谷歌NotebookLM现已支持深度研究功能谷歌正将其"深度研究"功能引入AI研究笔记应用NotebookLM。该功能此前已集成于Gemini应用及谷歌搜索的AI模式,能通过多步骤搜索生成详细报告。 在NotebookLM中,深度研究可制定研究...早报# NotebookLM# 深度研究# 谷歌4个月前0300
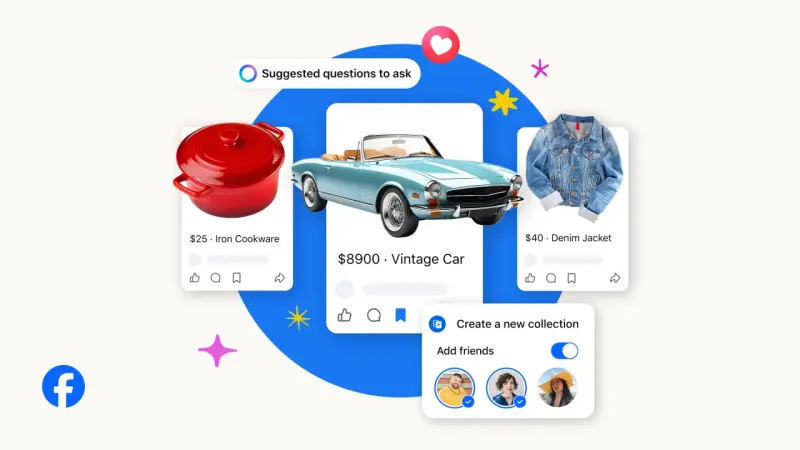
Meta AI驱动Facebook Marketplace大翻新:社交购物+AI加持,二手购物更高效Meta宣布对Facebook Marketplace进行AI驱动的重大升级,以“社交购物”为核心,叠加AI辅助功能,同时新增合集、共同购买、商品评论等实用特性,还扩容复古时尚类目、优化寄送结账体验...早报# Facebook Marketplace# Meta AI4个月前01780
OpenAI向开发者发布具备自适应推理能力的GPT-5.1昨天,OpenAI刚为ChatGPT用户推出GPT-5.1系列模型,今日便宣布将该系列扩展至开发者API平台。GPT-5.1的核心亮点在于其自适应推理能力:面对简单任务时,模型将减少“思考”所需的to...早报# GPT-5.1# OpenAI4个月前0350
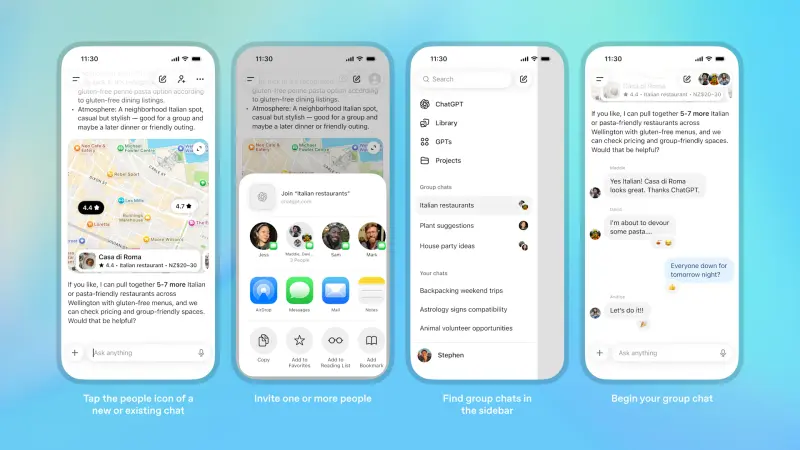
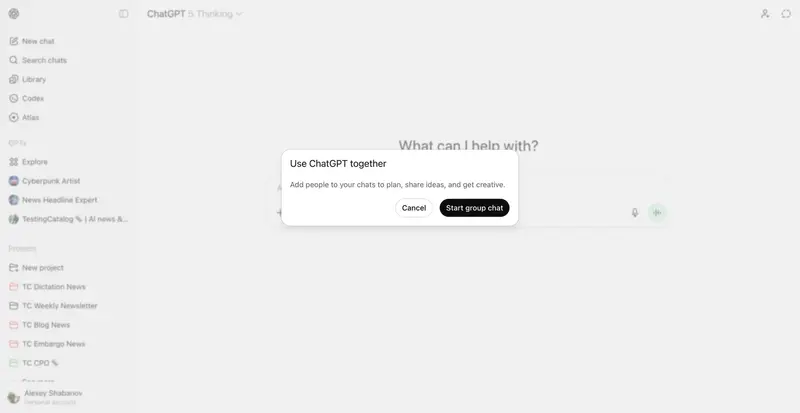
ChatGPT 推出群聊功能:20 人协作 + GPT-5.1 Auto 驱动,多区域率先上线OpenAI今日宣布,将在特定区域为ChatGPT用户推出全新的协作体验。这项新的群聊功能将允许用户在与他人协作时,随时调用AI助手进行辅助。 以下是ChatGPT群聊功能的具体运作方式: 用户可通过...早报# ChatGPT# GPT-5.1 Auto# OpenAI4个月前0200
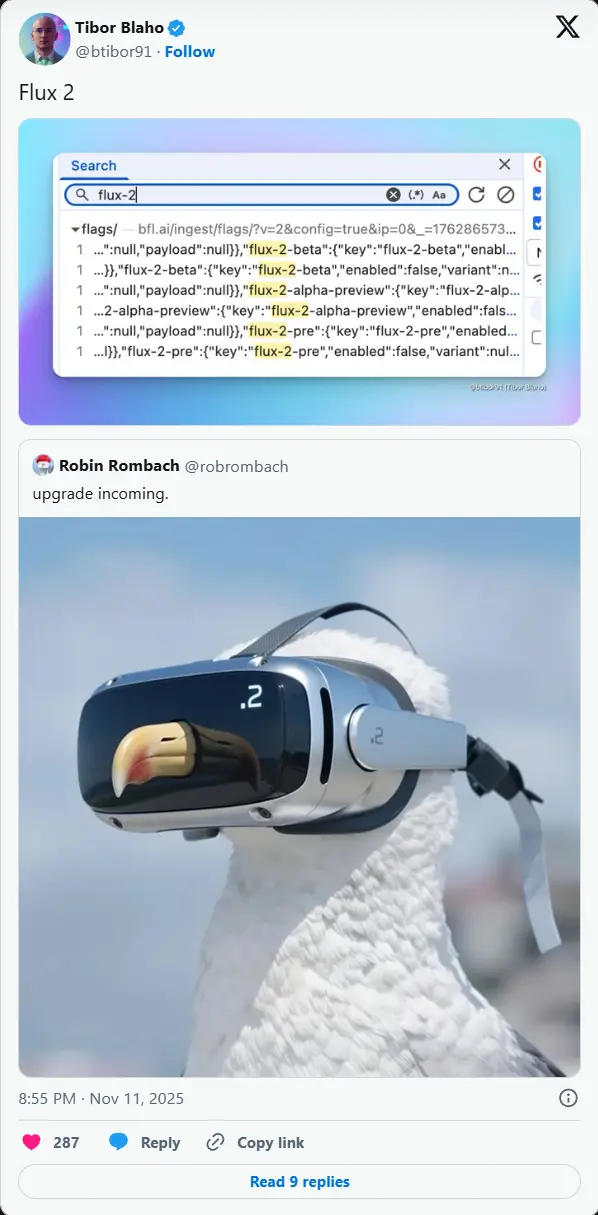
Black Forest Labs 即将发布 Flux 2 Pro:完成多轮内部测试,专业级AI图像生成将迎重大更新以高质量图像生成能力闻名的Black Forest Labs,近日通过内部测试痕迹与公开预告,暗示其重磅产品Flux 2系列即将推出核心版本——Flux 2 Pro。这款原Flux 1的续作在完成al...早报# Black Forest Labs# Flux 2 Pro4个月前01230
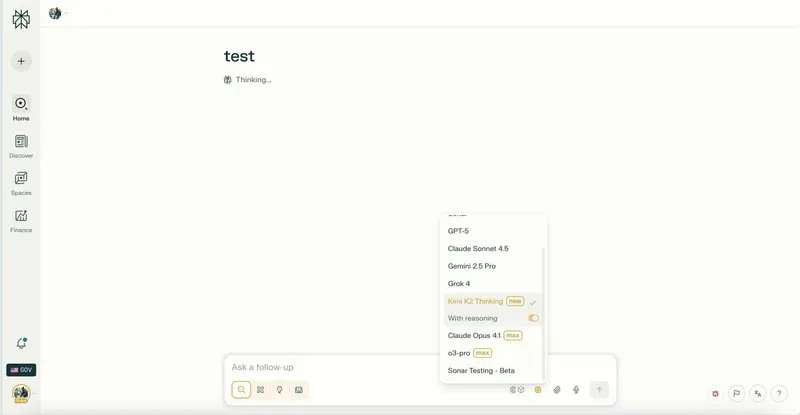
Perplexity即将集成Kimi K2 Thinking模型,支持区域数据驻留与推理切换Perplexity 正在准备上线 Kimi K2 Thinking 模型,作为其AI搜索服务的新增推理引擎。此举延续了其“集成顶尖开源模型 + 区域化部署 + 场景化微调”的产品策略,进一步强化其在...早报# Kimi K2 Thinking# Perplexity4个月前0240
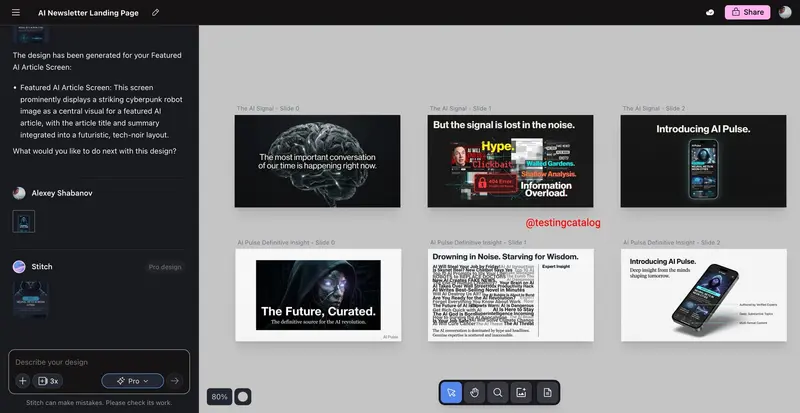
谷歌Stitch升级:支持设计想法自动生成pitch deck,新增热图、原型与多平台导出谷歌正在对 AI 设计工具 Stitch 进行一系列重要升级,旨在打破其单一“设计工具”的属性,升级为贯穿设计、导出、原型制作和演示全流程的跨工作流构建器。这些新功能将更精准地服务产品设计师、前端开发...早报# Stitch# 谷歌4个月前0220
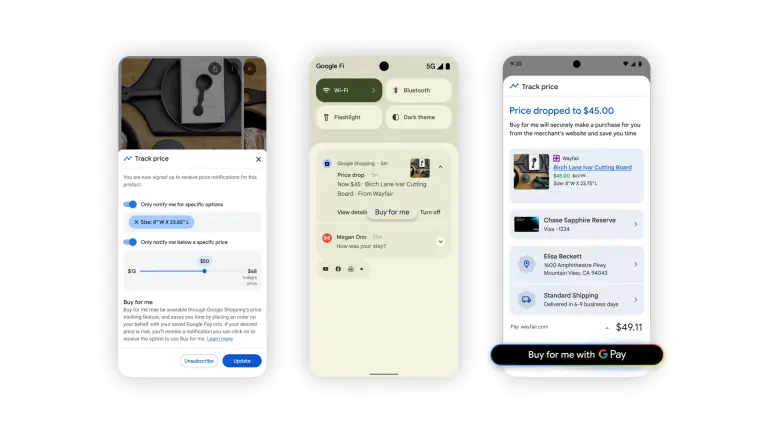
谷歌升级AI购物功能:对话式搜索、代理结账+AI代客致电,简化假日购物流程假日季来临之际,谷歌推出了一系列AI购物新功能,涵盖对话式购物搜索、代理结账、AI代客致电商家等核心能力,旨在解决在线购物中的繁琐环节,让消费过程更自然、更高效。 谷歌广告与商务副总裁兼总经理维迪亚...早报# 谷歌4个月前0810
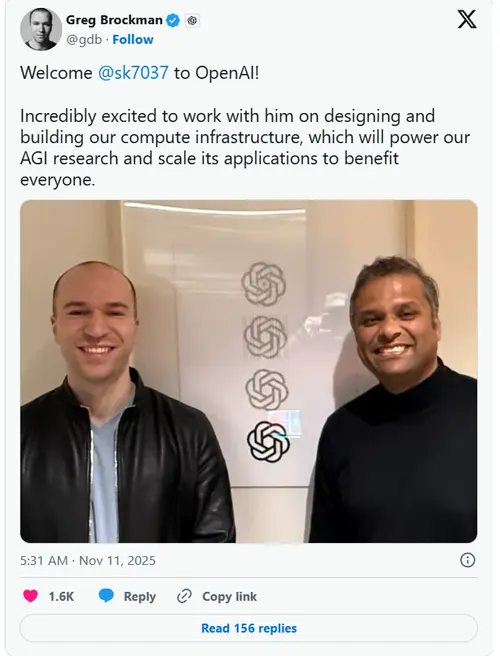
英特尔CTO兼AI负责人入职7个月跳槽OpenAI,将主导计算基础设施建设英特尔近期遭遇AI核心管理层动荡:首席技术官(CTO)兼人工智能负责人萨钦·卡蒂已正式辞任,入职仅七个月后转投OpenAI,将负责该公司计算基础设施体系的规划与建设。这一变动距其直属下属、英特尔数据中...早报# OpenAI# 英特尔4个月前0180
ElevenLabs推出名人AI语音市场:品牌可授权使用迈克尔·凯恩、丽莎·明尼里等标志性声线AI音频初创公司ElevenLabs正式推出在线语音市场,允许企业有偿使用经授权复刻的知名人物AI语音进行内容创作与广告投放。这家公司表示,其新推出的标志性语音市场通过采用"经本人同意、以表演者权益为...早报# ElevenLabs4个月前0470
ChatGPT 即将推出群聊功能:支持自定义提示+AI响应控制,12月上线可期OpenAI 正为 ChatGPT 开发群聊功能,该功能将允许多个用户加入共享对话,在同一聊天流中相互互动并与 AI 协作,预计将于12月随季节性更新推出。与微软 Copilot 已有的群组功能相比...早报# ChatGPT# 群聊4个月前01310
谷歌测试 Creative Canvas:在 Gemini 中直接生成可交互画布与网页游戏谷歌正在内部测试两项新功能:Visual Layout 和 Creative Canvas,提升 Gemini 在生成内容后的交互能力。 这两项功能均聚焦于改变AI输出的呈现形式,从静态文本或图片,转...早报# Creative Canvas# 谷歌4个月前0280