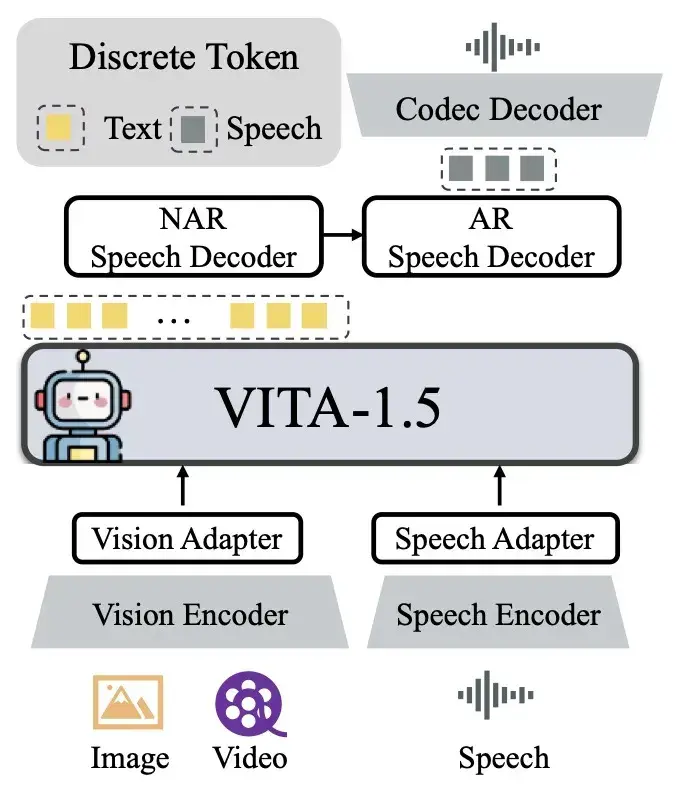
开源多模态视频语音大模型VITA-1.5: 基于Qwen2.5模型,实现接近实时的视觉和语音交互能力随着多模态大语言模型(MLLMs)的发展,如何有效地整合视觉、语言和语音成为了人工智能领域面临的一个重要挑战。VITA-1.5 是由南京大学(NJU)、腾讯优图实验室(Tencent Youtu La...语音模型# Qwen2.5模型# VITA-1.512个月前03360