Perplexity 正在准备上线 Kimi K2 Thinking 模型,作为其AI搜索服务的新增推理引擎。此举延续了其“集成顶尖开源模型 + 区域化部署 + 场景化微调”的产品策略,进一步强化其在AI搜索领域的差异化竞争力。
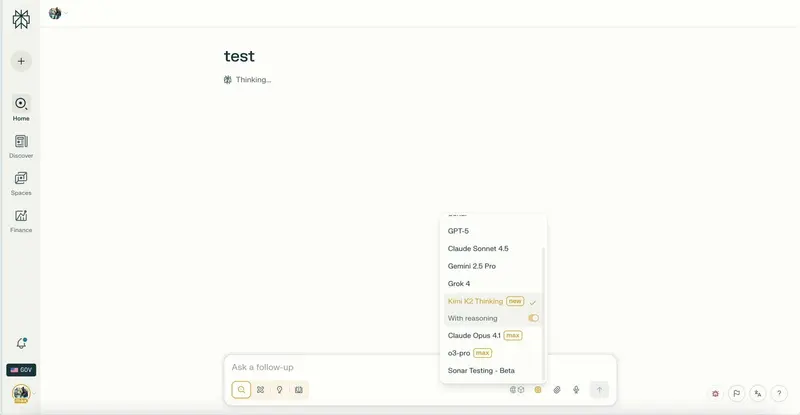
Kimi K2 Thinking 是由月之暗面(Moonshot AI)推出的开源大模型,以高推理能力、低幻觉率、可微调性强著称,已被多个研究实验室和企业用于定制化部署,性能接近GPT-4o、Claude 3等主流闭源模型。
核心价值:区域数据驻留 + 双模式推理
Perplexity 将采用与此前部署 DeepSeek 类似的架构:
- Kimi K2 Thinking 版本:部署于特定司法管辖区服务器(如美国境内),确保用户查询与响应数据不跨境传输,满足金融、医疗、政府等对数据主权有严格要求的组织需求。
- 标准版本:继续使用现有高性能模型(如 Claude、GPT 系列),适用于对延迟敏感、无数据驻留要求的普通用户。
用户可在界面中自由切换两种推理模式:
- 选“Kimi K2 Thinking” → 数据本地化,合规优先
- 选“标准模式” → 响应更快,能力更强
这一设计让 Perplexity 不仅是“更好的搜索”,更是“可信任的搜索”。
技术演进:从“搜索增强”到“思考型推理”
Kimi K2 Thinking 的“Thinking”版本专为多步推理任务优化,擅长:
- 复杂问题拆解
- 多源信息交叉验证
- 长链逻辑推导
这与 Perplexity 的核心使命高度契合:不是返回网页摘要,而是给出有依据的结论。
此前,Perplexity 已发布论文,研究如何通过Kimi K2 非思考版本降低推理延迟,表明其正系统性地优化模型在真实搜索场景下的表现。
有迹象显示,Perplexity 自研的 Sonar 模型系列(用于增强搜索结果相关性与摘要质量)可能将在未来基于 Kimi K2 架构进行升级。若成真,将意味着:
- 搜索结果更准确
- 引用来源更可靠
- 回答更接近人类专家推理路径
战略意图:开源为锚,合规为盾,搜索为矛
Perplexity 的产品路径清晰:
| 策略 | 实现方式 |
|---|---|
| 集成开源模型 | DeepSeek、Kimi K2、Llama 等,避免供应商锁定 |
| 区域化部署 | 数据不出境,满足GDPR、CCPA、中国数据安全法等合规要求 |
| 场景化微调 | Sonar 模型优化搜索意图理解,Kimi K2 Thinking 优化复杂推理 |
| 用户控制权 | 提供模型切换,赋予用户选择权而非被动接受 |
在 OpenAI、谷歌、Anthropic 控制大模型生态的背景下,Perplexity 选择了一条非对称竞争路线:
不拼参数,拼可信度;
不靠闭源,靠开放与合规。
当前状态与预期
- 当前状态:Kimi K2 Thinking 已在部分测试用户界面中短暂出现,随后被撤回,尚未正式开放。
- 预计上线时间:2025年Q2,可能伴随静默发布或官方公告。
- 访问方式:预计以“模型切换”形式出现在高级设置或企业账户中,非默认选项。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











