Sora 新增肖像保护机制,历史人物可申请禁用OpenAI 于本周四宣布,已暂停用户通过其 AI 视频模型 Sora 生成与马丁·路德·金博士形象相似的内容。此举是在金博士遗产管理委员会提出正式请求后实施的。此前,部分用户利用 Sora 生成了被...早报# OpenAI# Sora5个月前0900
Facebook 推出 AI 照片编辑建议功能,可访问手机未分享照片Meta 近日宣布,其 AI 照片编辑建议功能 已向 美国和加拿大所有 Facebook 用户 正式开放。该功能可为用户手机相机胶卷中尚未分享的照片提供 AI 生成的编辑建议(如拼贴、回顾、风格重绘...早报# AI 照片编辑# Facebook5个月前0560
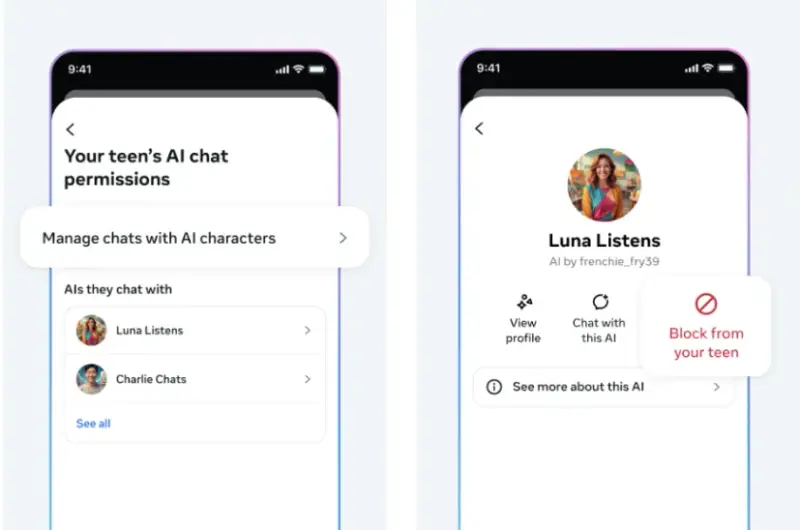
Meta 为 Instagram 青少年用户新增 AI 聊天限制,家长可完全禁用Meta 近日宣布,将于 2025 年初在 Instagram 上推出针对青少年用户的 AI 聊天控制功能,允许家长对其子女与 AI 角色的互动进行管理。该功能目前仅面向 美国、英国、加拿大和澳大利亚...早报# Instagram# Meta5个月前0470
Claude深度集成微软365:Teams/Outlook/OneDrive数据可直接调用Anthropic 与微软在 AI 模型及服务领域的合作正持续加深,近期双方合作迎来关键进展 ——Anthropic 宣布将其 Claude AI 助手与 Microsoft 365 系列服务深度集成...早报# Claude# Microsoft 3655个月前0550
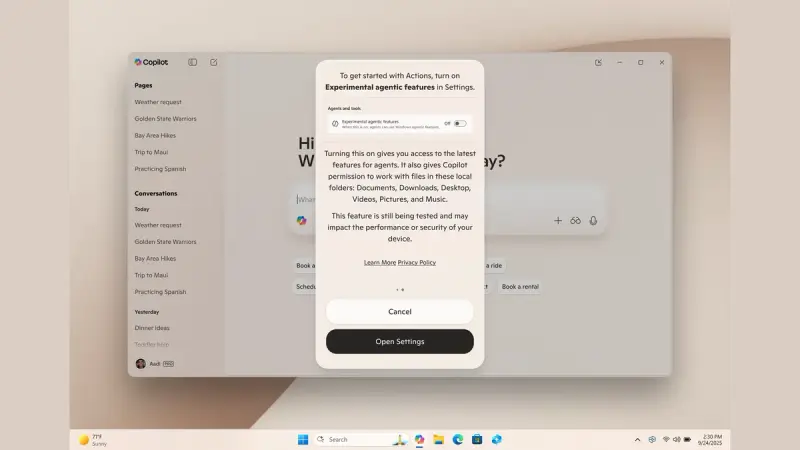
Windows 11 Copilot 新增语音交互与屏幕感知能力微软近期宣布多项 Copilot 功能更新,进一步将其集成到 Windows 11 系统中。新功能强调语音作为第三种输入方式(继键盘、鼠标之后),并允许 Copilot 在用户授权下查看屏幕内容以提供...早报# Copilot# Windows 115个月前0750
Anthropic 推出 Claude “技能”功能,提升 AI 智能体在工作场景中的实用性Anthropic 于本周四正式推出 Claude Skills(技能),一项让 AI智能体更高效完成特定工作任务的新功能。该功能紧随 OpenAI 在 DevDay 上发布的 AgentKit,标志...早报# Anthropic# Claude Skills5个月前01540
Pinterest 推出新控制选项,允许用户减少信息流中的 AI 生成内容为回应用户对 AI 生成内容增多的反馈,Pinterest 于本周四正式上线新工具,让用户可主动限制在信息流中看到的生成式 AI(GenAI)图像数量。 用户现可在 “设置 > 优化你的推荐” ...早报# Pinterest5个月前0760
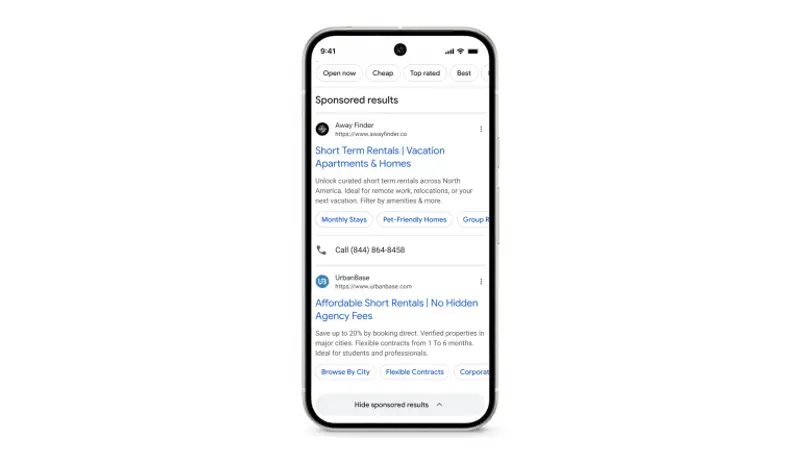
谷歌更新搜索与发现页面:可折叠广告、AI 概述优化与动态资讯谷歌宣布对 搜索结果页 和 谷歌应用发现页 进行多项更新,涵盖广告展示方式、AI 功能整合与内容导航体验。更新将逐步在 桌面端和移动端 推出。 1. 搜索广告支持“折叠”,但未完全隐藏 为提升用户体验...早报# 谷歌5个月前0880
沃尔玛与 OpenAI 合作:用户将可通过 ChatGPT 直接购买商品沃尔玛于本周二宣布与 OpenAI 达成新合作,未来用户将能在 ChatGPT 应用内直接购买沃尔玛商品,涵盖杂货(非生鲜)、家居必需品等品类,并支持即时结算。 该功能预计于 2025 年秋季全面上线...早报# OpenAI# 沃尔玛5个月前0680
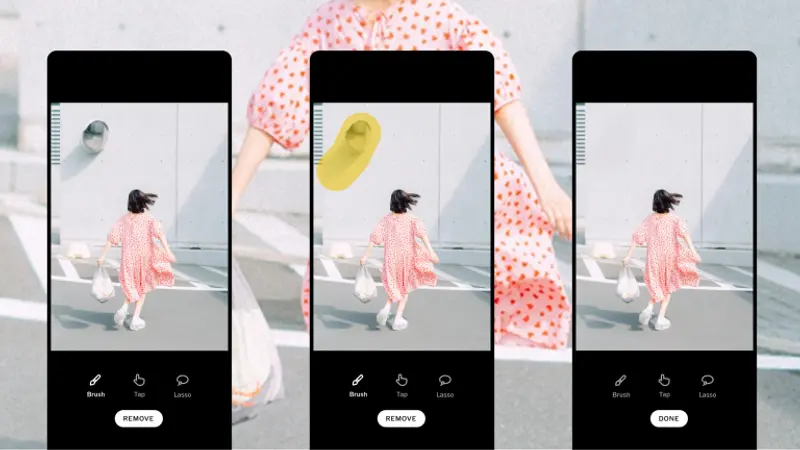
摄影应用VSCO 推出 AI 编辑功能,支持 RAW 文件与非破坏性编辑摄影应用 VSCO 近日更新其移动端应用,新增 AI 图像编辑套件,并首次支持 高分辨率 RAW 文件 和 非破坏性编辑。新功能集中于名为 “AI Lab” 的独立选项卡,面向 Pro 订阅用户开放...早报# AI 编辑# VSCO5个月前01960
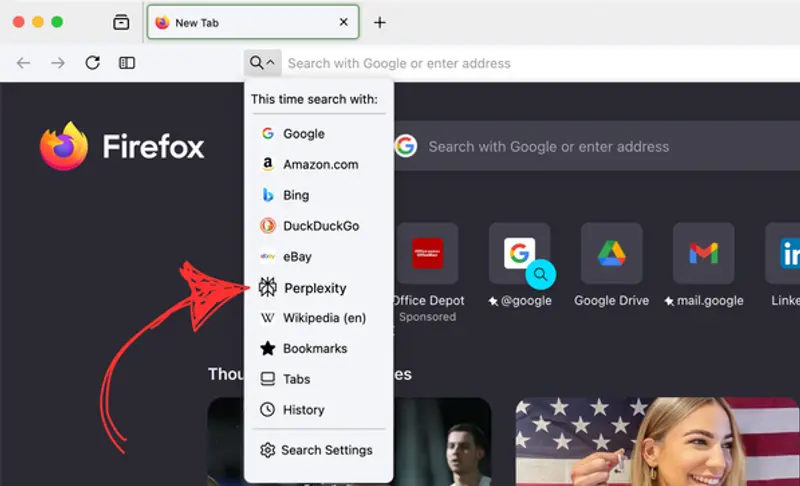
Firefox 新增 AI 搜索引擎Perplexity选项,支持全球桌面用户Mozilla 于本周二宣布,AI 搜索引擎Perplexity 正式加入 Firefox 桌面版的搜索引擎列表,面向全球用户开放。此前该功能仅在美、英、德等市场试点,因用户反馈积极而全面推广,移动端...早报# AI 搜索引擎# Firefox# Perplexity5个月前01430
Spotify 升级 AI DJ:支持文本输入,并推进“艺术家优先”的 AI 音乐战略Spotify 于本周三宣布对其 AI DJ 功能 进行重要升级:Premium 订阅用户 现在可通过 文本消息 向 AI DJ 发送音乐请求,不再仅限于语音命令。该功能目前支持 英语和西班牙语,覆盖...早报# AI DJ# Spotify5个月前0790