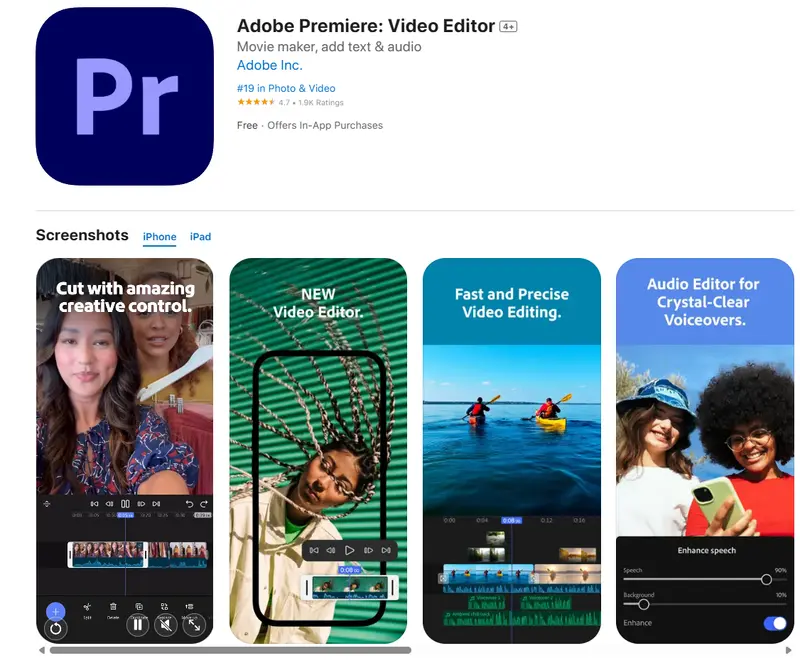
Adobe Premiere 免费登陆 iPhone:功能强大,但同步需订阅Adobe 近日正式推出 Premiere 移动版(iPhone),作为一款免费独立应用上架 App Store。这是对已停更的 Premiere Rush 的直接替代,也标志着 Adobe 首次将旗...早报# Adobe# Adobe Premiere5个月前0530
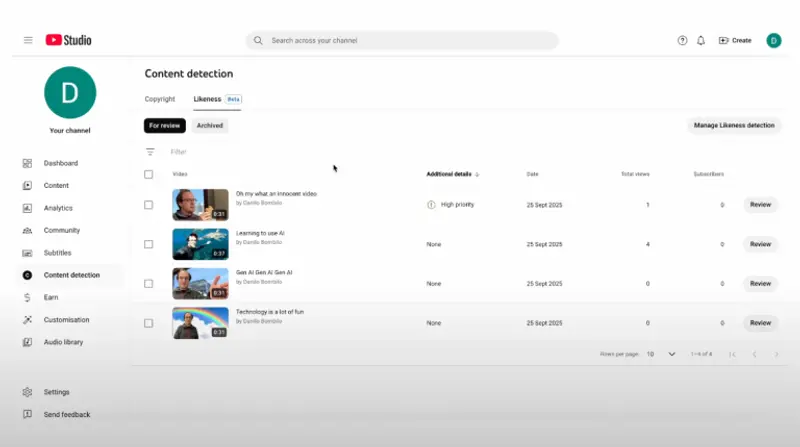
YouTube 正式推出肖像检测技术,帮助创作者移除 AI 滥用内容YouTube 于上周二宣布,其 AI 肖像检测技术 已结束试点阶段,正式向 YouTube 合作伙伴计划中的合格创作者开放。该工具旨在帮助创作者识别并移除未经许可使用其面部或声音的 AI 生成内容...早报# YouTube5个月前0510
Netflix 全力投入生成式 AI,但坚持“工具而非替代”立场在最新发布的季度财报中,Netflix 明确表态:公司正“全力以赴”探索生成式 AI 的应用,但强调其定位是提升创作者效率的辅助工具,而非内容创作的核心。 “需要一位伟大的艺术家才能创造出伟大的作品...早报# Netflix5个月前0810
Snapchat 首次向美国免费用户开放 AI 图像生成镜头 “Imagine Lens”Snapchat 正式将旗下首个开放提示式 AI 图像生成镜头——“Imagine Lens”——免费开放给所有美国用户。此前,该功能仅限 Lens+ 或 Snapchat Platinum 付费订阅...早报# Imagine Lens# Snapchat5个月前0710
Wonder Studios 获 1200 万美元融资,推动 AI 与好莱坞内容创作融合总部位于伦敦的 AI 创意工作室 Wonder Studios 宣布完成 1200 万美元种子轮融资,由 Atomico 领投,现有投资者 LocalGlobe 和 Blackbird 跟投。值得注意...早报# Wonder Studios# 好莱坞5个月前0620
微软发布 Edge Copilot 模式重大更新微软于本周四宣布对其 Edge 浏览器中的 Copilot 模式进行重大升级,引入多项深度集成 AI 功能,包括跨标签页信息推理、表单自动填写、酒店预订等“Actions”,以及追踪用户浏览路径的“J...早报# Copilot 模式# Edge# 微软5个月前0470
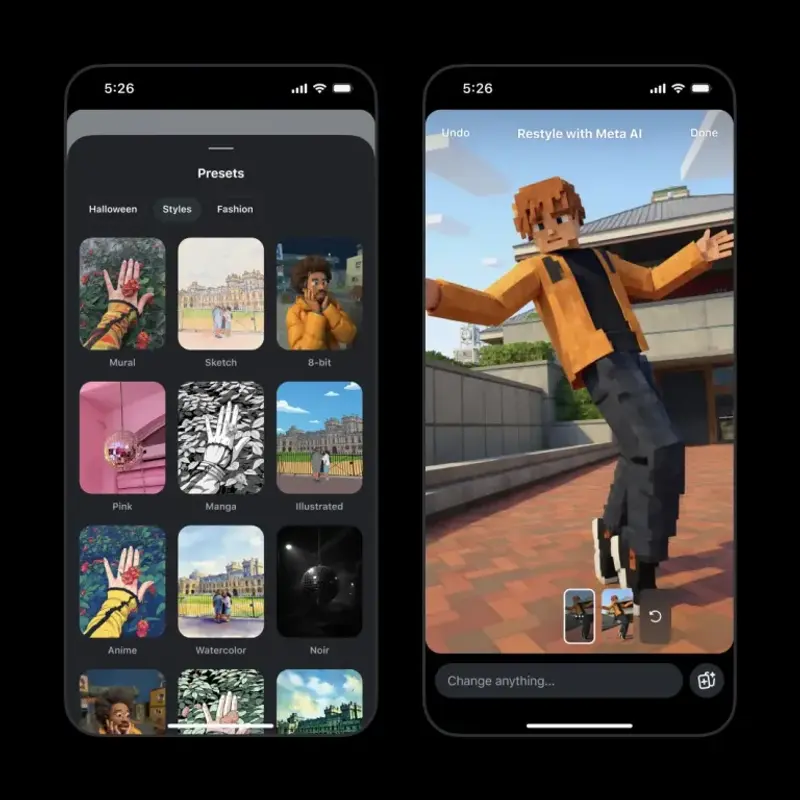
Instagram 故事新增 Meta AI 编辑功能:输入文字即可改图换景Meta 正将旗下强大的 AI 图像生成与编辑能力直接整合进 Instagram 故事。用户现在无需跳转至 Meta AI 聊天界面,即可在发布故事时,通过输入文本提示,实时对照片或视频进行智能编辑...早报# Instagram# Meta AI5个月前0690
多名用户向 FTC 投诉 ChatGPT 引发心理困扰,呼吁加强 AI 安全监管据《Wired》报道,自 2022 年 11 月以来,至少七名用户已向美国联邦贸易委员会(FTC)提交正式投诉,指称使用 OpenAI 的 ChatGPT 导致其出现妄想、偏执、情绪崩溃等严重心理反应...早报# ChatGPT5个月前01020
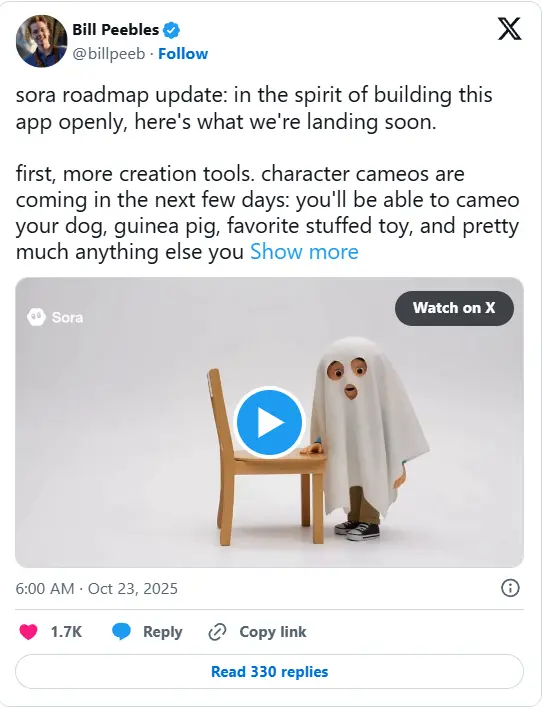
OpenAI Sora 推出“客串角色”功能,支持宠物和物品生成 AI 视频OpenAI 正为其 AI 视频生成应用 Sora 推出多项新功能。自九月底上线以来,Sora 在美国和加拿大 App Store 持续位居榜首,第三方数据平台 Appfigures 估计其下载量已超...早报# OpenAI# Sora5个月前01470
Anthropic 扩大谷歌云合作,2026年将获超1GW TPU算力Anthropic 与谷歌云近日宣布达成一项重大扩容协议:到 2026 年,Anthropic 将可使用 多达一百万个谷歌 TPU 芯片,获得 超过 1 吉瓦(GW)的 AI 计算能力,用于训练和部署...早报# Anthropic# 谷歌云5个月前0560
OpenAI 收购 macOS 自然语言工具 Sky,强化 ChatGPT 系统级集成OpenAI 宣布收购 Software Applications Incorporated(SAI),该公司是 macOS 自然语言交互工具 Sky 的开发者。此次收购将 Sky 的深度系统集成能力...早报# macOS# OpenAI# Sky5个月前0970
微软为 Copilot 加入“数字伙伴”Mico,强化个性化与上下文理解微软为 Copilot 推出多项重要更新,包括全新的交互式助手 Mico、长期记忆能力、群组协作功能以及面向学生用户的 Learn Live 学习模式。这些改进旨在让 Copilot 从一个文本对话工...早报# Copilot# Mico# 微软5个月前0550