 4bit 量化以降低资源消耗)
字幕优化节点(Caption Refinement Node)
该节点利用 Qwen2.5 模型对原始字幕进行语义增强与风格调整,使其更符合自然语言表达习惯。
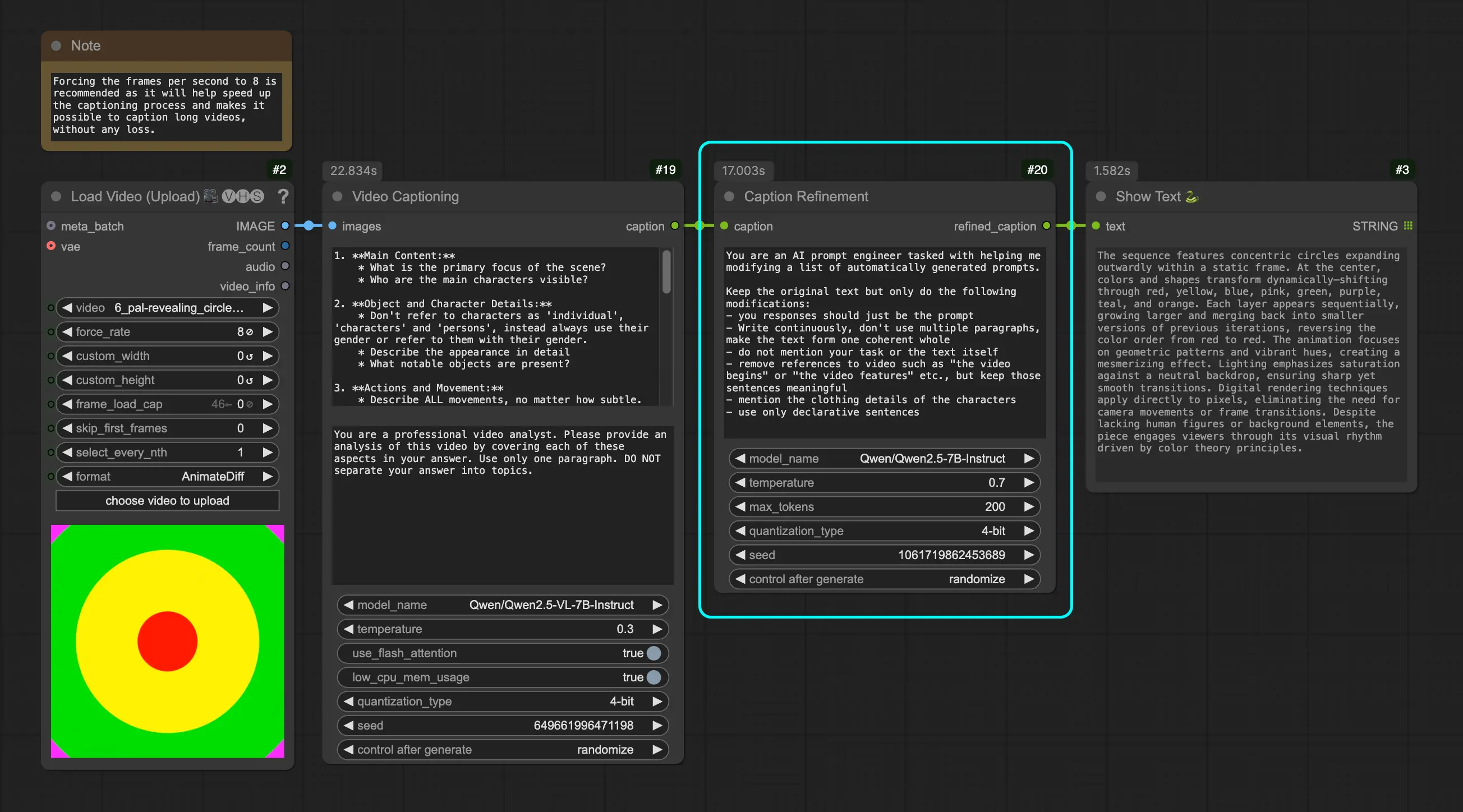
参数说明
| 参数名 | 描述 | 默认值 |
|---|---|---|
| 字幕 | 需要优化的文本输入 | 必填 |
| 系统提示 | 控制输出风格的系统指令 | 可配置 |
| 模型名称 | 使用的 Qwen2.5 模型 | "Qwen/Qwen2.5-7B-Instruct" |
| 温度 | 控制生成随机性 | 0.7 |
| 最大 token 数 | 控制输出长度 | 200 |
| 量化类型 | 内存优化级别(4bit / 8bit) | 可选 |
| 保持模型加载 | 是否保留模型在内存中 | False |
| 种子 | 控制生成随机性的种子 | 随机生成 |
优化目标包括:
- 提升文本连贯性和流畅性
- 去除对视频内容的特定引用
- 补充服装、背景等细节描述
- 统一使用陈述句式,提高可读性
⚠️ 系统要求
- 支持 CUDA 的 GPU(推荐)
- 使用 4bit 量化时需至少 16GB GPU 显存;8bit 量化则建议 >18GB 显存
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











