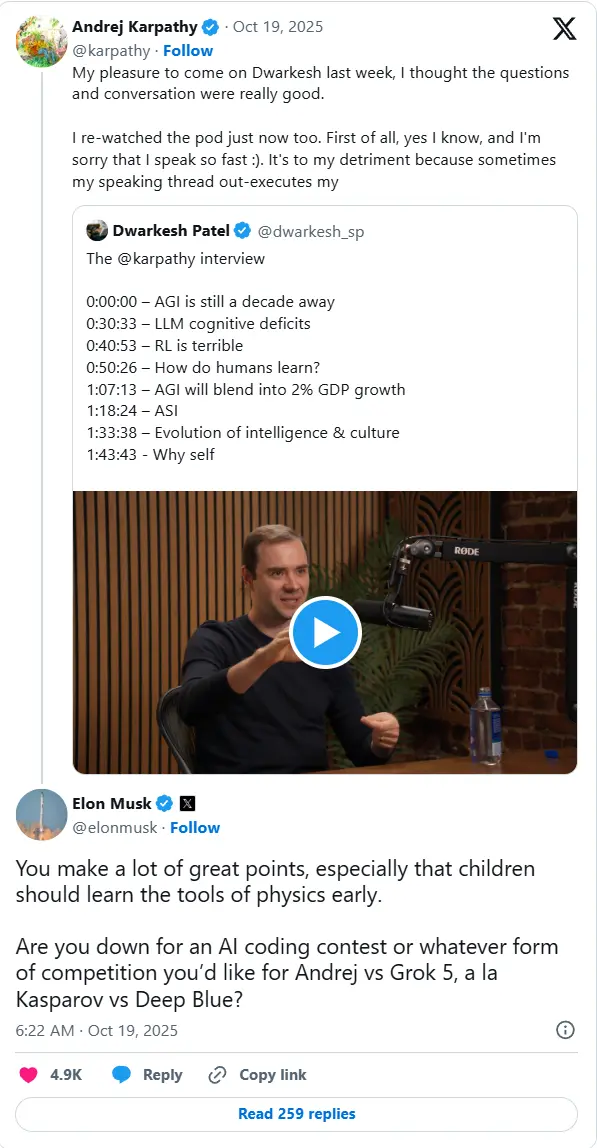OpenAI 推出 ChatGPT Atlas 浏览器:macOS 已上线,Windows 11 版即将发布OpenAI 正式发布其首款 AI 浏览器 ChatGPT Atlas,目前已在 macOS 平台开放下载,Windows 11 版本正在开发中,后续还将登陆 iOS 和 Android。 地址:ht...早报# ChatGPT Atlas# OpenAI5个月前04020
Anthropic 推出 Claude for Life Sciences:AI 进军生物医学领域在多家 AI 公司因滥用风险引发争议的同时,Anthropic 正将大模型能力聚焦于高价值领域——生命科学。近日,该公司正式推出 Claude for Life Sciences,基于优化后的 Cla...早报# Anthropic# Claude for Life Sciences5个月前0890
Claude Code 网页版上线:在浏览器里直接写代码、推 PRAnthropic 宣布 Claude Code 网页版(beta)正式上线,面向 Claude Pro 和 Max 订阅用户开放。开发者现在无需本地环境,即可在浏览器中完成完整的编码任务——从理解需...早报# Claude Code 网页版5个月前0650
Adobe 推出 AI Foundry服务:为企业打造专属生成式 AI 模型Adobe 正式推出 Adobe AI Foundry,一项面向企业的定制化生成式 AI 服务,允许品牌基于自身知识产权(IP)和视觉资产,构建专属的文本、图像、视频乃至 3D 内容生成模型。 基于 ...早报# Adobe# AI Foundry5个月前0600
马斯克邀 Karpathy 与 Grok 5 编程对决,遭婉拒:AI 时代不需要“深蓝式”表演埃隆·马斯克近日在 X 平台上向知名 AI 研究员 Andrej Karpathy 发起公开挑战:让 xAI 最新模型 Grok 5 与 Karpathy 本人进行一场编程对决,并将此比作 1997 ...百科# Andrej Karpathy# Grok 5# 马斯克5个月前0460
阿里云新系统 Aegaeon:用 213 个 GPU 实现 1,192 个的推理能力阿里云在 ACM SOSP 2025(操作系统原理研讨会)上发表了一篇经同行评审的论文,介绍其名为 Aegaeon 的新型 GPU 池化系统。该系统在阿里云 Model Studio 平台的多月生产测...新技术# Aegaeon# 阿里云5个月前0950
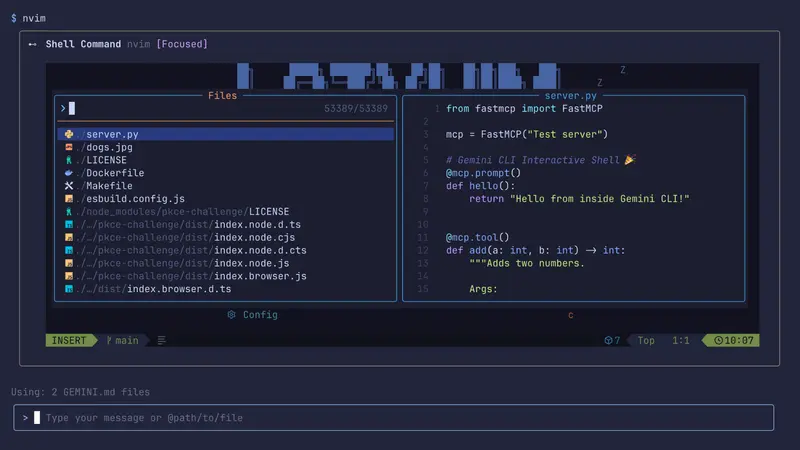
谷歌Gemini CLI 0.9.0 发布:内置交互式 Shell,支持 vim、git、top 等终端工具谷歌正式推出 Gemini CLI v0.9.0,最大亮点是新增内置交互式 Shell,开发者现在可直接在 CLI 内运行 vim、top、htop、git rebase -i 等依赖终端交互的命令...早报# Gemini CLI# 谷歌5个月前01730
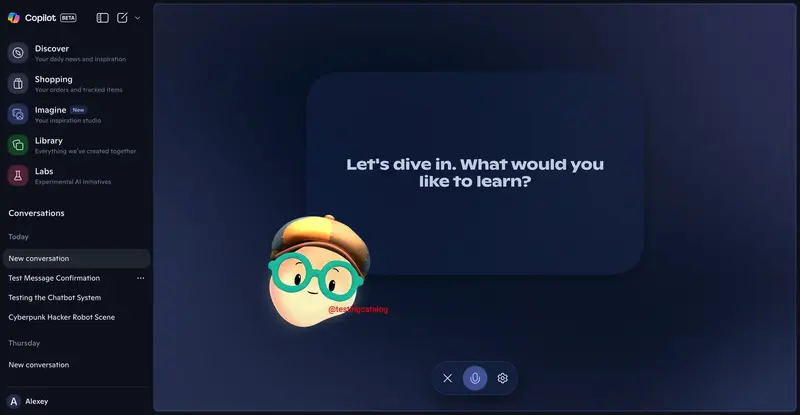
微软测试 Copilot 学习模式:新导师“Mico”登场微软正在内部测试 Copilot 的全新学习模式(Learning Mode),专为教育场景设计。该模式引入了一个名为 Mico 的 AI 导师角色,并支持语音驱动的学术对话,旨在为学生和自学者提供更...早报# Copilot# 学习模式# 微软5个月前01090
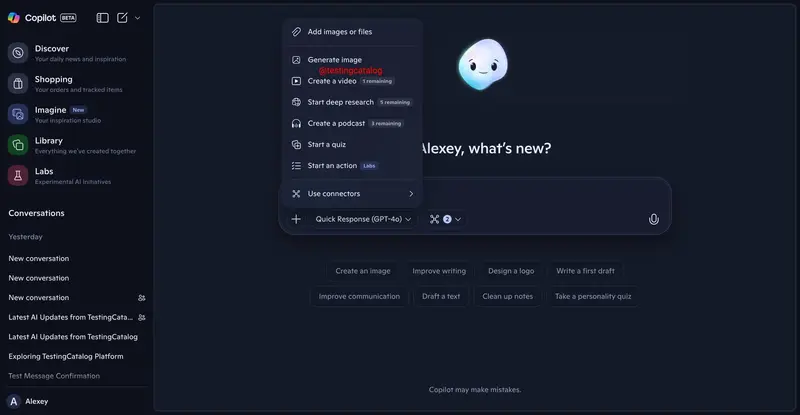
微软测试 Copilot 集成 Sora 2 视频生成与新购物标签微软正在对 Copilot 进行两项重要更新:集成 OpenAI 最新的 Sora 2 视频生成能力,并引入全新的 “Shopping”(购物)标签,进一步强化其作为 AI 驱动生产力与商业平台的定位...早报# Copilot# Sora 2# 微软5个月前0750
Manus 1.5 发布:无需编程,一句话生成全栈 AI 网页应用Manus 正式推出 1.5 版本,大幅升级其 AI 智能体能力,支持用户仅通过自然语言提示,即可生成包含前端、后端、数据库、认证和 AI 功能的完整网页应用,全程无需编写一行代码。 核心升级亮点 无...早报# Manus5个月前01320
维基百科流量下滑:AI 摘要和短视频正在改变人们获取知识的方式维基百科常被称为“互联网最后的净土”——一个由志愿者维护、内容可靠、广告极少的开放知识库。但即便是它,也难以完全抵御当前网络生态的深层变化。 根据维基媒体基金会产品主管 Marshall Miller...早报# AI 摘要# 维基百科5个月前01310
Windows11 画图新增 AI 动画与智能修图功能Windows 11 自带的画图软件,在过去一年里不断升级。最近,它又加入了两项新的 AI 实验功能:图像转动画和生成式图像编辑。用户现在可以把静态图片变成动态短片,也能通过文字指令直接编辑画面内容...早报# AI 动画# Windows# 智能修图5个月前02310