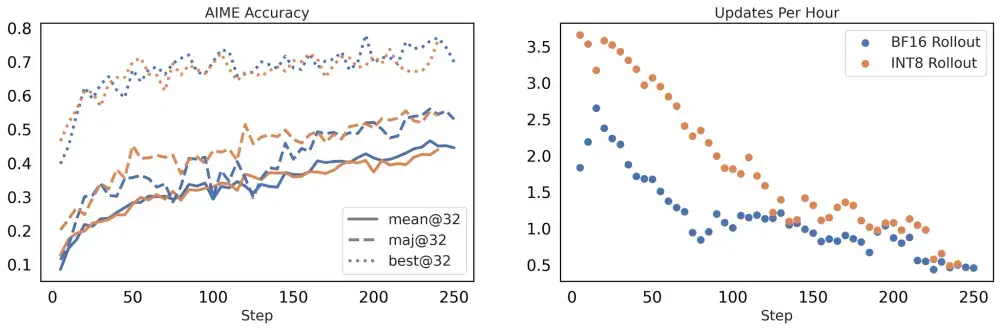
大模型 RL 加速新方案:FlashRL 实现无损量化 rollout在大模型强化学习(RL)训练中,rollout 生成是耗时最长的环节之一。以 DAPO-32B 为例,rollout 阶段占据了约 70% 的总训练时间。这一瓶颈使得整个训练流程效率低下,尤其在大规模...新技术# FlashRL6个月前03550