Nscale 与微软签署大规模 AI 基础设施协议,部署 20 万台英伟达 GPUAI 基础设施初创公司 Nscale 于本周三宣布,已与 微软 达成重大合作协议,将在欧美多地数据中心部署总计约 20 万台英伟达 GB300 GPU。这些算力将用于支持微软的 AI 服务扩展,覆盖欧...早报# Nscale# 微软5个月前0540
Meta与Arm合作扩展AI业务,AI 推理系统将迁移至 Arm Neoverse 平台Meta 正在将其核心 AI 系统——包括内容推荐、排名算法等——迁移至 Arm Neoverse 云端计算平台。这一合作标志着 Arm 首次深度参与超大规模社交平台的 AI 基础设施,也凸显 Met...早报# Arm# Meta5个月前0540
OpenAI 计划在 12 月为 ChatGPT 引入经年龄验证的成人内容支持OpenAI 首席执行官萨姆·奥尔特曼(Sam Altman)近日在 X 平台表示,公司将在 2025 年 12 月 推出更完善的年龄验证机制后,允许通过验证的成年用户在 ChatGPT 中进行涉及成...早报# ChatGPT# OpenAI# 成人内容5个月前0560
谷歌推出新账户恢复方式:可添加亲友作为“恢复联系人”谷歌近日推出多项安全与隐私更新,重点提升账户恢复能力,并加强 Android 平台对垃圾信息和诈骗的防护。其中最值得关注的是 “恢复联系人”(Recovery Contacts) 功能——允许用户将信...早报# 谷歌5个月前01730
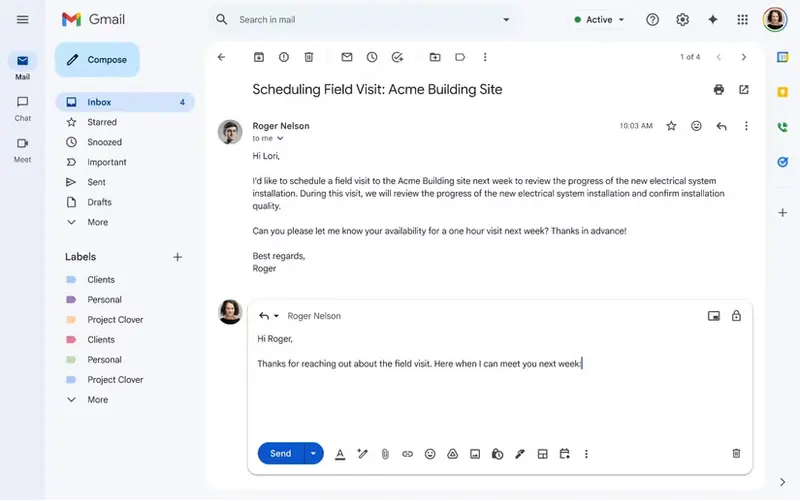
Gmail 新增“帮助我安排”功能,AI 自动帮你协调会议时间Gmail 正在推出一项虽小但实用的新功能——“帮助我安排”(Help me schedule),利用 Gemini AI 自动协调两人之间的会议时间,减少来回邮件的繁琐沟通。 如何工作? 当你在邮件...早报# Gmail5个月前02530
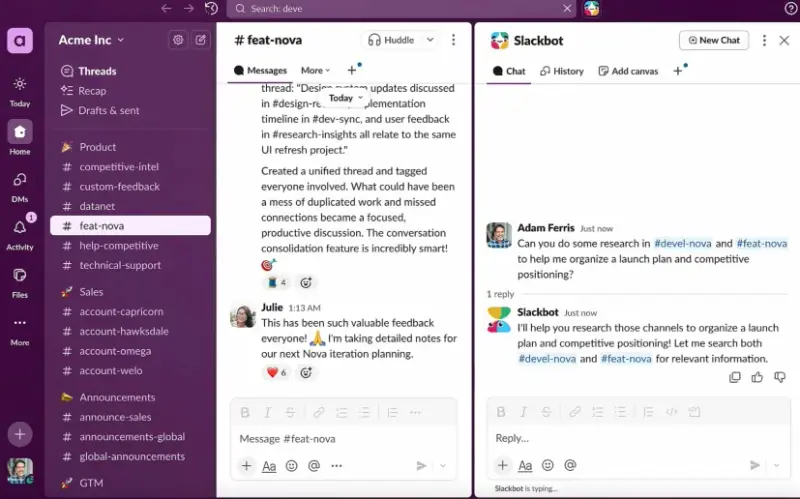
Slack 将 Slackbot 升级为 AI 助手,年底向所有用户推出Slack 正在对其内置机器人 Slackbot 进行重大升级,将其从一个基础的通知工具转变为个性化的 AI 工作助手。新版本已在 Salesforce 内部(约 7 万员工)试用,并正与部分客户联合...早报# AI 助手# Slack# Slackbot5个月前0920
加州立法规范 AI 伴侣聊天机器人,2026 年起实施2025 年 10 月 13 日,加州州长加文·纽森签署 SB 243 法案,使其成为美国首个对 AI 伴侣聊天机器人实施专项监管的州。该法律将于 2026 年 1 月 1 日正式生效,主要是保护儿童...早报# SB 243 法案# 加州5个月前01110
微软发布首款自研图像生成模型 MAI-Image-1,LMArena 排名进入前十微软 AI 近日宣布推出其首款完全内部研发的文生图模型——MAI-Image-1。该模型已在 AI 基准平台 LMArena 的文生图排行榜中进入前十名,标志着微软在生成式 AI 领域迈出关键一步。 ...早报# MAI-Image-1# 图像生成模型# 微软5个月前01480
法院终止 OpenAI 聊天日志保存令,用户删除记录将不再被强制保留一项针对 OpenAI 的数据保存令已被法院正式终止。这意味着该公司不再需要无限期保留所有用户已删除的 ChatGPT 聊天记录。 该保存令源于《纽约时报》于 2023 年 12 月提起的版权诉讼。原...早报# OpenAI5个月前0900
OpenAI 联手博通开发自研 AI 芯片,预计2026 年部署OpenAI 正加速摆脱对通用 GPU 的依赖。10 月 13 日,该公司宣布与半导体巨头 博通 签署多年协议,共同开发并部署 10 吉瓦(GW)的自定义 AI 加速器及配套机架系统。 根据协议,Op...早报# AI 芯片# OpenAI# 博通5个月前0500
OpenAI 称 GPT-5 为“最无偏见”模型,公布政治倾向压力测试结果OpenAI 于近日发布一项内部评估,称其最新模型 GPT-5(包括 GPT-5 Instant 和 GPT-5 Thinking)在政治偏见控制方面显著优于前代模型,是“迄今为止最接近无偏见”的版本...科普# GPT-5# OpenAI5个月前01070
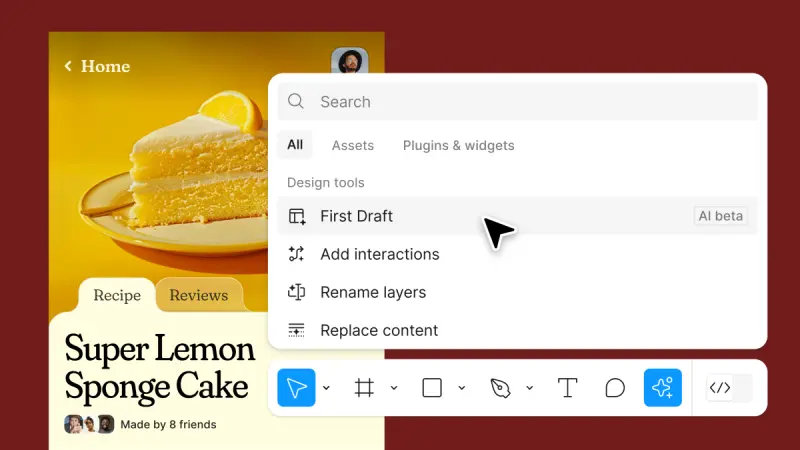
设计协作平台 Figma宣布与谷歌合作,将 Imagen 4 和 Gemini 引入设计平台设计协作平台 Figma 于近日宣布与谷歌达成合作,将 Gemini 2.5 Flash、Gemini 2.0 和 Imagen 4 等 AI 模型深度集成至其平台,进一步扩展其 AI 能力。此次合作...早报# Figma# 谷歌5个月前0890